Elasticsearch聚合查询是一种强大的工具,允许我们对索引中的数据进行复杂的统计分析和计算。本文将详细解释一个聚合查询示例,该查询用于统计满足特定条件的文档数量,并计算其占总文档数量的百分比。这里回会分享如何统计某个字段的空值率,然后扩展介绍ES的一些基础知识。
通过小demo的方式跟大家分享一下我对DDD中战术层级的理解,算是抛砖引玉,该理解仅代表我个人在现阶段的一个理解,也可能未来随着业务经验深入,还会有不同的理解。
最近在对稳健理财BFF层聚合查询服务优化治理,针对文章内的串行改并行章节进行展开,分享下实践经验,主要涉及原同步改异步的过程、全异步化后衍生的问题以及治理方面的思考与改进。
这天,小悦懒洋洋地步入办公楼下的咖啡馆,意外地与一位男子不期而遇。他显然因前一晚的辛勤工作而略显疲惫,却仍选择早到此地,寻找一丝宁静与放松。他叫逸尘,身姿挺拔,衣着简约而不失格调,晨光下更显英俊不凡,吸引了周遭的目光。两人仿佛心有灵犀,不约而同地走向各自的位置。 小悦手中轻握着新出炉的拿铁,眼睛紧紧
前言 SQL语句中,聚合函数在统计业务数据结果时起到了重要作用,比如计算每个业务地区的业务总数、每个班级的学生平均分以及每个分类的最大值等。然而,今天小编将为大家介绍窗口函数,与聚合函数相比,它们也是一组函数,但在使用方法和适用场景上有所不同。在本章节中,我将重点介绍窗口函数中的RANK和DENSE
前言:最近几天有好几个小伙伴玩WPF,遇到不同页面,不知道要怎么传递消息。于是,我今天就来演示一个事件聚合器的玩法,采用prism框架来实现。作为福利,内容附带了主页面打开对话框时候直接通过参数传递消息的一个小例子,具体请自行围观。 以下内容,创建wpf项目以及引用prism和实现依赖注入等细节,可
https://www.jianshu.com/p/dd8587ecf54f 一般而言,在单体结构的操作系统中,一块物理磁盘会接在总线设备上,并经由总线分配 PCI-Bus 号,这个时候一个 bus 往往对应一个真实可见的设备。 但在多主机的集群环境中,多个主机之间使用交换机进行通信,多台存储服务器
前言 在Power BI中,我们经常需要对数据进行聚合计算,比如求和、求平均、求最大值等。 Power BI提供了一系列的聚合函数,可以用来对表中列的值进行聚合然后返回一个值。这些函数通常只需要一个参数,就是要聚合的列名。如SUM(‘销售表’[销量]),就是求销售表里的销量总和。 但是有时候,我们需
摘要:该论文将同一图像不同视角图像块内的语义一致的图像区域视为正样本对,语义不同的图像区域视为负样本对。 本文分享自华为云社区《[NeurIPS 2022]基于语义聚合的对比式自监督学习方法》,作者:Hint 。 1.研究背景 近些年来,利用大规模的强标注数据,深度神经网络在物体识别、物体检测和物体
目录 ElasticSearch 实现分词全文检索 - 概述 ElasticSearch 实现分词全文检索 - ES、Kibana、IK安装 ElasticSearch 实现分词全文检索 - Restful基本操作 ElasticSearch 实现分词全文检索 - Java SpringBoot E
随着使用es场景的增多,工作当中避免不了去使用es进行数据的存储,在数据存储到es当中以后就需要使用DSL语句进行数据的查询、聚合等操作,DSL对SE的意义就像SQL对MySQL一样,学会如何编写查询语句决定了后期是否能完全驾驭ES,所以至关重要,本专题主要是分享常用的DSL语句,拿来即用。
上一篇介绍的**通用计算**是关于多个`numpy`数组的计算, 本篇介绍的**聚合计算**一般是针对单个数据集的各种统计结果,同样,使用**聚合函数**,也可以避免繁琐的循环语句的编写。 # 元素的和 数组中的元素求和也就是合计值。 ## 调用方式 **聚合计算**有两种调用方式,一种是面向对象的
1. 背景 推荐系统的推荐请求追踪日志,通过ELK收集,方便遇到问题时,可以通过唯一标识sid来复现推荐过程 最近在碰到了几个bad case,需要通过sid来查询推荐日志,但发现部分无法在kibana查询到 2. 分析 推荐日志的整个收集流程如下: flowchart LR 线上机器日志 -->
https://www.cnblogs.com/pachongshangdexuebi/p/11507298.html 1、聚合报告添加 聚合报告是常用的监听器之一,添加路径: 点击线程组->添加->监听器->聚合报告 2、聚合报告界面及说明 Label:请求的名称,就是我们在进行测试的httpre
有一个IList()对象列表, 示例数据为[{id:'1',fieldName:'field1',value:'1'},{id:'1',fieldName:'field2',value:'2'},{id:'2',fieldName:'field1',value:'1'},{id:'2',f
之前数据分层处理,最后把轻度聚合的结果保存到 ClickHouse 中,主要的目的就是提供即时的数据查询、统计、分析服务。这些统计服务一般会用两种形式展现,一种是为专业的数据分析人员的 BI 工具,一种是面向非专业人员的更加直观的数据大屏。 以下主要是面向百度的 sugar 的数据大屏服务的接口开发
[TOC] 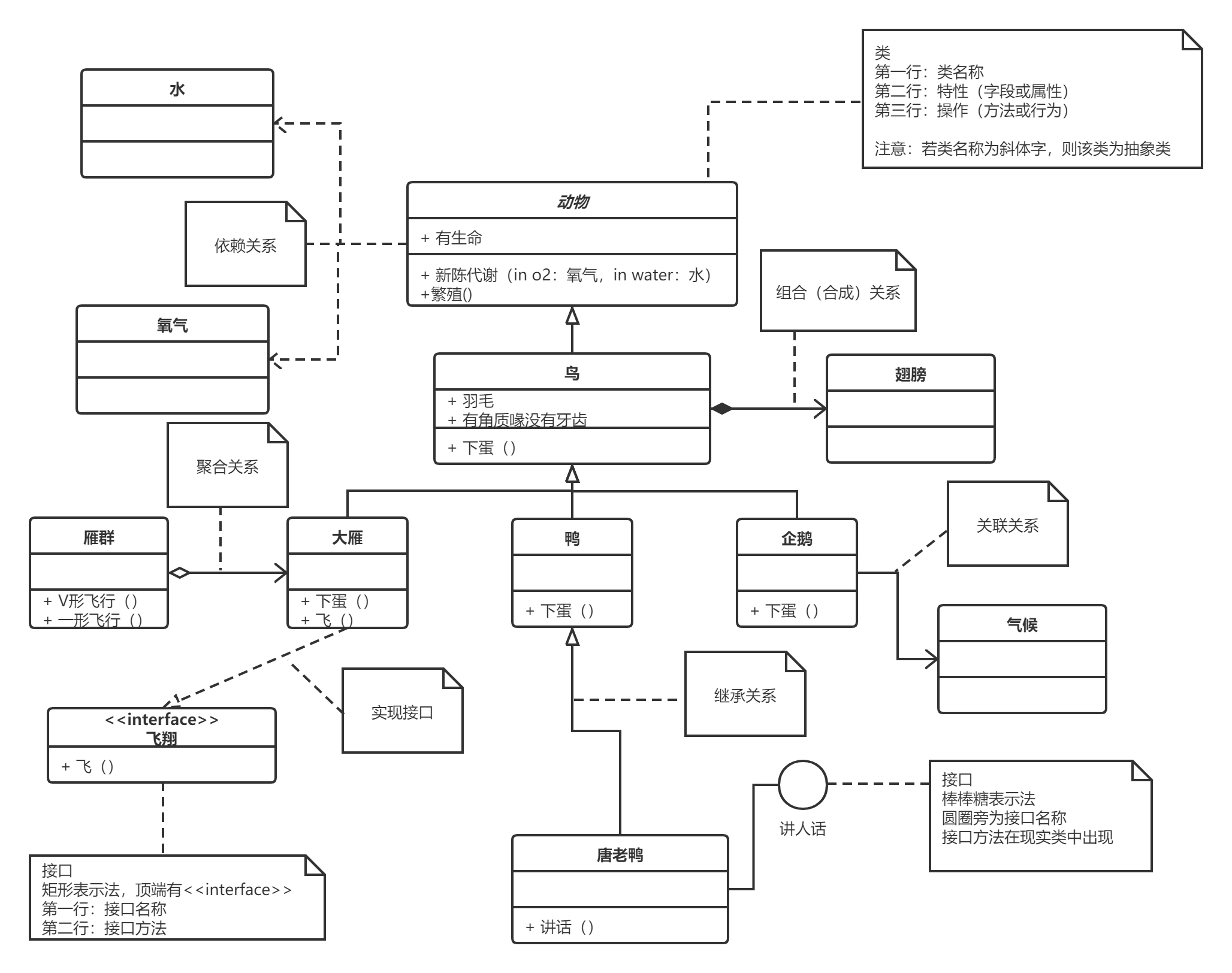 ## 类的表示(Class) 第一层:显示类的名称,如果是抽象类,则就用斜体显示。 第二层:是类的
本文分享自华为云社区《2个RoCE网卡Bond聚合,实现带宽X2》,作者: tsjsdbd 。 我们知道操作系统里面,可以将2个实际的物理网卡,合体形成一个“逻辑网卡”,从而达到如主备/提升带宽等目的。但是RoCE网卡,是否也跟普通网卡一样,支持Bond能力呢?答案是的,RoCE也可以组Bond,只
本文属于OData系列 Introduction ODATA v4提出了新的聚合查询功能,这对于ODATA的基本查询能力($expand等)是一个非常大的补充。ODATA支持的聚合查询功能,可以对数据进行统计分析,例如求和、平均值、最大/最小值、分组等。 聚合查询是通过$apply关键字实现的。使用
定义 迭代器模式提供一种方法按顺序访问一个聚合对象中的各个元素,而又不暴露该对象的内部表示。迭代器模式是目的性极强的模式,它主要是用来解决遍历问题。 es6 中的迭代器 JS原生的集合类型数据结构,有Array(数组)和Object(对象),在ES6中,又新增了Map和Set。四种数据结构各自有着自