摘要:主要介绍华为云在HBase 2.x内核所做的一些MTTR优化实践。
本文分享自华为云社区《华为云在HBase MTTR上的优化实践》,作者: 搬砖小能手。
随着HBase在华为云的广泛应用,HBase的数据节点规模也越来越大。最新版本的MRS可支持的单集群HBase数据节点规模可达到1024节点,可支持的region数量可达到200w+。面对如此大规模的节点数量,集群的MTTR也面临着巨大的挑战。
首先介绍一下HBase故障恢复涉及的几个主要Procedure:
当HMaster检测到RegionServer故障后,会创建一个ServerCrashProcedure任务处理RegionServer的故障恢复。
该Procedure任务主要处理的事务包括WAL Split和Region Assign:
由此可以看出,一个RegionServer节点的恢复,中间会涉及到大量的Procedure任务,下面我们介绍一下华为云的HBase这对这部分所做的一些优化实践。
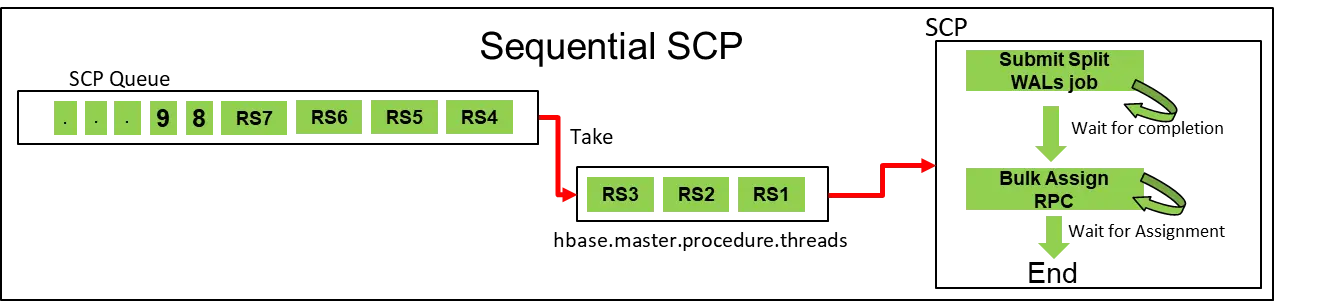
前面提到ServerCrashProcedure会包含多个SplitWALProcedure和TransitRegionStateProcedure,这两种Procedure在ServerCrashProcedure里面是串行执行的,也就是说TransitRegionStateProcedure只有在所有SplitWALProcedure任务执行完成之后才会开始执行,在WAL Split流程结束之前,整个ServerCrashProcedure会一直占用Procedure的线程资源并等待。
在大集群的场景下,由于HMaster的Procedure线程池资源有限,这样会导致有大量的ServerCrashProcedure任务在队列中等待。
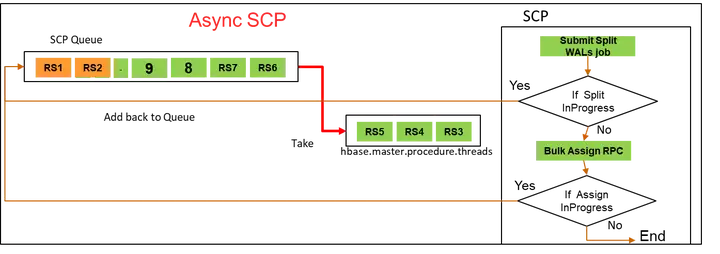
针对这种情况,我们讲ServerCrashProcedure任务改为异步执行,在执行WAL Split过程中,将ServerCrashProcedure重新放回队列并释放资源给其他待执行的任务。当WAL Split执行完成后,再重新唤醒该任务并继续提交执行TransitRegionStateProcedure。
优化前:MTTR = (Avg SCP * RS Count) / (hbase.master.procedure.threads)
优化后:MTTR = (Avg Split time) + (RS Count * Avg Assign time)/ (hbase.master.procedure.threads)
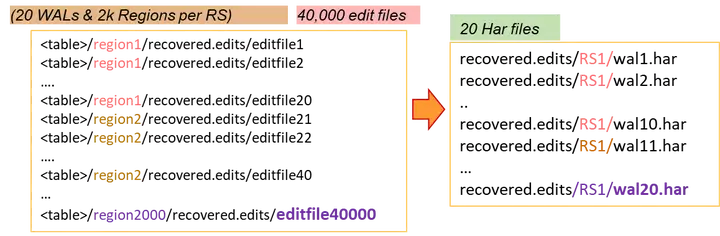
通过测试,我们发现在WAL Split阶段会产生大量的文件IO,主要是因为WAL Split阶段会生成大量的recovered.edits文件。因此,在大集群下,这部分的开销会导致HDFS的NameNode成为瓶颈。
对此,我们利用Hadoop提供的HAR file对生成的小文件进行优化,大大减少文件IO的开支,达到MTTR优化的目的。

我们以单个RegionServer 20个WAL+2000个region来举例:
通过HAR优化,单个RS的IO次数将由2000次读+2000次写减少为3次读+3次写。单个RS生成的文件数据也由40000个减少为20个。
最终在测试环境通过对100个RS,每个RS 20个WAL+2000个region的规模进行对比测试,HDFS的的IO负载下降了70%(RPC请求数从640万下降到150万左右),MTTR的时间则从103分钟下降到26分钟。
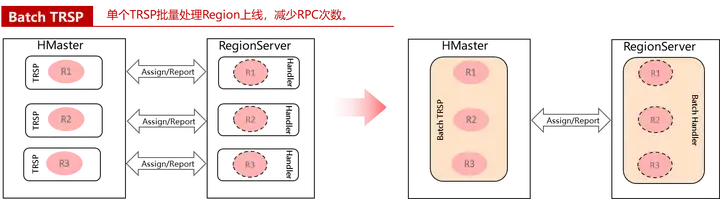
由于TransitRegionStateProcedure只负责处理一个Region,大集群下的region往往都在几十万甚至更多,这样的话,HBase恢复过程中会产生大量的TransitRegionStateProcedure任务。为了减少大量Procedure所带来的任务开销,我们优化了TransitRegionStateProcedure,允许一个Procedure任务处理一个RegionServer上所有的region assign。这样不仅减少了Procedure任务的数量,还大大减少了HMaster跟RegionServer的RPC开销。