摘要:先通过OPS确认节点状态是否已经恢复,或登录后台执行cm_ctl query -Cv确认集群是否已经Normal。
本文分享自华为云社区《【实例状态】GaussDB CN服务异常》,作者:酷哥。
先通过OPS确认节点状态是否已经恢复,或登录后台执行cm_ctl query -Cv确认集群是否已经Normal。如果状态已经为normal,表明故障已经恢复,集群正常,不再影响业务。 确认是否需要分析故障的具体原因,如果需要,继续向下跟随文档进行分析 首先确认是否是底层故障如虚拟机故障、网络故障、存储故障,排除底层故障后再继续定位。
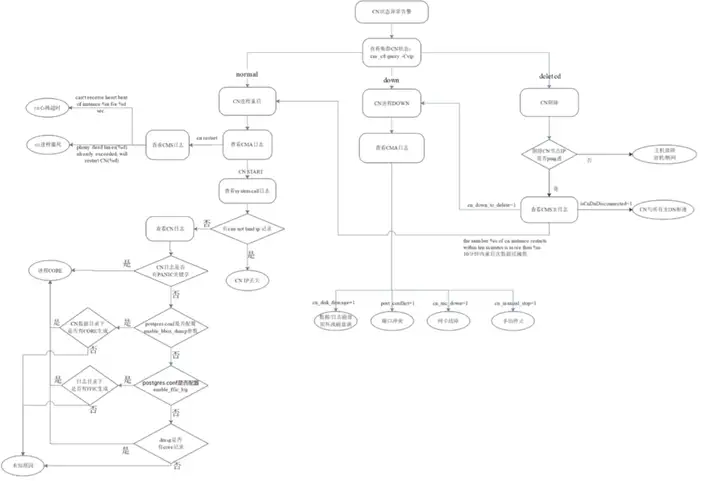
cm_ctl query -Cvd 查询集群状态,告警CN显示normal。
step1. 登录告警CN节点,su 进入集群用户,ps ux | grep 'gaussdb --coordinator',查看CN进程启动时间,确认CN是否重启,如果没有重启参考处理方法一(结束),若重启则跳至step2
step2. cd $GAUSSLOG/cm/cm_agent
step3. 打开对应时间点的vi cm_agent-*.log
step4. 查看日志中对应时间点是否含有关键词 cn restart,如果同时有process (gaussdb 17391) is T (STOPPED) 类似日志,说明进程hang住了,跳至step6
step5. 若日志中没有cn restart关键词,查看日志中对应时间点是否含有关键词 CN START.有则跳至step10
step6. 登录到CMS主节点 cd $GAUSSLOG/cm/cm_server
step7. 打开对应时间点的cm_server*.log
step8. 查看日志中对应时间点是否含有关键词 restart %u, there is not report msg for %d sec. 如果有,则CN重启原因为心跳超时,参考处理步骤方法一(结束 )
step9. 查看日志中对应时间点是否含有关键词 phony dead times (%d) already exceeded, will restart...则CN重启原因为进程僵死,参考处理步骤方法一(结束)
step10. cd $GAUSSLOG/cm/cm_agent,打开对应时间点的system_call-*.log,查看对应时间点是否有关键词can not bind ip,如果没有则跳至step12
step11. 如果有关键词can not bind ip,则CN重启原因为CN IP丢失,参考处理步骤方法二 (结束)
step12. cd $GAUSSLOG/pg_log/cn_XX
step13. 查看相关postgresql_xxx.log, 查看相关时间点是否有关键词PANIC,如果有则原因为core,参考处理步骤方法一。
step14. 查看CN数据目录下是否有core生成,如果有则原因为core,参考处理步骤方法一。
step15. 查看$GAUSSLOG/ffic_log日志,查看对应时间点是否有打印日志,如果有则原因为core,参考处理步骤方法一。
方法一:联系华为工程师进行定位
方法二:检查故障节点虚拟IP,浮动IP。如有问题,请排查管控HA是否关闭。
cm_ctl query -Cvd 查询集群状态,告警CN显示down。
step1. cd $GAUSSLOG/cm/cm_agent
step2. 打开对应时间点的cm_agent-*.log
step3. 查看日志中对应时间点是否含有关键词 cn_disk_damage=1,如果有,则原因为数据/日志磁盘损坏或磁盘满,参考处理步骤方法一。
step4. 查看日志中对应时间点是否含有关键词 port_conflict=1,如果有,则原因为端口冲突,参考处理步骤方法二。
step5. 查看日志中对应时间点是否含有关键词 cn_nic_down=1,如果有,则原因为网卡故障,参考处理步骤方法三。
step6. 查看日志中对应时间点是否含有关键词 cn_manual_stop=1,如果有,则原因为手动停止,参考处理步骤方法四。
方法一:查看对应故障cn的磁盘是否有故障,如无故障则检查是否磁盘满。
方法二:lsof -i:端口号,查看端口占用进程,联系华为工程师定位处理
方法三:联系I层查看是否存在网卡故障
方法四:查看是否有人手动停止
cm_ctl query -Cvd 查询集群状态,告警CN显示deleted。
step1. 确认当时时间故障CN所在节点是否正常,是否主机故障,重启、掉电,断网等,参考处理步骤方法一。
step2. 登入CMS主节点,cd $GAUSSLOG/cm/cm_server,打开对应时间点的cm_server*.log
step3. 如果日志中有关键词isCnDnDisconnected=1, 则原因为CN与所有主DN断连,参考处理步骤方法二。
step4. 如果日志中有关键词cn_down_to_delete=1,则原因为CNdown 导致,参考处理步骤方法三。
step5. 如果日志中有关键词cn instance restarts within ten minutes is more than,则原因为CN进行重启 导致,参考处理步骤方法四。
方法一:联系I层查看主机故障原因,排除故障后,在管控点击节点修复修复cn节点。
方法二:在管控点击[节点修复]修复cn节点,联系华为工程师处理
方法三:在管控点击[节点修复]修复cn节点,参考第二章CN DOWN进行定位
方法四:在管控点击[节点修复]修复cn节点,参考第一章CN NORMAL进行定位
cm_ctl query -Cvd 查询集群状态,告警CN显示readonly。
step1. 登录到只读CN节点后,su - Ruby进入Ruby用户, 执行/usr/sbin/chroot --userspec=Ruby:Ruby /var/chroot 进入沙箱,source /etc/profile设置环境变量
step2. df -h 查看磁盘空间分配情况,cm_ctl query -Cvd查看CN数据目录路径,确认所在磁盘空间使用率。
step3. 登陆cmserver主节点,进入cmserver数据目录/var/chroot/usr/local/cm/cm_server,查看cm_server.conf 配置文件,查看参数datastorage_threshold_value_check的值,当磁盘使用率超过该参数值时,CN就会被设置为只读,避免磁盘被写满。比较CN磁盘使用率是否超过该参数值,如果是,则按照处理步骤1处理,如果否,则按照步骤2处理
1、联系华为工程师,确定是否需要扩容或者删除同磁盘的无用文件
2、参考CN只读处理方法