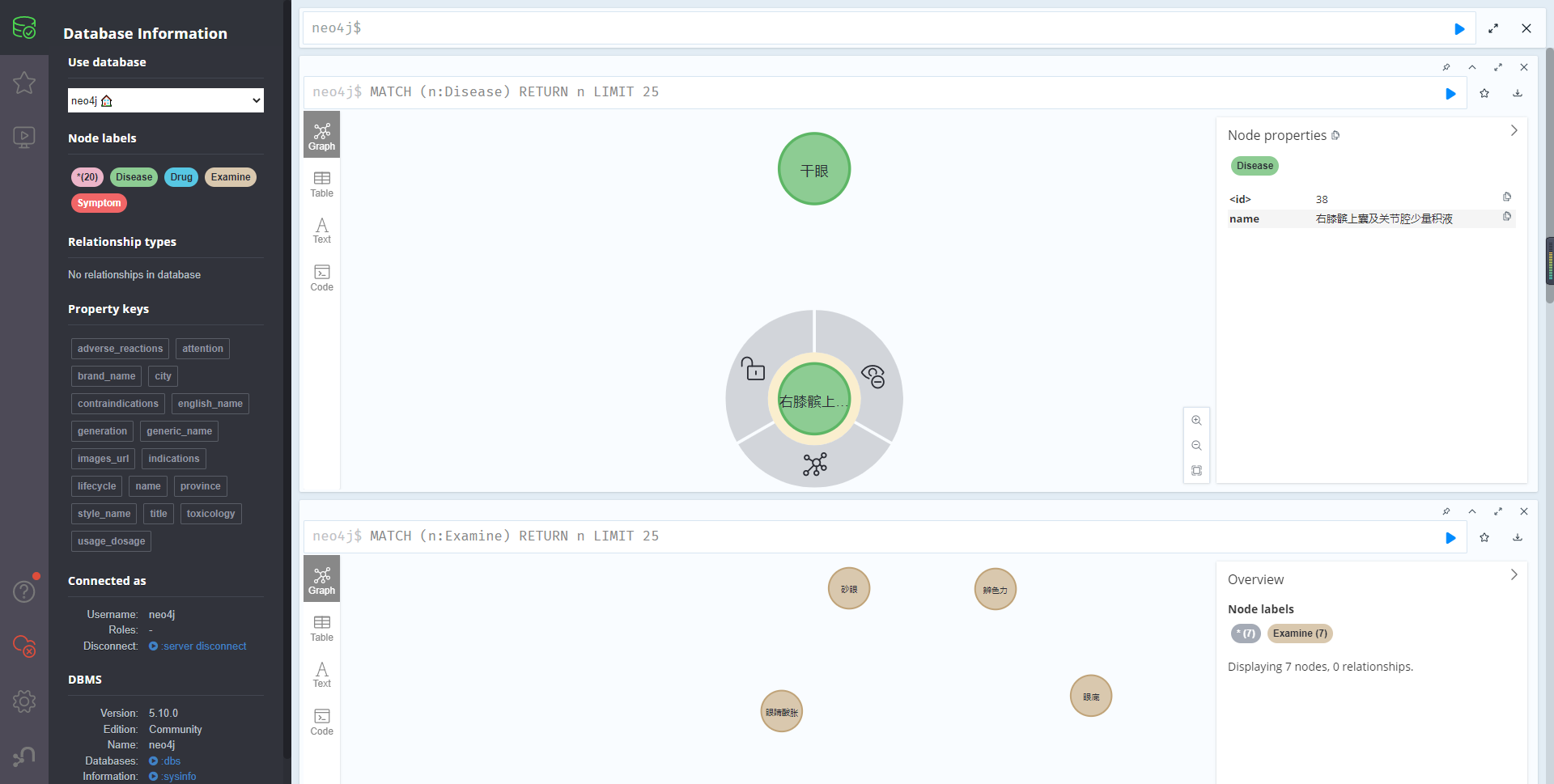
disease_data.csv
建议值用“”引起来。避免中间有,号造成误识别
疾病 "干眼" "右膝髌上囊及关节腔少量积液"复制
import logging
import pandas as pd
from utils.neo4j_provider import driver
logging.root.setLevel(logging.INFO)
# 并生成 CQL
def generate_cql() -> str:
# cql = """
# CREATE (disease1:Disease {name: "右膝髌上囊及关节腔少量积液"}),
# (disease2:Disease {name: "干眼"}),
# """
df = pd.read_csv('disease_data.csv')
symptoms = []
for each in df['疾病']:
symptoms.extend(each.split(',')) # 按,号分割成数组,并将每行数据到一个队列里面
symptoms = set(symptoms) # 去除重复项
# 拼接 CQL
cql = ""
for idx, item in enumerate(symptoms):
cql += """(disease%s:Disease {name: "%s"}),\r\n""" \
% (idx, item)
return "CREATE %s" % (cql.rstrip(",\r\n")) # 删除最后一个节点的 逗号
# 执行写的命令
def execute_write(cql):
with driver.session() as session:
session.execute_write(execute_cql, cql)
driver.close()
# 执行 CQL 语句
def execute_cql(tx, cql):
tx.run(cql)
# 清除 Disease 标签数据
def clear_data():
cql = "MATCH (n:Disease) DETACH DELETE n"
execute_write(cql)
if __name__ == "__main__":
clear_data()
cql = generate_cql()
print(cql)
execute_write(cql)
复制