本文翻译自国外论坛 medium,原文地址:https://levelup.gitconnected.com/4-reasons-why-single-threaded-redis-is-so-fast-414e0106f921
作为内存数据存储,Redis 以其速度和性能而闻名,通常被用作大多数后端服务的缓存解决方案。
然而,在 Redis 内部采用的也只是单线程的设计。
为什么 Redis 单线程设计会带来如此高的性能?如果利用多个线程并发处理请求不是更好吗?
在本文中,我们将探讨使 Redis 成为快速高效的数据存储的设计选择。
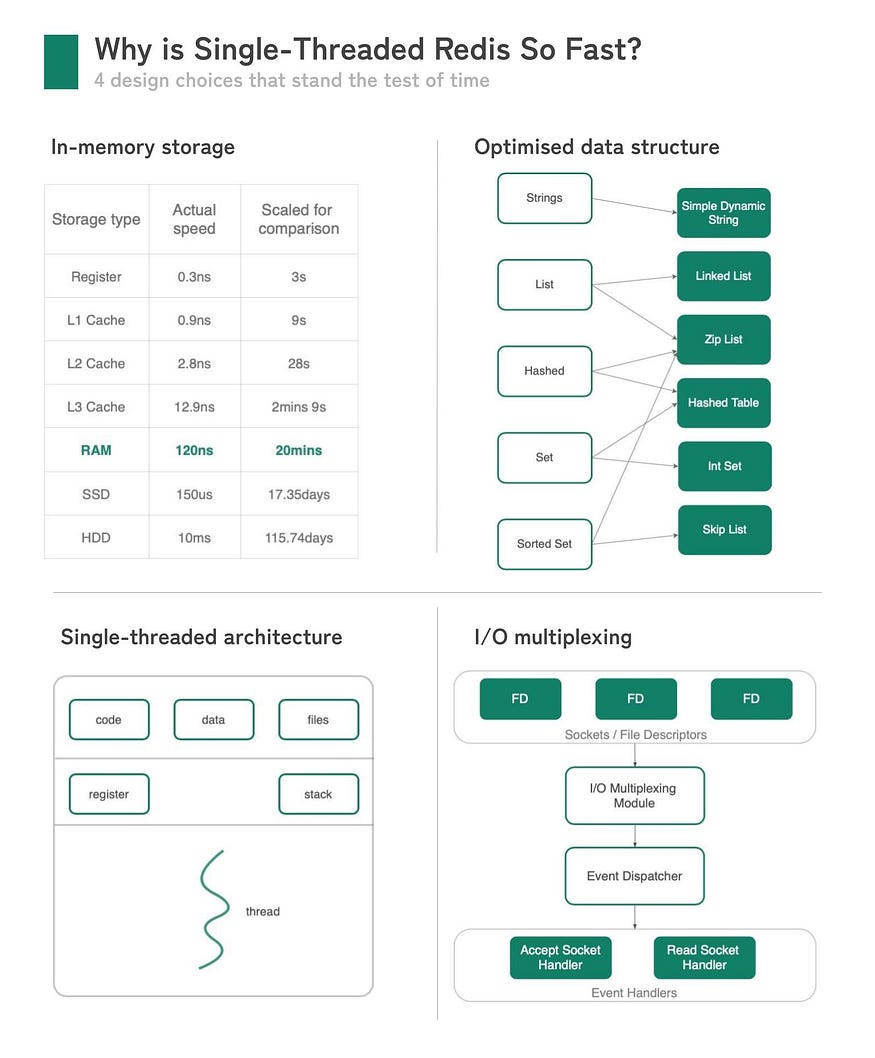
Redis 的性能可归因于 4 个主要因素
让我们一一剖析一下。
推荐博主开源的 H5 商城项目waynboot-mall,这是一套全部开源的微商城项目,包含三个项目:运营后台、H5 商城前台和服务端接口。实现了商城所需的首页展示、商品分类、商品详情、商品 sku、分词搜索、购物车、结算下单、支付宝/微信支付、收单评论以及完善的后台管理等一系列功能。 技术上基于最新得 Springboot3.0、jdk17,整合了 MySql、Redis、RabbitMQ、ElasticSearch 等常用中间件。分模块设计、简洁易维护,欢迎大家点个 star、关注博主。
github 地址:https://github.com/wayn111/waynboot-mall
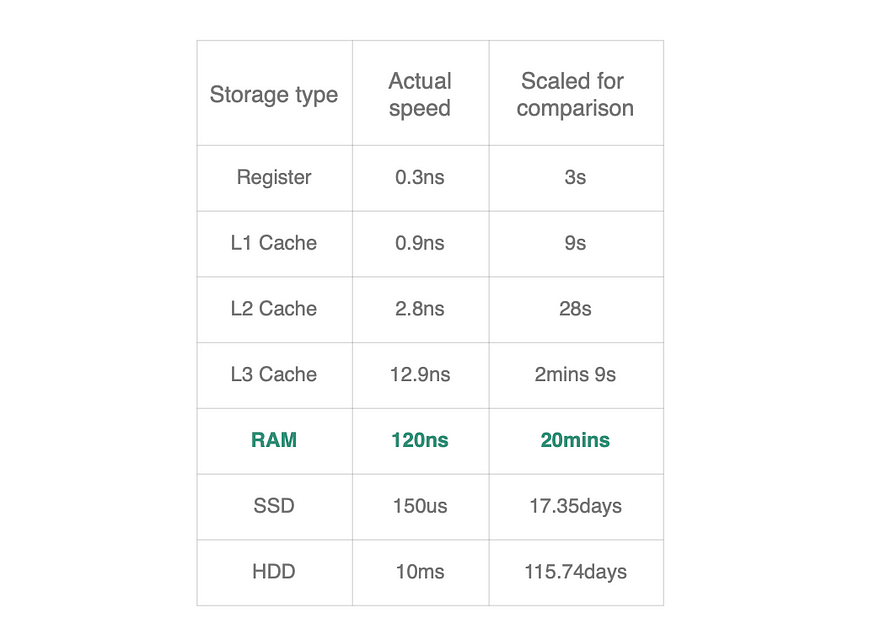
Redis 是在内存中进行键值存储。
Redis 中的每次读写操作都相当于从内存的变量中进行读写。
访问内存比直接访问磁盘快几个数量级,因此Redis 比其他数据存储快得多。
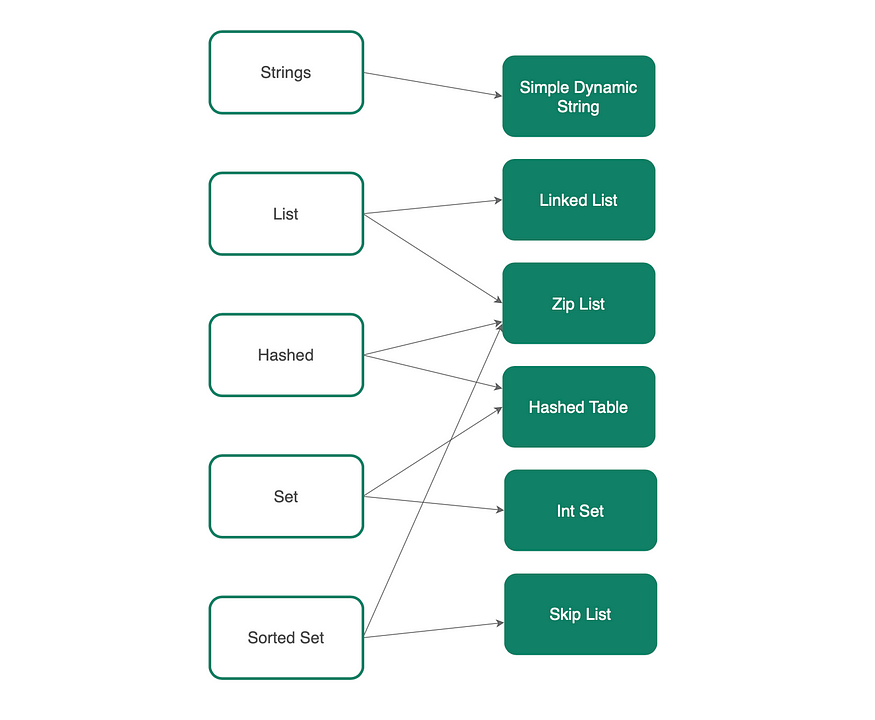
作为内存数据存储,Redis 利用各种底层数据结构来高效存储数据,无需担心如何将它们持久化到持久存储中。
例如,Redis list 是使用链表实现的,它允许在列表的头部和尾部附近进行恒定时间 O(1) 插入和删除。
另一方面,Redis sorted set 是通过跳跃列表实现的,可以实现更快的查询和插入。
简而言之,无需担心数据持久化,Redis 中的数据可以更高效地存储,以便通过不同的数据结构进行快速检索。
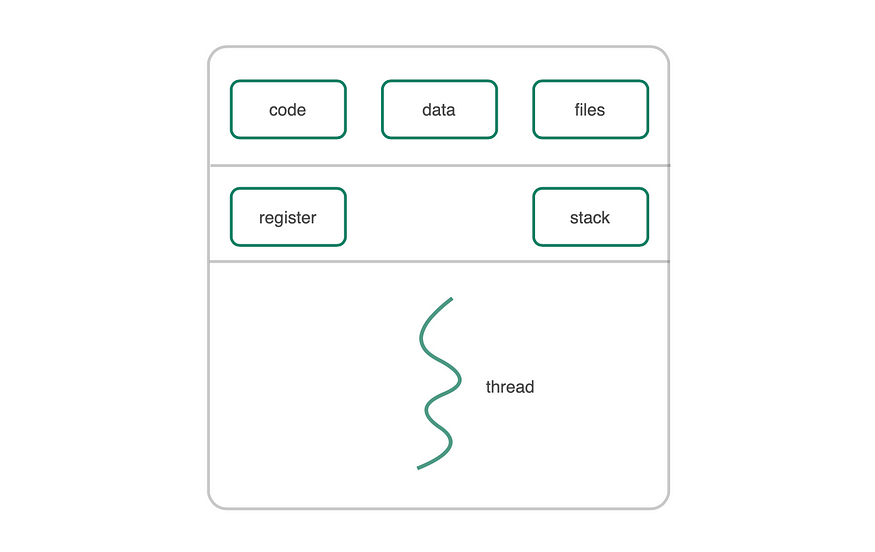
Redis 中的写入和读取速度非常快,并且 CPU 使用率从来不是 Redis 关心的问题。
根据 Redis 官方文档,在普通 Linux 系统上运行时,Redis 每秒最多可以处理 100 万个请求。
通常瓶颈来自于网络 I/O, Redis 中的处理时间大部分浪费在等待网络 I/O 上。
虽然多线程架构允许应用程序通过上下文切换并发处理任务,但这对 Redis 的性能增益很小,因为大多数线程最终会在 I/O 中被阻塞。
所以 Redis 采用单线程架构,有如下好处
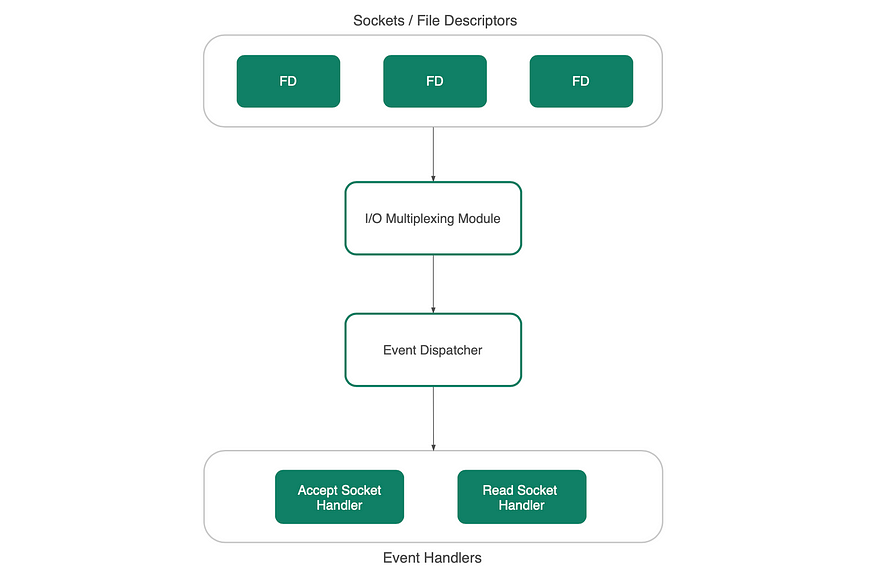
为了处理传入的请求,服务器需要在套接字上执行系统调用,以将数据从网络缓冲区读取到用户空间。
这通常是阻塞操作,线程被阻塞并且在完全接收到来自客户端的数据之前不能执行任何操作。
为什么我们不能在只有确定套接字中的数据已准备好读取时,才执行系统调用嘞?
这就是 I/O 多路复用发挥作用的地方。
I/O 多路复用模块同时监视多个套接字,并且仅返回可读的套接字。
准备读取的套接字被推送到单线程事件循环,并由相应的处理程序使用响应式模型进行处理。
总之,
所以 Redis 做出了以下决定,
综上所述,单线程架构是 Redis 团队经过深思熟虑的选择,并且经受住了时间的考验。
尽管是单线程,Redis 仍然是性能最高、最常用的内存数据存储之一。
关注公众号【waynblog】每周分享技术干货、开源项目、实战经验、高效开发工具等,您的关注将是我的更新动力!