摘要:在敏捷中,让设计简单化,必须让设计从简单开始,然后变得成熟。要做到这一点,重构是唯一的出路。
本文分享自华为云社区《敏捷技术实践之重构》,作者:华为云PaaS服务小智 。
极限编程(XP)的创始人之一Ron Jeffries说道:“在敏捷中,让设计简单化,必须让设计从简单开始,然后变得成熟。要做到这一点,重构是唯一的出路。”
重构是指改变代码的结构,而不是代码的行为。举个例子:假设一个程序中有两个方法,每个方法都包含几行相同的代码,那么这几行相同的代码可以从原来的两个方法中抽取出来,放到一个新的方法中,在原来放置这几行代码的地方替换为调用这个新的方法。这个重构稍微改善了程序的可读性和可维护性,因为现在一些代码明显被复用,并且重复的代码被移到了一个地方。代码结构发生了改变,但是行为并没有变。
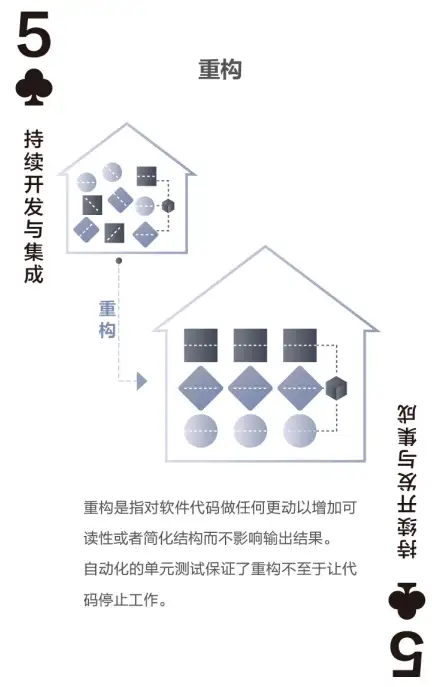
重构不仅对TDD(测试驱动开发)的成功至关重要,同时也有助于防止代码腐烂。代码腐烂是由重复的代码、无数的补丁、糟糕的分类和其他编程差异造成的。团队的开发人员以他们自己的风格编写代码也会导致代码腐烂。产品发布后,代码腐烂是典型的综合症,如果允许代码腐烂,过不了几年,系统就要全部重写。通过不断的重构,并且在一些小问题变成大问题之前不断地修复它们,我们能够保持我们的应用程序不会腐烂。Robert C.Martin称之为童子军规则。
童子军里有一个规定:“离开的时候,总要让露营地比你来的时候更干净。”应用于软件开发中就是:提交一个模块代码的时候,要让它比下载的时候更简洁一些,不论谁是这段代码的原作者。如果我们都遵循这个简单的规定我们的系统最终会变得越来越好,是整个团队照料整个系统,而非个人各自只关心他们那一小部分,这样就符合代码集体所有制原则,同时还可以培养团队成员的主人翁精神和责任感。
Kent Beck提出了“代码坏味道”的说法,这种坏味道,就是发出了重构的强烈信息,在《重构》一书中提到了24类,在这里我们重点讨论以下几类:
猜谜这件事如果发生在阅读代码的时候,就不是一个好的体验。代码整洁最重要的一项就是好的命名,尽量做到见名知意。每个团队都有自己统一的命名规范,常见命名方法有驼峰命名法如userName,蛇形命名法如user_name,脊柱命名法如user-name等,不论哪一种,就是不要出现theList,var1这种写法。
在代码编写过程中,我们应该深思熟虑如何给函数、模块、变量和类命名,使他们能够清晰地表明自己的功能和用法。改名是最常用的重构手段,包括修改函数声明、变量改名、字段改名等,好的名字能够节省未来在猜谜上的大把时间。如果想不出一个好的名字,说明背后很可能潜在更深的设计问题,为一个名字所付出的纠结,常常能推动我们对代码进行精简。
重复代码,顾名思义就是两段代码看上去几乎相同或者两段代码都是实现相同的功能。当程序中存在大量重复的代码,会造成代码长度过长,不易阅读,遇到相同或相似的代码段需要仔细分辨,如果需要修改某一处的时候,为了避免遗漏需要查找出所有的相同代码段进行修改,不易维护。
如果是同一个类的两个函数含有相同的代码,如文章开头的例子,这时候可以用提炼函数来提炼出重复的代码,然后让这两个地点都调用被提炼出的那段代码。如果重复代码只是相似而不是相同,可以先尝试用移动语句重组代码顺序,把相似的部分放在一起以便于提炼。
函数通常都需要接收参数,然后去完成某些处理,在《代码整洁之道》中提出,一个函数的参数应该尽可能短,最好只有一个,其次是两个,如果出现三个以上的参数,就需要注意了。函数的参数过多不易于维护和修改,可读性也差,容易出错。
如果一些参数来自同一个对象,那么就不要单独取出这些数作为函数参数传递,而是直接将这个对象传递过去。如果某些参数值可以通过调用已知的一个方法得到,那么就要把这个参数退换为在方法体内调用取值的那个已知方法。还有参数不来自同一个对象,如果有必要,我们也要毫不犹豫的为这些参数新建一个不可变的类,强制将它们放在一起
在编程早期,由于调用子函数需要产生额外的开销,所以大家都不喜欢小函数,一个函数动辄几百多行,鼠标的滚动条要滚好一会才能到方法末尾,更不用说一行一行的去阅读,去理解,可以想象别人来修改这段代码的时候他有多么痛苦。现代的开发环境已经完全免除了进程内的函数调用开销。所以要保证自己的函数短小精悍。通常一个函数长度的底线是要在一个屏幕内完全显示。
当然有时候一个函数开始的时候并不是那么长,只是随着每次需求的变更,每次一点点的加代码而没有注意重构,侥幸的认为一点点根本不算什么,积少成多最后终于不可收拾了。
过长函数应该积极的进行函数分解,提炼函数,找到函数中适合集中在一起的部分,把他们提炼出来形成一个新的函数。哪怕有时候是对一行代码进行这样的提取也是值得的行动,因为关键不在于函数的长度,而是在于函数做了什么。
在开始学习编程的时候,老师应该讲过避免使用全局变量,因为它太不可控了,在代码的任何一个角落都可以修改它,而且没有任何机制能够探测出来到底哪段代码做出了修改。全局变量一次次造成的那种诡异bug,足够让你刻骨铭心。
对于全局数据要避免使用,函数内的就放在函数体内,代码段内的就放在代码段中。无处可放,需要单独存在的全局数据就将其封装在函数中,这样就可以找到在哪个地方进行了修改,还要将这个函数放在某个类中,限定那些方法可以使用它,让数据的修改过程可控可追溯。
代码中如果出现了大段的注释用来解释代码的含义,而原因是代码写的太糟糕了,不得不依赖于注释,这就是一种坏味道。
当你感觉需要写注释的时候,可以先试试重构,试着让所有注释都变得多余。如果需要注释来解释一段代码做了什么,可以试试提炼函数;如果函数已经提炼出来,但是还是需要注释来解释做了什么,可以试试为函数声明改名;如果注释是说明某些系统的需求规格,试试引入断言。
不是提倡不要写注释,而是要写合适的注释,对于注释,我们应该遵循这样一条原则:“注释的使用不是为了说明这段代码能做什么而是应该说明为什么要这么做”。
死代码泛指在程序运行过程中执行不到的代码,或者执行的到但没有任何作用的代码,也就是无用代码。当程序中的变量变成不依赖于外部传过来的数据,被定义成常量时,便无法适应外界其他的变化,就会产生死代码。这些代码通常是由于需求变更或者代码修改,变得用不到了,如果发现,就及时清除它们。
重构越晚,需要修改的代码越多,就会形成技术债务。除了上面提到的几类重构的场景,还有很多其他的场景,重构虽然不是包治百病的灵丹妙药,但是重构是非常有价值的,可以帮助你始终良好地控制自己的代码。尤其是作为敏捷开发团队,重构是团队成员应该熟练掌握的,任何团队都应建立重构技能。同时,Scrum培训师Stefan Wolpers表示,Scrum团队应该考虑将15%~20%的资源分配给每个Sprint周期的重构代码和修复错误。由此可见,重构这件事情是循序渐进的作为一项改进活动持续进行。