摘要:设计一个线上压测系统能让我们学习到多少东西?这13个问题看你能否搞定。
本文分享自华为云社区《设计一个线上压测系统能让我们学习到多少东西?13个问题看你能否搞定》,作者:breakDawn。
A:
A:
在特定的业务场景下,将相关的链路完整地串联起来同时施压,尽可能模拟出真实的用户行为。
接口A做接口压测,可能是1w/s的QPS, 但是A和B同时压测,可能因为数据库连接等共享资源,导致实际QPS下降。
A:
A:
不需要全部参与。
如果设计过链路跟踪系统, 则每个服务都有中间件团队提供的拦截器, 因此直接通过公共拦截器来做压测标记的识别。
即发请求的时候已经不是同一段拦截器的代码了。 但是也要保证尽可能不改动原有的业务逻辑代码。
A:
如果处理请求和发下游请求是在一个线程中完成的, 那么可以使用threadLocal。
即拦截到请求时, 将压测标记set进threadLocal中。
发送下游请求的代码中,如果能从threadLocal中拿到压测标记,则改造url,设置进往下发的请求中
即我的业务代码中 做了new Thread或者ExectorPool.submit提交异步请求, 这时候业务逻辑里肯定不会涉及到threadLocal的代码, 而此时压测标记就会丢失了。
threadLocal可以用 InheriableThreadLocal, 这样如果在线程中new新的线程,则标记可以被传递下来。
如果是线程池创建异步请求, 可以用阿里的TransmittableThreadLocal。
A:
链路跟踪系统中发请求的filter中, 新增MockFilter, 如果判断是压测请求, 则直接返回mock逻辑(不建议部署mock服务, 因为部署mock服务的话,服务器成本又得考虑,不如直接封装到mockFilter代码中)
如果直接落库,可能会影响正常用户的请求访问, 也可能污染线上数据。
A:
为每个生产库 生成一个影子库, 专门用来存储压测数据。
然后做过分库分表的话, 肯定有数据库的proxy,在proxy里都往压测库插入和读写。
如果没有,就扩展Spring的AbstactRoutngDataSource类, 实现一个动态的数据源,让里面可以根据压测标记进行切换。
A:
除了添加统一特点的压测标记(中间件和业务不是强相关,所以可以进行特定改造)
还要注意缓存的存活时间要设置短一点。
A:
注意不要触发 数据源的init-method方法, 当真正执行压测的时候再建议会话连接。
各种超期时间也要注意设置, 尽快接触压测对组件的影响。
A:
不行,如果业务有改动,参数很容易对不上,同时组装过程耗时也会非常久。
建议从线上直接dump最近的请求数据,这样可保证参数没有变化。
同时做一些脱敏和修正处理。
A:
该问题参考《超大流量分布式系统架构解决方案》一书中给出的方案,也可以有其他方案。
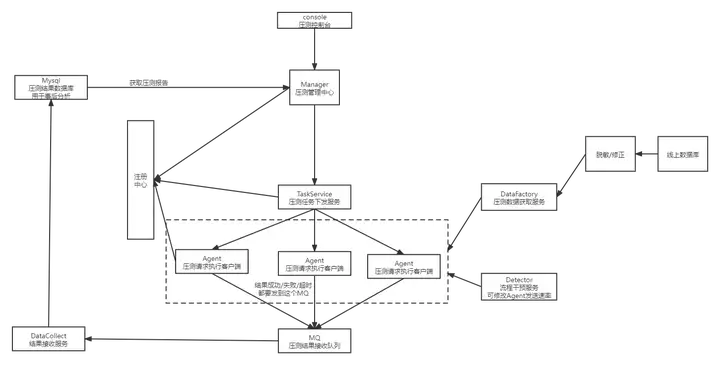
A: