摘要:随着offset的增加,查询的时长也会越来越长。当offset达到百万级别的时候查询时长通常是业务所不能容忍的。
本文分享自华为云社区《offset新探索:双管齐下,加速大数据量查询》,作者: GaussDB 数据库 。
众所周知,在各类业务中时常会用到LIMIT y offset x来做跳过x条数据读取Y条数据的操作。例如:SELECT * FROM ... LIMIT 1000 OFFSET 1000000; 表示从第1000001条数据开始查,读取1000条数据。随着offset的增加,查询的时长也会越来越长。当offset达到百万级别的时候查询时长通常是业务所不能容忍的。
那么如何来提升offset在大数据量查询时的性能、缩短执行时间呢?我们的答案是:
这是华为云GaussDB for MySQL推出的两个新特性,通过OP和RCR的结合,将大数据量查询的性能提升一到两个数量级。
下面我们分别介绍这两个特性的基本原理、如何启用、执行验证、以及通过严密测试来验证其带来的性能提升。
OP赋予MySQL存储引擎InnoDB处理offset 的能力。当OP启用时,在SQL层评估offset 是否可以下推并将下推信息传递给存储引擎。SQL层不再对存储引擎返回的行进行offset 处理,取而代之的是存储引擎层直接跳过offset 范围内的行,仅返回后续行,即查询所需要的行。
通过启用OP,offset 范围内的行不会再传输到SQL层,从而节省了存储引擎和SQL层之间多次来回交互时间;其次,对非覆盖索引扫描(non-covering index,即查询访问二级索引之后还必须访问基表),直接跳过offset范围内的行可以节省对这些行回表访问的开销。这种对offset 的提前处理可以节省数据处理时间,特别是当offset 非常大时。OP的适用性取决于WHERE子句是否可以由存储引擎整体处理。
下方图1和图2分别说明了在没有OP和启用OP时LIMIT offset的处理逻辑。
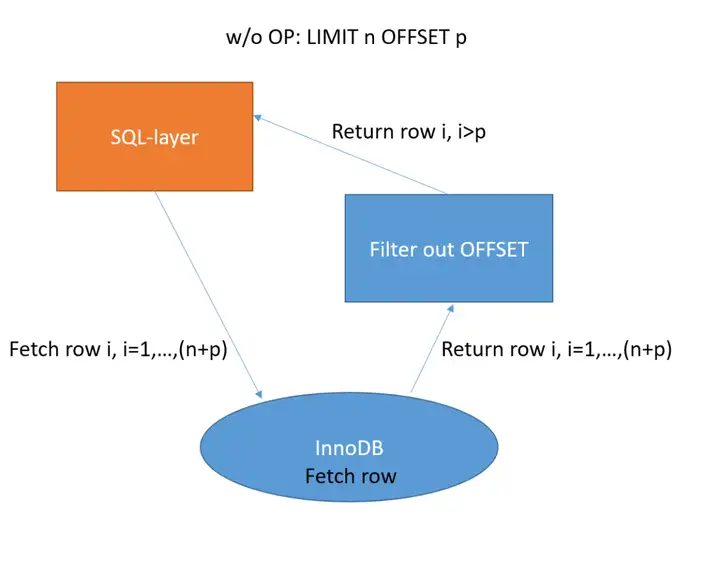
图1无OP的极限偏移逻辑
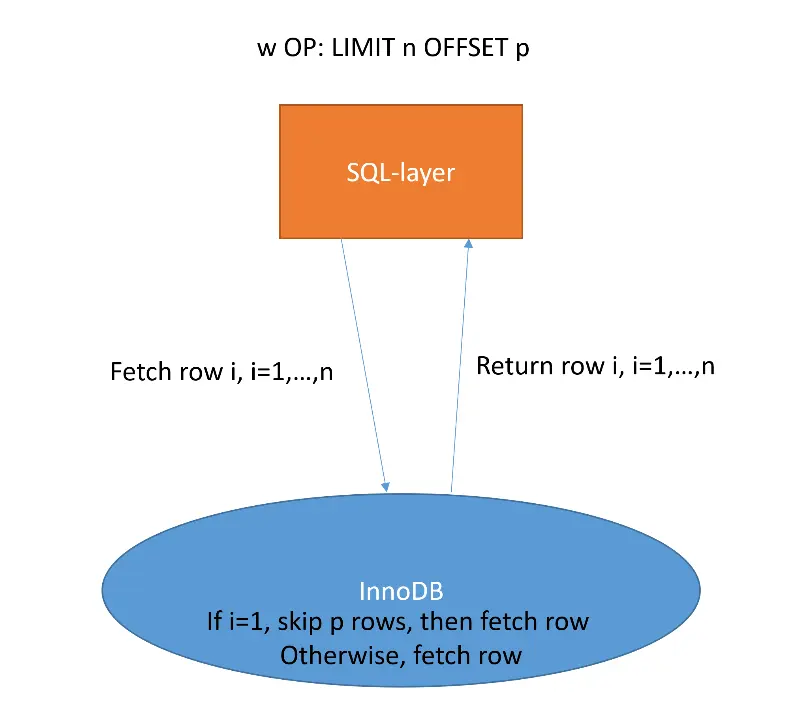
图2启用OP的LIMIT offset 逻辑
RCR的思路也比较简单:当进行索引范围扫描时,SQL 层对存储引擎返回的行执行冗余检查,因为它不知道存储引擎已经执行了这些检查,而RCR 就是让 SQL 层了解这点。为了使 OP 成为可能,除了要求WHERE条件能够被存储引擎独立且完整的评估,SQL 层还必须了解这点从而避免冗余检查。
OP功能的实现方式与索引条件下推 (Index Condition Pushdown,ICP) 类似。对于某些查询,ICP通过将整个 WHERE 子句下推到存储引擎来启用 OP。而RCR在 ICP 执行之前会评估条件是否冗余,并且移除冗余条件,确保了ICP不会处理冗余的条件检查。RCR很好地补充了OP特性的适用范围,允许更多查询使用 OP。
请注意:OP的启用需要满足三个主要条件:
1.SQL语句包含offset
2.WHERE子句完全由InnoDB处理
3.SQL语句只涉及一张表
另外:
RCR适用于索引范围扫描,如果WHERE子句中出现了一个或者多个条件,而这些条件涉及到的字段在对应使用的索引上是被连续定义的,这些条件的冗余检查就都会被移除。
方法一:使用特定的optimizer switch:offset _PUSHDOWN
set optimizer_switch='OFFSET_PUSHDOWN=[on]/[off]';
默认为on。
方法二:使用特定的优化器hint:[NO]_OFFSET_PUSHDOWN[TC1] ()
SELECT /*+ [NO]_OFFSET_PUSHDOWN() */ FROM TABLE LIMIT n OFFSET p;
请注意,hint优先级高于optimizer switch的设置。
我们基于下方创建的t1表,来举例说明如何使用OP:
CREATE TABLE t1 (a int, b int, INDEX (b));
示例一:表扫描
explain format=tree select * fromt1 limit 100 offset 1;+----------------------------------------------------------------------------------------------------------------------+| EXPLAIN|+----------------------------------------------------------------------------------------------------------------------+| -> Limit/Offset: 100/1row(s), with offset pushdown (cost=0.65 rows=4) -> Tablescan on t1 (cost=0.65 rows=4)|+----------------------------------------------------------------------------------------------------------------------+1 row in set (0.00 sec)
示例二:二级索引上的索引范围扫描
explain format=tree select a,b from t1 where b>2limit 100 offset 1;+------------------------------------------------------------------------------------------------------------------------------------+| EXPLAIN|+------------------------------------------------------------------------------------------------------------------------------------+| -> Limit/Offset: 100/1row(s), with offset pushdown (cost=1.61 rows=3) -> Indexrange scan on t1 using b (cost=1.61rows=3)|+------------------------------------------------------------------------------------------------------------------------------------+1 row in set (0.00 sec)
如何启用RCR?
通过系统变量rds_empty_redundant_check_in_range_scan设置,如下:
set rds_empty_redundant_check_in_range_scan=[true]/[false];
默认为true。
我们通过一个示例来说明:
创建t0表:
CREATE TABLE t0 (a int, b int,INDEX (a,b));
不启用RCR:
explainformat=tree select * from t0 where a<100 and a>20 LIMIT 1 OFFSET 100;+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+|EXPLAIN |+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+|-> Limit/Offset: 1/100 row(s)(cost=0.46 rows=1) -> Filter: ((t0.a < 100) and (t0.a > 20)) (cost=0.46 rows=1) -> Index range scan on t0 usinga (cost=0.46 rows=1)|+---------------------------
可以看出:列a上的范围条件会被InnoDB默认检查,但SQL层将再次检查InnoDB返回的行是否匹配列a的范围条件。在这种情况下,无法使用OP,因为SQL层不知道存储引擎实际上处理了整个WHERE子句。
启用RCR:设定rds_empty_redundant_check_in_range_scan = true;
explainformat=tree select * from t0 where a<100 and a>20 LIMIT 1 OFFSET 100;+------------------------------------------------------------------------------------------------------------------------------------+|EXPLAIN|+------------------------------------------------------------------------------------------------------------------------------------+|-> Limit/Offset: 1/100 row(s), with offsetpushdown (cost=0.46 rows=1) -> Index range scan on t0 using a (cost=0.46 rows=1)|+------------------------------------------------------------------------------------------------------------------------------------+1row in set (0.00 sec)
可以看出:启用RCR,删除SQL层对列A的范围条件的冗余检查后,启用OP。
创建表t1:
create table t1(a int, b int, INDEX(b));
不启用RCR:
explainformat=tree select a,b from t1 where b>2 limit 100 offset 1;+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+|EXPLAIN |+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+|-> Limit/Offset: 100/1 row(s), with offsetpushdown (cost=1.61 rows=3) -> Index range scan on t1 using b, with index condition: (t1.b >2) (cost=1.61 rows=3)|+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+1row in set (0.00 sec)
可以看出:使用了ICP后,OP也被启用了
启用RCR:
explainformat=tree select a,b from t1 where b>2 limit 100 offset 1;+------------------------------------------------------------------------------------------------------------------------------------+|EXPLAIN |+------------------------------------------------------------------------------------------------------------------------------------+|-> Limit/Offset: 100/1 row(s), with offsetpushdown (cost=1.61 rows=3) -> Index range scan on t1 using b (cost=1.61 rows=3)|+------------------------------------------------------------------------------------------------------------------------------------+1row in set (0.00 sec)
以上示例说明:ICP不是必要的。通过评估是否应使用ICP之前移除冗余条件,就可以避免使用ICP。
下面我们通过实际测试来验证OP所带来的性能提升。在测试中,我们重点关注:
考虑一个非覆盖索引,不使用OP,InnoDB必须从基表读取行,然后才能将它们返回到SQL层。使用OP后,就可以跳过行,而不必从基表读取。因此,OP在非覆盖索引上可以提供更好的性能。
我们希望通过热缓冲池全面提高性能,但我们也希望OP在热缓冲池上相对更高效,原因如下:
基于一个冷缓冲池并且查询使用覆盖索引扫描的场景,设定为不使用OP的计算时间(woop)和使用OP的计算时间(op)的比值:
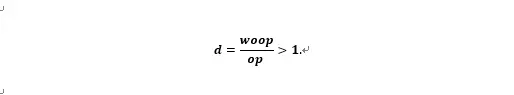
比值d预计将大于1,因为使用OP将获得性能提升。基于一个热缓冲池并且查询使用覆盖索引扫描的场景,设定是不使用OP的计算时间(woop)和使用OP的计算时间(op)的比值:
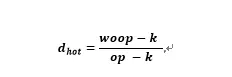
其中k表示从磁盘读取索引所需的时间,可以合理地假设,在使用OP和不使用OP的情况下,k都是相同的。因为不论是否使用OP,都必须从左到右遍历索引,无法在使用OP的情况下,利用B-tree结构索引的优势直接跳转到offset 范围的结束点。那么,这两个比值的差值可以表述为:
因此,我们预计OP在热缓冲池将更有效。
对于覆盖索引查询,可以假定索引数据都在缓冲池中,因此,缓冲池的大小对性能不会产生太大影响。然而,对于非覆盖索引的查询,情况会大不相同。在不使用OP时,缓冲池能缓存表数据的比例确实会对查询的性能产生有利的影响。
基于以上三个关注点以及预判,我们在一个包含200万行数据的测试表中,分别测试覆盖/非覆盖索引、冷/热缓冲池、不同缓冲池大小下条件下,通过OP带来的性能表现。
覆盖索引查询:
CREATE TABLE data (id int, value int, INDEX (id,value));SELECT * FROM data LIMIT 1 OFFSET p;
非覆盖索引查询:
CREATE TABLE data_non_covering(id INT, value INT, INDEX (value));INSERT INTO data_non_covering SELECT * FROM data;SELECT * FROM data_non_covering WHERE value>2 LIMIT 1 OFFSET p;
为了过滤干扰,计算时间是取9次运行结果的中位数。
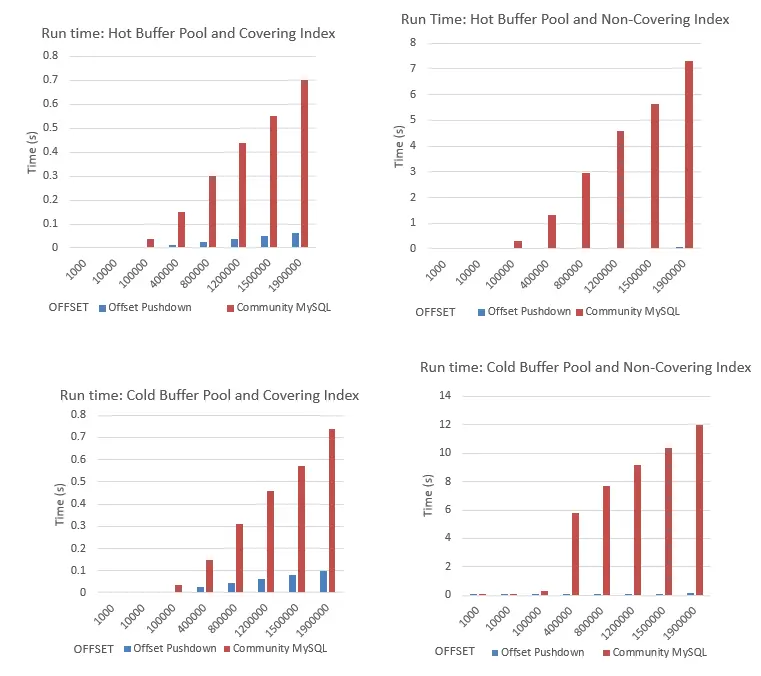

通过以上测试结果可以看出,在缓冲池大小为128MB的场景下,冷热缓冲池对OP带来的性能提升有不同影响:
热缓冲池
冷缓冲池
综上,在所有测试中,使用OP能提升查询性能。不论是冷缓冲池还是热缓冲池,启用OP后,非覆盖索引扫描可以比覆盖索引扫描获得10倍以上的性能提升。此外,正如我们所预计,在热缓冲池上启用OP获得了更大的性能提升。
对于大的OFFSET,使用OP可将性能提高一两个数量级,而RCR可扩大OP的适用范围。正如上述测试所证明,使用OP所带来的性能提升主要受下面两个因素的影响:
OP和RCR的联合使用,进一步扩大了OP的使用范围,可以为更多的Limit/offset查询带来性能提升,尤其是对大的offset操作。
在后续的研究中,我们将会评估OP与NDP(Near Data Processing, 近数据处理)的兼容性极其潜在的性能改进。

华为斯德哥尔摩研究所数据库Lab首席科学家,云数据库欧洲研发团队负责人。2020年加入华为,致力于打造世界级的企业级云数据库。吕漫漪在数据库领域有20多年从业经验,曾参与开发电信行业分布式高可用数据库,曾任MySQL原厂研发团队产品总监,长期深耕数据库技术。
华为云数据库工程师,就职于华为云数据库欧洲研发团队。Max毕业于挪威科技大学(NTNU),获得统计学硕士和博士学位;在此之前,他在法国马赛中央学院获得工程硕士学位。