摘要:AI Benchmark旨在衡量AI模型的性能和效能。
本文分享自华为云社区《KubeEdge SIG AI发布首个分布式协同AI Benchmark调研》,作者:KubeEdge SIG AI (成员:张扬,张子阳)。
人工智能技术已经在我们生活中的方方面面为我们提供服务,尤其是在图像、视频、语音、推荐系统等方面带来了突破性成果。AI Benchmark旨在衡量AI模型的性能和效能。KubeEdge SIG AI成员张扬和张子阳博士就AI Benchmark的困难与挑战,以及新兴的边缘计算领域的分布式协同AI Benchmark发展现状进行了分析总结。
深度学习技术可以利用有限的数据逼近高维函数。但我们仍未掌握模型参数、系统配置对机器学习、深度学习算法的学习动态的影响。目前AI Benchmark领域的困难与挑战总结如下:
1. 学习动态难解释:深度学习技术一定程度上是一个高维非凸优化问题,细微的变化会导致不同的优化路径,严重依赖参数调整的经验。
2. 成本高昂:在我们开启一次训练之后,我们必须完整的跑完整个训练过程。完整训练一次GPT-3模型的成本约7500万人民币。
3. 指标问题:在时间质量(Time to Quality, TTQ)指标上,时间质量严重依赖超参数的调整,同时需要解耦架构、系统和算法评估模块;在每秒浮点运算次数(floating-point operations per second, FLOPS)上,有半精度浮点、单精度浮点、双精度浮点、多精度浮点、混合浮点等浮点类型。
4. 需求冲突:主要问题为1.组件基准(component benchmarks)无法在模拟器上运行,2.微基准(Micro benchmarks)可负担,但不能模拟学习动态。
5. 有效期问题:人工智能模型的演变和变化往往会超过人工智能基准。
6. 可拓展性问题:AI问题的规模是固定的,不可拓展。
7. 可重复性问题:基准测试要求测试是可复现的,神经网络的随机性会影响基准测试的复现性。神经网络中的随机性包括:随机种子、模型初始化、数据增强、数据Shuffle、Dropout等等。
随着边侧算力逐步强化,时代也正在见证边缘AI往分布式协同AI的持续演变。分布式协同AI技术是指基于边缘设备、边缘服务器、云服务器利用多节点分布式乃至多节点协同方式实现人工智能系统的技术。除了以上问题外,如果考虑到分布式协同AI,还存在如边侧算力不足、云边网络不稳定、数据孤岛等实际的约束和限制问题。
本章节首先总结当前学界与业界的分布式协同AI Benchmark,接下来对各个Benchmark展开简单描述。
Bench Council发布的AIoT Bench是一个基准套件,AIoTBench专注于评估移动和嵌入式设备的推理能力,包含三个典型的重量级网络:ResNet50、InceptionV3、DenseNet121以及三个轻量级网络:SqueezeNet、MobileNetV2、MnasNet。每个模型都由三个流行的框架实现:Tensorflow Lite、Caffe2、Pytorch Mobile。对于Tensorflow Lite中的每个模型,还提供了三个量化版本:动态范围量化(dynamic range quantization)、全整数量化(full integer quantization)、float16量化(float16 quantization)。

图 1 AIotBench中使用模型的FLOPs、Parameters和准确率
在框架的选择上,AIoTBench支持了三个流行和具有代表性的框架:Tensorflow Lite、Caffe2、Pytorch Mobile。
最后,在指标上,AIoTBench通过VIPS(Valid Images Per Second, 每秒有效图像)来反映得分。
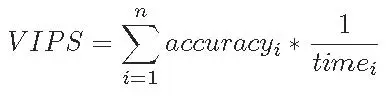
图 2 AIotBench中VIPS计算
目前,Bench Council已经发布了Android版本的AIoTBench,它包含四个模块:
1. 配置模块:用户可以配置模型文件的路径和数据集的路径。预处理参数由文件配置。我们在默认路径中提供了数据集、准备的模型和相应的预处理配置。添加新型号很方便。用户只需要i)准备模型文件并放入模型路径,ii)在配置文件中添加该模型的预处理设置。
2. 预处理模块:读取和预处理图像。
3. 预测模块:由于不同的框架有不同的推理API,AIoT Bench抽象了两个接口,并为三个框架实现它们:Tensorflow Lite、Caffe2、Pytorch Mobile。prepare()接口负责加载和初始化模型,infer()接口负责执行模型推理。当用户需要添加新的框架时,只需要根据新框架实现对应的两个API接口即可。
4. 评分模块:记录每次测试的准确性和推断时间,并计算最终的AI基准测试分数。
AI Bench是Bench Council在2018年提出的适用于数据中心、HPC、边缘和 AIoT 的综合 AI 基准测试套件,提出了一种场景提取的基准测试方法论和企业级AI基准测试框架和套件。测试数据源有公共开源数据集和经过保密脱敏处理的合作机构的数据集。
AI Bench框架分为数据输入、AI问题域、离线训练、在线推理四个部分。
• 数据输入(data input)模块:负责将数据输入其他模块,支持结构化、半机构化、非结构化数据,例如表格、图形、文本、图像、音频、视频等等。同时,数据输入模块集成了各种开源数据存储系统,支持大规模数据生成和部署。
• AI问题域:AI Bench确定了最重要的AI问题领域,针对这些领域的AI算法的具体实现作为组件基准(component benchmarks)。并对组件基准中最密集的计算单元实现为一组微基准(micro benchmarks)。组件基准和微基准可以自由组合,每个基准也都可以独立运行。
• 离线训练(offline training)和在线推理(online inference)模块:构建端到端(End-to-End)的应用程序基准。首先,离线训练模块通过指定所需的基准ID、输入数据和批量大小等执行参数,从AI问题域模块中选择一个或多个组件基准。然后离线训练模块训练一个模型并将训练好的模型提供给在线推理模块。在线推理模块将训练好的模型加载到推理服务中,与关键路径中的其他非AI模块协作,构建端到端应用程序基准。
为了在大规模集群上轻松部署,框架提供了部署工具,提供了Ansible和Kuberneres的两个自动化部署模板。Ansible主要提供的是在物理机或者虚拟机上的1+N复制模式,Kubernetes需要提前构件好集群,在Master节点上通过配置文件将配置下发至各个节点从而完成部署。
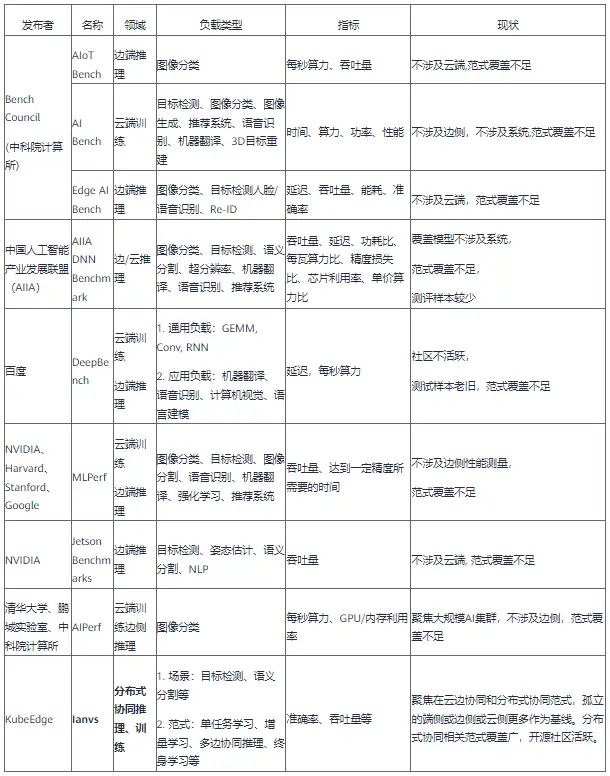
Edge AI Bench是一个基于场景的基准套件,是AI Bench场景基准的一部分,设置了4个典型的边缘AI场景:自动驾驶、ICU患者监视器、智能家居、智能家居。Edge AI Bench提供了一个端到端的应用程序基准框架,包括训练、验证和推理阶段。
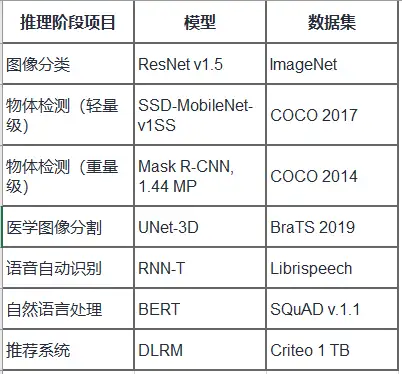
Edge AI Bench涵盖的场景、模型、数据集情况如下表所示。
AIIA DNN benchmark项目由中国人工智能产业发展联盟计算架构与芯片推进组发起。AIIA DNN benchmark项目是用于测试具有机器学习处理能力的加速器或处理器硬件、软件以及服务的训练和推理性能的开源基准平台。它能帮助人工智能研究人员采用通用标准来衡量用于训练或推理任务的人工智能硬件、软件的最佳性能。旨在客观反映当前以提升深度学习处理能力的 AI 加速器现状,为芯片企业提供第三方评测结果,帮助产品市场宣传;同时为应用企业提供选型参考,帮助产品找到合适其应用场景的芯片。
AIIA DNN benchmark系统架构如下:

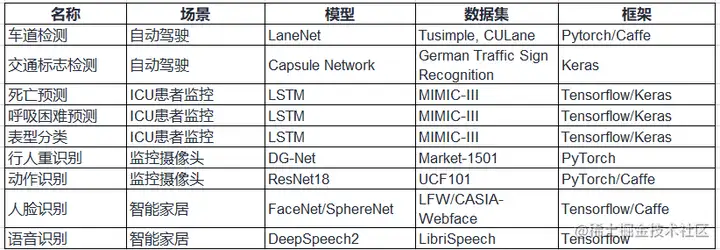
AIIA DNN benchmark依据行业应用,区分垂直应用场景对深度神经网络加速器/处理器展开基于真实应用场景的基准测试工作。

AIIA DNN benchmark评测场景与指标如下:
DeepBench 的主要目的是在不同硬件平台上对深度学习很重要的操作进行基准测试。尽管深度学习背后的基本计算很容易理解,但它们在实践中的使用方式却出奇的多样化。例如,矩阵乘法可能是计算受限的、带宽受限的或占用受限的,这取决于被相乘的矩阵的大小和内核实现。由于每个深度学习模型都使用这些具有不同参数的操作,因此针对深度学习的硬件和软件的优化空间很大且未指定。
DeepBench直接使用神经网络库(cuDNN, MKL)对不同硬件上基本操作的性能进行基准测试。它不适用于为应用程序构建的深度学习框架或深度学习模型。
DeepBench 由一组基本操作(密集矩阵乘法GEMM、卷积Conv)以及一些循环神经网络RNN类型组成。DeepBench的测试包括七个硬件平台的训练结果,NVIDIA 的 TitanX、M40、TitanX Pascal、TitanXp、1080 Ti、P100 和英特尔的 Knights Landing。推理结果包括三个服务器平台,NVIDIA 的 TitanX Pascal、TitanXp 和 1080 Ti。三款移动设备 iPhone 6 和 7、RaspBerry Pi 3 的推理结果也包括在内。
DeepBench提供多种芯片的测试方法,共有以下5种类型:
1. NVIDIA Benchmarks:需指定MPI_PATH、CUDA_PATH、CUDNN_PATH、NCCL_PATH、GPU数量、精度类型等,通过编译后,可以运行基准测试。
2. Baidu Benchmarks:需指定MPI_PATH、CUDA_PATH、BAIDU_ALLREDUCE_PATH、GPU数量等参数,之后使用mpirun运行Baidu All-Reduce基准测试。
3. Intel Benchmarks:需要指定Intel工具icc、mkl、mpi路径,可以进行GEMM、Conv、ALL-Reduce等基准测试。
4. ARM Benchmarks:需要在64位ARM v8处理器上编译和运行ARM Benchmarks,可以进行GEMM、Conv、稀疏GEMM基准测试。
5. AMD Benchmarks:需要支持ROCm的平台、rocBLAS、MIOpen等组件,可以进行Conv、RNN、GEMM基准测试。
MLPerf是一个由来自学术界、研究实验室和行业的人工智能领导者组成的联盟。
MLPerf的训练测试由八个不同的工作负载组成,涵盖了各种各样的用例,包括视觉、语言、推荐和强化学习。

MLPerf推理测试七种不同神经网络的七个不同用例。其中三个用例用于计算机视觉,一个用于推荐系统,两个用于自然语言处理,一个用于医学成像。
Jetson Benchmarks是通过高性能推理将各种流行的DNN模型和ML框架部署到边缘侧Jetson设备中,以实时分类和对象检测、姿势估计、语义分割和自然语言处理(NLP)等任务作为工作负载,检测边缘侧Jetson设备性能的基准测试工具。
针对各类Jetson设备,Jetson Benchmarks的脚本会自动运行如下配置的基准测试,并得到测试结果(FPS)
• Names : Input Image Resolution
• Inception V4 : 299x299
• ResNet-50 : 224x224
• OpenPose : 256x456
• VGG-19 : 224x224
• YOLO-V3 : 608x608
• Super Resolution : 481x321
AIPerf Benchmark由鹏城实验室、清华大学等团队联合提出。AIPerf Benchmark基于微软NNI开源框架,以自动化机器学习(AutoML)为负载,使用network morphism进行网络结构搜索和TPE进行超参搜索。
AIPerf官方提供四种数据集: Flowers、CIFAR-10、MNIST、ImageNet-2012 前三个数据集数据量小,直接调用相关脚本自动会完成下载、转换(TFRecord格式)的过程。
AIPerf为了保证基准测试结果有效,要求测试需要满足如下条件:
1. 测试运行时间应不少于1小时;
2. 测试的计算精度不低于FP-16;
3. 测试完成时所取得的最高正确率应大于70%;
AIPerf的工作流如下:
1. 用户通过SSH登陆主节点,收集集群内Replica nodes的信息并创建SLURM配置脚本
2. 主节点通过SLURM将工作负载分派到对应于请求和可用资源的Replica nodes中,分发的过程是并行且异步的
3. 各个Replica nodes接收工作负载并执行架构搜索和模型训练
4. Replica nodes上的CPU根据当前历史模型列表搜索新架构,其中包含详细的模型信息和测试数据集的准确性,然后将候选架构存储在缓冲区(如NFS)中以供后续训练
5. Replica nodes上的AI加速器加载候选架构和数据集,利用数据并行性和HPO一起训练,然后将结果存储在历史模型列表中
6. 一旦满足条件(如达到用户定义的时间),运行终止,根据记录的指标计算最终结果后得出基准测试报告

图 3 AIPerf工作流示意图
Ianvs是KubeEdge SIG AI孵化的开源分布式协同AI基准测试套件,帮助算法开发者快速测试分布式协同AI算法性能,促进更高效更有效的开发。借助单机就可以完成分布式协同AI前期研发工作。项目地址:https://github.com/kubeedge/ianvs
Ianvs项目包括如下内容:
• 基于典型的分布式协同AI范式和应用,提供跨设备、边缘节点、云节点的端到端基准测试套件。
• 与其他组织和社区合作,例如在Kubeedge SIG AI中,建立全面的基准并开发相应的应用,包括但不限于如下内容:
Ianvs的目标用户包括分布式协同AI算法开发者和终端用户。算法开发者可以借助Ianvs高效地构建和发布分布式协同AI解决方案;终端用户则可以借助Ianvs快速分析比较各分布式协同AI方案的效能。
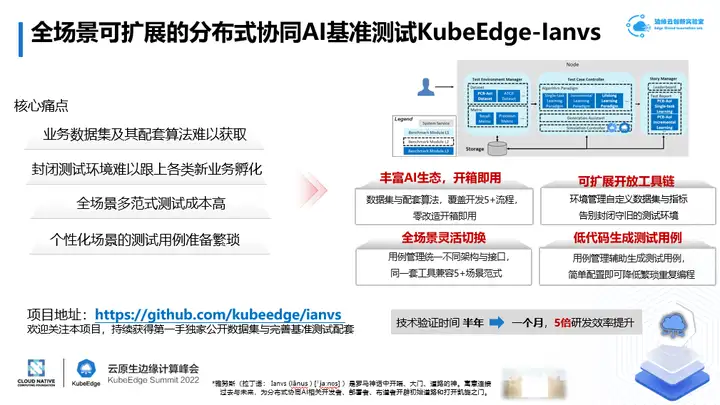
1、 针对业务数据集难以获取,数据采集与处理成本高的痛点,ianvs提供丰富AI生态,做到开箱即用。ianvs开源数据集与5+配套算法,覆盖预处理、预训练、训练、推理、后处理全流程,零改造开箱即用。
2、 针对封闭测试环境难以跟上各类新业务孵化的痛点,ianvs提供可扩展开放工具链。测试环境管理实现自定义动态配置测试数据集、测试指标,告别封闭守旧的测试环境。
3、 针对全场景多范式测试成本高的痛点,ianvs提供全场景灵活切换。ianvs测试用例管理统一不同场景及其AI算法架构与接口,能够用一套工具同时兼容多种AI范式。
4、 针对个性化场景的测试用例准备繁琐的痛点,ianvs提供低代码生成测试用例。ianvs测试用例管理基于网格搜索等辅助生成测试用例,比如一个配置文件即可实现多个超参测试,降低超参搜索时的繁琐重复编程。
Ianvs同步发布一个新的工业质检数据集PCB-AoI。PCB-AoI 数据集是首个面向印刷电路板AoI焊点表面缺陷的开源数据集,是开源分布式协同 AI 基准测试项目 KubeEdge-Ianvs 的一部分。工作组将PCB-AoI 公共数据集同时也放在 Kaggle和云服务上方便开发者下载。

PCB-AoI数据集由KubeEdge SIG AI 来自中国电信和瑞斯康达的成员发布。在这个数据集中,收集了 230 多个板,图像数量增加到 1200 多个。具体来说,数据集包括两部分,即训练集和测试集。训练集包括 173 个板,而测试集包括 60 个板。也就是说,就 PCB 板而言,train-test 比率约为 3:1。进行了数据增强,将图像方面的训练测试比率提高到 1211:60(约 20:1)。 train_data 和 test_data 的两个目录都包含索引文件,用于关联原始图像和注释标签。
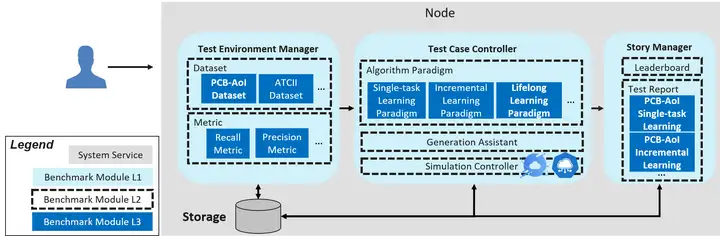
Ianvs只需一台机器即可运行,架构图如上图所示,关键组件包括:
• Test Environment Manager:为全局使用服务的测试环境的CRUD
• Test Case Controller:管理控制各个Test Case运行时的行为,比如生成和删除实例
• Story Manager:测试用例的输出管理和展示,包括排行榜和测试报告生成
KubeEdge-Ianvs项目规划路标如下图:
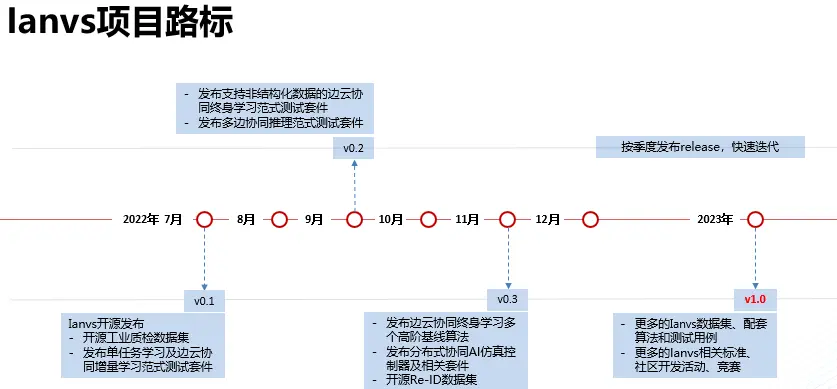
也欢迎关注Ianvs项目,持续获得第一手独家公开数据集与完善基准测试配套。社区也持续募集在Ianvs项目上的合作伙伴,共同孵化开源项目、研究报告及行业标准等。开源项目GitHub地址:https://github.com/kubeedge/ianvs
AIoT Bench https://www.benchcouncil.org/aibench/aiotbench/index.html
AI Bench https://www.benchcouncil.org/aibench/index.html
Edge AI Bench http://www.benchcouncil.org/aibench/edge-aibench/index.html
AIIA DNN Benchmark http://aiiaorg.cn/benchmark/zh/index.html
DeepBench https://github.com/baidu-research/DeepBench
MLPerf https://www.nvidia.com/en-us/data-center/resources/mlperf-benchmarks/
Jetson Benchmarks https://developer.nvidia.com/embedded/jetson-benchmarks
AIPerf https://github.com/AI-HPC-Research-Team/AIPerf
Kubeedge-Ianvs https://ianvs.readthedocs.io/en/latest/index.html
文探讨了边缘智能应用在开放世界问题中的挑战和解决方案,重点介绍了KubeEdge SIG AI发布的KubeEdge Sedna v0.6 及 Ianvs v0.2。