摘要:MindStudio提供精度比对功能,支持Vector比对能力。
本文分享自华为云社区《【MindStudio训练营第一季】MindStudio 高精度对比随笔》,作者:Tianyi_Li。
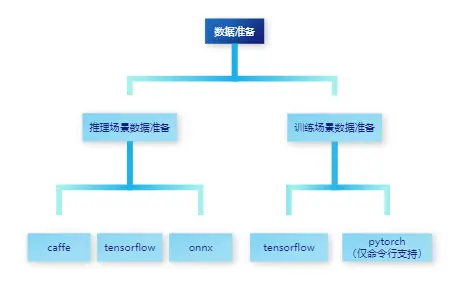
训练场景下,迁移原始网络 (如TensorFlow、PyTorch) ,用于NPU上执行训练,网络迁移可能会造成自有实现的算子运算结果与用原生标准算子运算结果存在偏差。推理场景下, ATC模型转换过程对模型进行优化,包括算子消除、算子融合算子拆分,这些优化也可能会造成自有实现的算子运算结果与原生标准算子(如TensorFlow、ONNX、 Caffe ) 运算结果存在偏差。
为了帮助开发人员快速解决算子精度问题,需要提供自有实现的算子运算结果与业界标准算子运算结果之间进行精度差异对比的工具。
精度比对工具能够帮助开发人员定位本次任务两个网络间的精度差异。准备好昇腾腾AI处理器运行生成的dump教据与Ground Truth数据 (基于GPU/CPU运行生成的数据)后,即可进行不同算法评价指标的数据比对。
MindStudio提供精度比对功能,支持Vector比对能力,支持下列算法:
精度比对根据推理/训练和不同的框架分为多个比对场景。
原始模型数据即为原始网络在GPU/CPU侧生成的数据,主要依赖原始框架中的源生能力,将模型中每一个算子节点的输入输出数据进行保存。
NPU模型数据即为通过对原始模型的迁移或训练在县腾A处理器上得到的数据,主要依赖华为侧提供对应用推理及训练提供的Dump能力,将模型中每一个算子节点的输入输出数据进行保存。
由于MindStudio精度比对工具的使用约束,数据需要满足以下格式:

在进行TensorFlow模型生成npy数据前,您需要已经有一套完整的、可执行的、标准的TensorFlow模型应用工程。然后利用TensorFlow官方提供的debug工具tfdbg调试程序,从而生成npy文件。通常情况下,TensorFlow的网络实现方式主要分为Estimator模式和session.run模式,具体操作如下:
1.修改tf训练脚本,添加debug选项设置
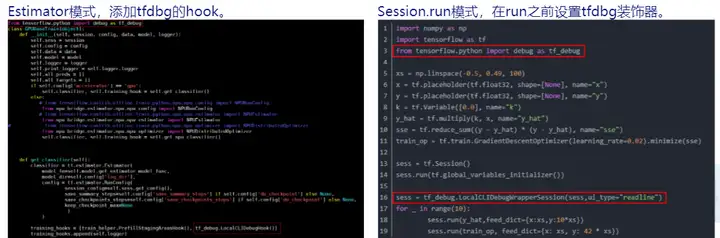
2.执行推理或训练脚本,任务运行到前面debug配置后暂停
3.进入调试命令行交互模式后,
timestamp=$[S(date +%s%N)/1000] ; cat tensor name | awk 'print "pt",$4,$4)' | awk '[gsub("/", ""$3);gsub("""" $3);print($1,$2,"-n 0 -w "$3"stimestamp"""npy")y' > tensor name cmd.txt
注: 更加详细操作见《CANN开发辅助工具指南》中“精度比对工具使用指南”章节。
推理场景数据准备一NPU的融合后推理数据NPU采用AscendCL完成离线推理:
1.在代码中调用acllnit(“./acl.json”)
acl.json的文件内容如下:

2.运行推理应用,生成dump数据
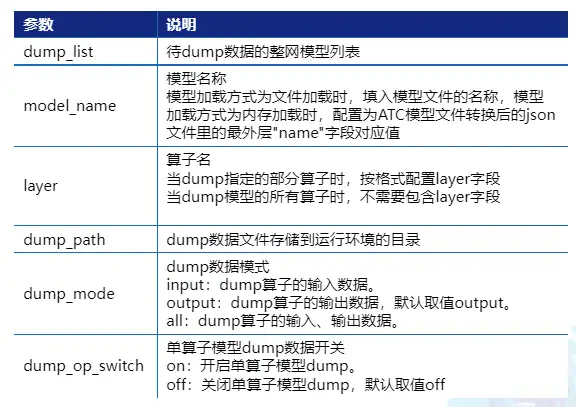
训练场景数据准备-NPU的迁移后网络训练数据
以TensorFlow为例,步骤如下:
1.设置“DUMP GE GRAPH=2”生成计算图文件,同时修改训练脚本,开启dump功能

2.执行训练脚本,生成dump数据和计算图文件
3.选取计算图文件
可使用grep lterator* Build.txt命令快速查找出的计算图文件名称,如ge proto 00005 Build.txt.
4.选取dump数据文件
打开上述计算图文件,找出第一个graph中的name字段,即为dump文件存放目录名称。
将准备好的标准数据文件与待比对数据文性作为输入文件,并配置对应的离线模型文件,通过对文件内所有参与计算的算子输入与输出进行精度比对。
整网比对在MindStudio界面菜单栏洗择“Ascend > Model Accuracy Analvzer > New Task菜单,进入比对界面。
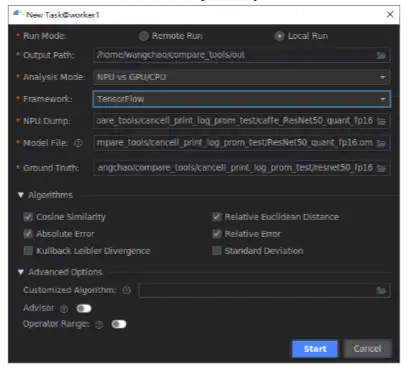
整网比对结果主要分为四大展示模块:
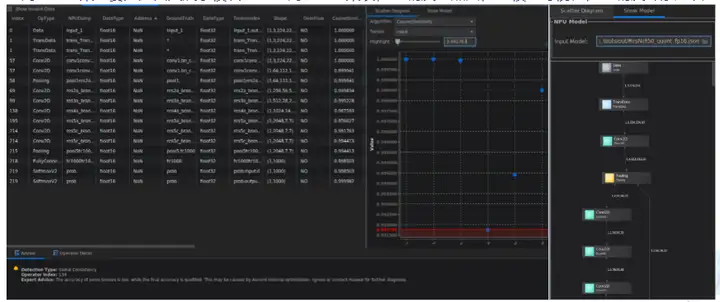
精度比对工具本身只提供自有实现算子在昇腾AI处理器上的运算结果与业界标准算子的运算结果的差异比对功能,而输出的比对结果需要用户自行分析并找出问题。而对结果的分析工作对于用户来说也是一大难点,而专家系统工具为用户提供精度比对结果的结果分析功能,有效减少用户排查问题的时间。只需在比对操作配置任务时勾选“Advisor”选项,系统则会在比对完成后自动进行结果文件的分析,并输出优化建议。
当前支持的分析检测类型有:FP16溢出检测、输入不一致检测、整网一致性检测(整网一致性检测包括:问题节点检测、单点误差检测和一致性检测三个小点)
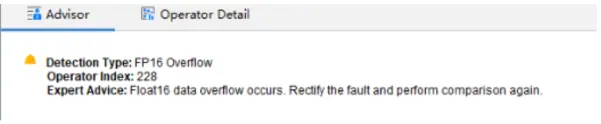
这里特别说明下FP16溢出检测,针对比对数据中数据类型为FP16的数据,进行溢出检测。如果存在溢出数据,输出专家建议,示例图如下所示。
专家系统分析结果: Detection Type: FP16 overflow Operator Index: 228 Expert Advice: Float16 data overflow occurs. Rectify the fault and perform comparison again. 检测类型:FP16溢出检测 Operator Index:228 专家建议:存在Float16数据溢出,请修正溢出问题,再进行比对。
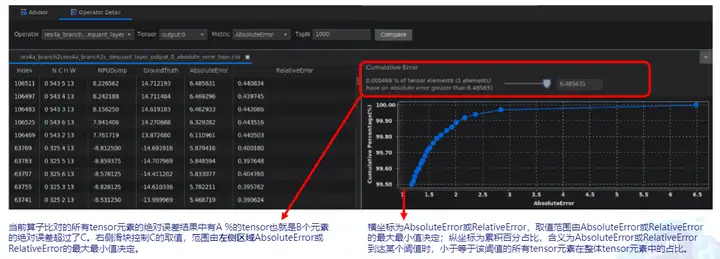
可针对整网任务中的某个算子进行单算子比对,分析某个算子的具体精度差异。
使用约束
FLOAT
FLOAT16
DT_INT8
DT_UINT8
DT_INT16
DT_UINT16
DT_INT32
DT_INT64
DT_UINT32
DT_UINT64
DT_BOOL
DT_DOUBLE
特别说明
dump文件无法通过文本工具直接查看其内容,为了查看dump文件内容,需要用脚本将dump文件转换为numpy格式文件后,再通过numpy官方提供的能力转为txt文档进行查看。脚本在/home/HwHiAiUser/Ascend/ascend-toolkit/latest/tools/operator_cmp/compare目录,名为msaccucmp.py。举例用法如下:
python3 msaccucmp.py convert -d dump_file [-out output] [-f format -s shape] [-o output_tensor] [-i input_tensor] [-v version] [-t type]
调用Python,转换numpy文件为txt文件的完整示例如下:
$ python3 >>> import numpy as np >>> a = np.load("/home/HwHiAiUser/dumptonumpy/Pooling.pool1.1147.1589195081588018.output.0.npy") >>> b = a.flatten() >>> np.savetxt("/home/HwHiAiUser/dumptonumpy/Pooling.pool1.1147.1589195081588018.output.0.txt", b)
但转换为.txt格式文件后,维度信息、Dtype均不存在。详细的使用方法请参考numpy官网介绍。
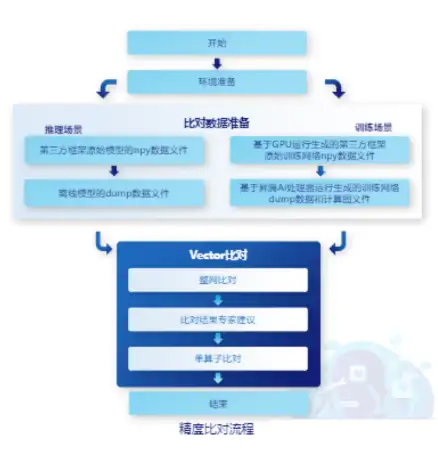
精度对比总计分为环境准备、数据准备和对比三步。
数据准备要根据推理场景和训练场景分别分析:
准备后上述步骤,可进行对比:
最后说下Tensor比对,Tensor对比提供整网比对和单算子比对两种精度比对方式,需要根据比对场景选择比对方式。其中,整网比对:将准备好的标准数据文件与待比对数据文件作为输入文件,通过对文件内所有参与计算的算子进行精度比对。而单算子比对:在整网比对的基础上指定具体算子名,对单个算子进行详细数据的比对。
个人认为,精度对比这是一个需要时间、精力和经验的操作,要充分利用好MindStudio工具,或查文档,或提问,可大大降低我们的工作量,提高效率。但是不得不说,这是需要一定经验的,还是要多看多学习,多试多问啊。