摘要:今天带领大家学习自然语言处理中的词嵌入的内容。
本文分享自华为云社区《【MindSpore易点通】深度学习系列-词嵌入》,作者:Skytier。
在自然语言处理中,有一个很关键的概念是词嵌入,这是语言表示的一种方式,可以让算法自动的理解一些同类别的词,比如苹果、橘子,比如袜子、手套。

比如我们通常会说:“I want a glass of orange juice.”但如果算法并不知道apple和orange的类似性(这两个one-hot向量的内积是0),那么当其遇到“I want a glass of apple __”时,并不知道这里也应该填写 juice。
如果用特征化的表示来表示库里的每个词,学习它们的特征或者数值。

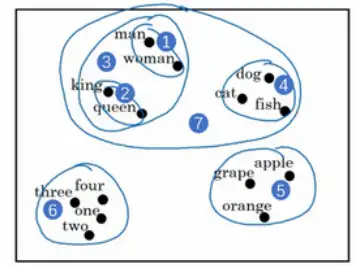
这样我们就可以选用t-SNE算法来对特征向量可视化,通过观察这种词嵌入的表示方法,最终同类别的单词会聚集在一块,词嵌入算法对于相近的概念,学到的特征也比较类似。
参考案例——句中找人名:Jack Li is a teacher.
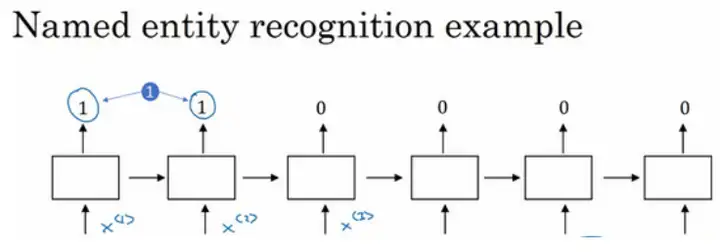
使用词嵌入作为输入训练好的模型,如果看到一个新的输入:“Jack Li is a farmer.”因为知道teacher和farmer很相近,那么算法很容易就知道Jack Li是一个人的名字。同时,如果遇到不太常见的单词,比如:Jack Li is a cultivator.(假设训练集里没有cultivator这个单词),但是词嵌入的算法通过考察大量的无标签文本,会发现farmer、teacher、cultivator相近,把它们都聚集在一块。这样一来即使只有一个很小的训练集,但是使用迁移学习,把从大量的无标签文本中学习到的知识迁移到一个任务中——比如少量标记的训练数据集的命名实体识别任务。
如何用词嵌入做迁移学习的步骤:
1.先从大量的文本集中学习词嵌入。
2.用这些词嵌入模型把它迁移到新的只有少量标注训练集的任务中,比如说用300维的词嵌入来表示单词,这样就可以用更低维度的特征向量代替原来的10000维的one-hot向量。
3.当在新的任务上训练模型时,只有少量的标记数据集,可以选择不进行微调,而是用新的数据调整词嵌入。
当你的任务的训练集相对较小时,词嵌入的作用最明显,所以它广泛用于NLP领域,但是其对于一些语言模型和机器翻译并不适用。
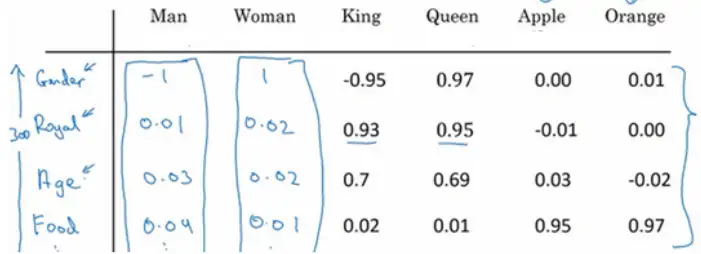
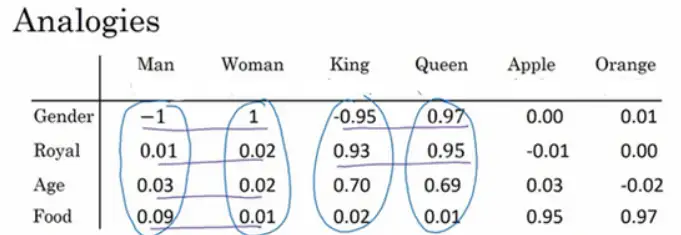
词嵌入有一个非常强大的特性就是可以帮助实现类比推理。比如从性别这个特征上来说,如果man应该对应woman,那么算法可以推导出king对应queen。



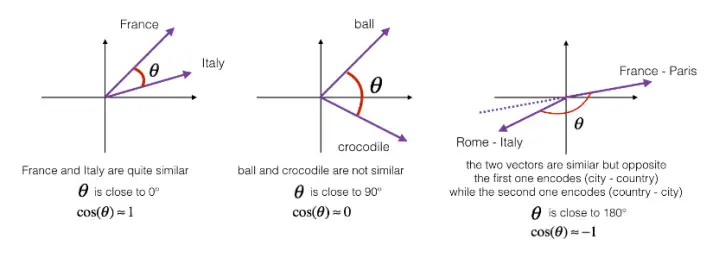
最常用的相似度函数是余弦相似度,假如在向量u和v之间定义相似度:
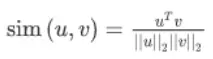
如果u和v非常相似,那么它们的内积将会很大,那么该式就是u和v的夹角Φ的余弦值,实际就是计算两向量夹角Φ角的余弦。夹角为0度时,余弦相似度就是1,当夹角是90度角时余弦相似度就是0,当夹角是180度时相似度等于-1,因此角度越小,两个向量越相似。