Jerry 是一家位于北美的科技公司,利用人工智能和机器学习技术,简化汽车保险和贷款的比价和购买流程。在美国,Jerry 的应用在其所属领域排名第一。 随着数据规模的增长,Jerry 在使用 AWS Redshift 时遇到了一些性能与成本的挑战。Jerry 重新设计了系统架构,使用 ClickHo
1.概述 在Clickhouse中有多种表引擎,不同的表引擎拥有不同的功能,它直接决定了数据如何读写、是否能够并发读写、是否支持索引、数据是否可备份等等。本篇博客笔者将为大家介绍Clickhouse中的各个表引擎以及其含义。 2.内容 2.1 MergeTree 适用于高负载任务的最通用和功能最强大
[toc] ## 前言 * 使用Clion的时候,可以自动格式化代码的操作. ## 使用外部工具Artistic Style | 序号 | 名称 | 地址 | | | | | | 1 | Artistic Style | [https://sourceforge.net/projects/astyl
[TOC] ## 下载插件C/C++ Single File Execution 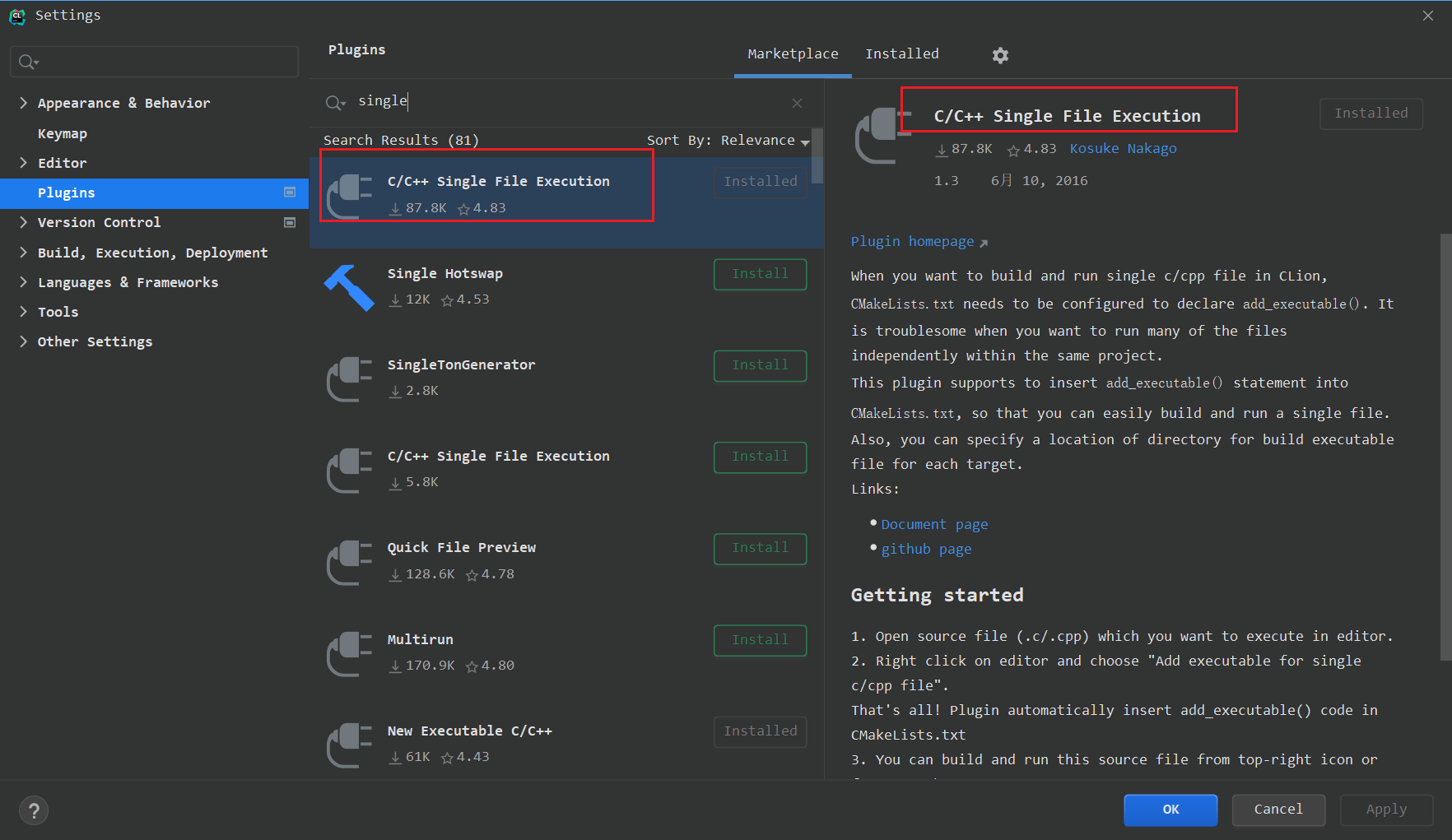 ## 项目操作 * 1.新建项目-
[TOC] ## 搜素位置  领域。目前国内社区火热,各个大厂纷纷跟进大规模使用: 今日头条 内部用ClickHouse
目录 异常现象: 1. clickhouse的异常日志 2. 追踪对应节点的zookeeper日志 使用clickhouse-keeper代替 zookeeper的步骤: 1: 准备 clickhouse-keeper的配置文件 1.1- 设置通信地址,以便对外通信 1.2- 在config.xml
# Clickhouse 极简单机版本安装部署 ## 摘要 ``` Clickhouse的安装与部署其实比较简单. 但是为了能够更加简单的部署与使用. 尤其是能够可以方便的添加到镜像内进行运行. 所以记录一下方便快捷的处理方式. ``` ## 下载与使用的坑 ``` 1. 最新版本的 clickho
# Clickhouse的极简安装-之二(macos+linux) ## StudyFrom ``` https://clickhouse.com/docs/en/install 然后简单的获取方式: curl https://clickhouse.com/ > ck.url 其实可以看到他的安装命
一、风险洞察平台介绍 以Clickhouse+Flink实时计算+智能算法为核心架构搭建的风险洞察平台, 建立了全面的、多层次的、立体的风险业务监控体系,已支撑欺诈风险、信用风险、企业风险、小微风险、洗钱风险、贷后催收等十余个风控核心场景的实时风险监测与风险预警,异常检测算法及时发现指标异常波动,基
作者:耿宏宇 1 表引擎简述 1.1 官方描述 MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。 ReplacingMergeTr
clickhouse 的原生 rust 客户端目前比较好的有两个clickhouse-rs 和 clickhouse.rs 。两个库在单独使用时没有任何问题,但是,在同一工程同时引用时会报错。本篇内容主要讲解如何用rust语言解决本地库引发的依赖冲突问题
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。我们内部很多的报表、数据看板都基于它进行开发。今天为大家带来remote方式的ClickHouse数据表迁移的完整过程介绍,如有错误,还请各位大佬指正。
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 时隔两年,《client-go实战》被激活,更多内容将会继续更新 时间过得真快,《client-go实战》系列已是两年前的作品,近期工作中再次用到clie
本文对Clickhouse架构原理、语法、性能特点做一定研究,同时将其与mysql、elasticsearch、tidb做横向对比,并重点分析与mysql的语法差异,为有mysql迁移clickhouse场景需求的技术预研及参考。
为了保证统计数据的准确性,比如订单金额,一个常用的方法是在查询时增加final关键字。那final关键字是如何合并数据的,以及合并的数据范围是怎样的,本文就对此做一个简单的探索。
前言 经过『手撕Vue-CLI』自动安装依赖,已经实现了自动安装依赖的功能。 然而,虽然项目已复制并安装依赖,但其提示信息并不够友好,于是我试着去运行了一下vue create,发现其提示信息是这样的: 于是我决定完善提示信息,也借此机会完善一下项目的代码,变量命名等。 完善提示信息 完善变量命名
开篇 经过『手撕Vue-CLI』拷贝模板,实现了自动下载并复制指定模板到目标目录。然而,虽然项目已复制,但其依赖并未自动安装,可能需要用户手动操作,这并不够智能。 正如前文所述,我们已经了解了业务需求和背景。那么,接下来我们将直接深入探讨核心实现细节。 自动安装依赖 在前文中,我们已经将模板文件复制