摘要: 本文介绍了CANN自定义算子开发的几种开发方式和算子的编译运行流程。然后以开发一个DSL Add算子为例,讲解算子开发的基本流程。
本文分享自华为云社区《昇腾CANN算子开发揭秘》,作者:昇腾CANN 。
开发者在利用昇腾硬件进行神经网络模型训练或者推理的过程中,可能会遇到以下场景:
此时我们就需要考虑进行自定义算子的开发,本期我们主要带您了解CANN自定义算子的几种开发方式和基本开发流程,让您对CANN算子有宏观的了解。
相信大家对算子的概念并不陌生,这里我们来做简单回顾。深度学习算法由一个个计算单元组成,我们称这些计算单元为算子(Operator,简称OP)。
在网络模型中,算子对应层中的计算逻辑,例如:卷积层(Convolution Layer)是一个算子;全连接层(Fully-connected Layer, FC layer)中的权值求和过程,是一个算子。
再例如:tanh、ReLU等,为在网络模型中被用做激活函数的算子。
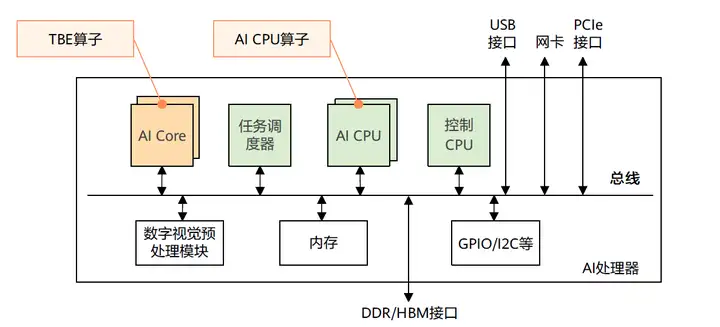
学习CANN自定义算子开发方式之前,我们先来了解一下CANN算子的运行位置:包括AI Core和AI CPU。
CANN支持用户使用多种方式来开发自定义算子,包括TBE DSL、TBE TIK、AICPU三种开发方式。其中TBE DSL、TBE TIK算子运行在AI Core上,AI CPU算子运行在AI CPU上。
TBE(Tensor Boost Engine:张量加速引擎)是CANN提供的算子开发框架,开发者可以基于此框架使用Python语言开发自定义算子,通过TBE进行算子开发有TBE DSL、TBE TIK两种方式。
为了方便开发者进行自定义算子开发,CANN预先提供一些常用运算的调度,封装成一个个运算接口,称为基于TBE DSL开发。DSL接口已高度封装,用户仅需要使用DSL接口完成计算过程的表达,后续的算子调度、算子优化及编译都可通过已有的接口一键式完成,适合初级开发用户。
TIK(Tensor Iterator Kernel)是一种基于Python语言的动态编程框架,呈现为一个Python模块,运行于Host CPU上。开发者可以通过调用TIK提供的API基于Python语言编写自定义算子,TIK编译器会将其编译为昇腾AI处理器应用程序的二进制文件。
TIK需要用户手工控制数据搬运和计算流程,入门较高,但开发方式比较灵活,能够充分挖掘硬件能力,在性能上有一定的优势。
AI CPU算子的开发接口即为原生C++接口,具备C++程序开发能力的开发者能够较容易的开发出AI CPU算子。AI CPU算子在AI CPU上运行。
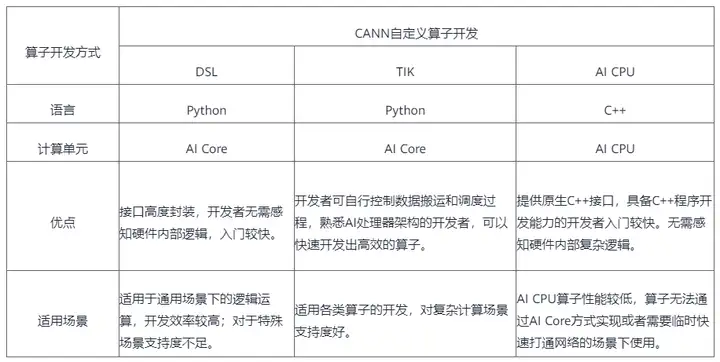
下面的开发方式一览表,对上述几种开发方式作对比说明,您可以根据各种开发方式的适用场景选择适合的开发方式。
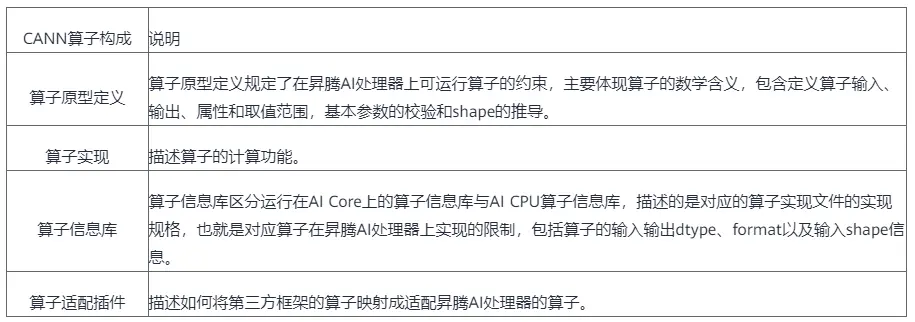
一个完整的CANN算子包含四部分:算子原型定义、对应开源框架的算子适配插件、算子信息库和算子实现。这四个组成部分会在算子编译运行的过程中使用。
推理场景下,进行模型推理前,我们需要使用ATC模型转换工具将原始网络模型转换为适配昇腾AI处理器的离线模型,该过程中会对网络中的算子进行编译。
训练场景下,当我们跑训练脚本时,CANN内部实现逻辑会先将开源框架网络模型下发给Graph Engine进行图编译,该过程中会对网络中的算子进行编译。
CANN算子的编译逻辑架构如下:
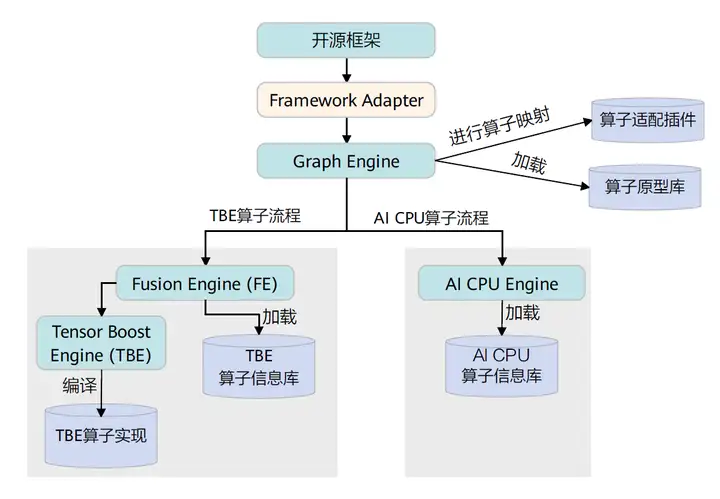
具体的CANN算子编译流程如下,在编译流程中会用到上文提到的算子的四个组成部分。
推理场景下,使用ATC模型转换工具将原始网络模型转换为适配昇腾AI处理器的离线模型后,开发AscendCL应用程序,加载转换好的离线模型文件进行模型推理,该过程中会进行算子的调用执行。
训练场景下,当我们跑训练脚本时,内部实现逻辑将开源框架网络模型下发给Graph Engine进行图编译后,后续的训练流程会进行算子的调用执行。
CANN算子的运行逻辑架构如下:
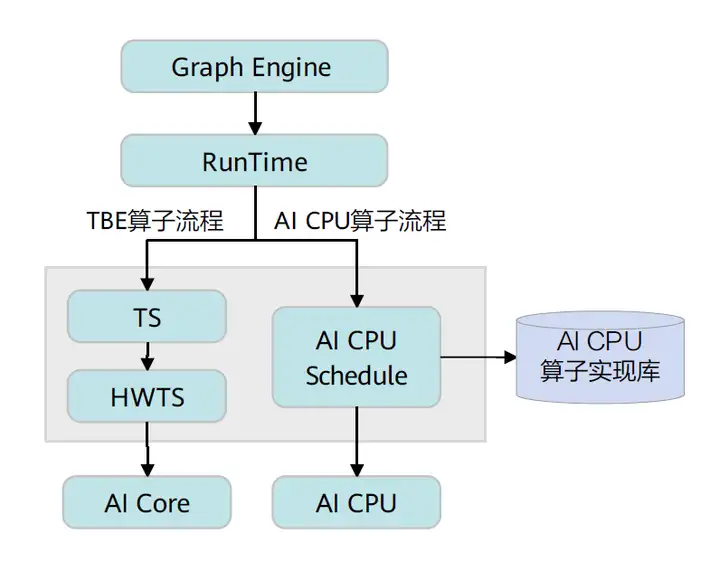
具体流程如下,首先Graph Engine下发算子执行请求给Runtime,然后Runtime会判断算子的Task类型,若是TBE算子,则将算子执行请求下发到AI Core上执行;若是AI CPU算子,则将算子执行请求下发到AI CPU上执行。
本章节以通过DSL开发方式开发一个Add算子为例,带您快速体验CANN算子开发的流程。流程图如下:
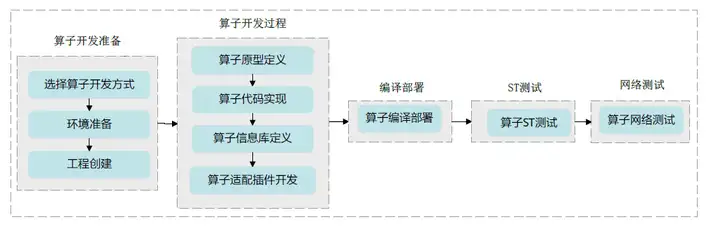
环境准备:准备算子开发及运行验证所依赖的开发环境与运行环境。工程创建:创建算子开发工程,有以下几种实现方式:
下面以msopgen工具创建算子开发工程为例进行介绍:
定义AddDSL算子的原型定义json文件,用于生成AddDSL的算子开发工程。例如,定义的json文件的名字为add_dsl.json,存储路径为:$HOME/sample,文件内容如下:
[ { "op":"AddDSL", "input_desc":[ { "name":"x1", "param_type":"required", "format":[ "NCHW" ], "type":[ "fp16" ] }, { "name":"x2", "param_type":"required", "format":[ "NCHW" ], "type":[ "fp16" ] } ], "output_desc":[ { "name":"y", "param_type":"required", "format":[ "NCHW" ], "type":[ "fp16" ] } ] } ]
使用msopgen工具生成AddDSL算子的开发工程。
$HOME/Ascend/ascend-toolkit/latest/python/site-packages/bin/msopgen gen -i $HOME/sample/add_dsl.json -f tf -c ai_core-Ascend310 -out $HOME/sample/AddDsl
“$HOME/Ascend”为CANN软件安装目录;
“-f tf”参数代表选择的原始框架为TensorFlow;
“ai_core-<soc_version>”代表算子在AI Core上运行,<soc_version>为昇腾AI处理器的型号。
此命令执行完后,会在$HOME/sample/AddDsl目录下生成算子工程,工程中包含各交付件的模板文件,编译脚本等,如下所示:
AddDsl ├── build.sh // 编译入口脚本 ├── cmake // 编译解析脚本存放目录 ├── CMakeLists.txt ├── framework // 算子适配插件相关文件存放目录 │ ├── CMakeLists.txt │ └── tf_plugin │ ├── CMakeLists.txt │ └── tensorflow_add_dsl_plugin.cc // 算子适配插件实现文件 ├── op_proto // 算子原型定义相关文件存放目录 │ ├── add_dsl.cc │ ├── add_dsl.h │ └── CMakeLists.txt ├── op_tiling │ └── CMakeLists.txt ├── scripts // 自定义算子工程打包脚本存放目录 └── tbe ├── CMakeLists.txt ├── impl // 算子代码实现 │ └── add_dsl.py └── op_info_cfg // 算子信息库存放目录 └── ai_core └── <soc_version> └── add_dsl.ini
实现AddDSL算子的原型定义。
算子原型定义文件包含算子注册代码的头文件(*.h)以及实现基本校验、Shape推导的实现文件(*.cc)。
在IMPLEMT_COMMON_INFERFUNC(AddDSLInferShape)函数中,填充推导输出描述的代码,针对AddDSL算子,输出Tensor的描述信息与输入Tensor的描述信息相同,所以直接将任意一个输入Tensor的描述赋給输出Tensor即可。
IMPLEMT_COMMON_INFERFUNC(AddDSLInferShape) { // 获取输出数据描述 TensorDesc tensordesc_output = op.GetOutputDescByName("y"); tensordesc_output.SetShape(op.GetInputDescByName("x1").GetShape()); tensordesc_output.SetDataType(op.GetInputDescByName("x1").GetDataType()); tensordesc_output.SetFormat(op.GetInputDescByName("x1").GetFormat()); //直接将输入x1的Tensor描述信息赋给输出 (void)op.UpdateOutputDesc("y", tensordesc_output); return GRAPH_SUCCESS; }
在IMPLEMT_VERIFIER(AddDSL, AddDSLVerify)函数中,填充算子参数校验代码。
IMPLEMT_VERIFIER(AddDSL, AddDSLVerify) { // 校验算子的两个输入的数据类型是否一致,若不一致,则返回失败。 if (op.GetInputDescByName("x1").GetDataType() != op.GetInputDescByName("x2").GetDataType()) { return GRAPH_FAILED; } return GRAPH_SUCCESS; }
实现AddDSL算子的计算逻辑。
“tbe/impl/add_dsl.py”文件中已经自动生成了算子代码的框架,开发者需要在此文件中修改add_dsl_compute函数,实现此算子的计算逻辑。
add_dsl_compute函数的实现代码如下:
@register_op_compute("add_dsl") def add_dsl_compute(x1, x2, y, kernel_name="add_dsl"): # 调用dsl的vadd计算接口 res = tbe.vadd(x1, x2) return res
配置算子信息库。
算子信息库的路径为“tbe/op_info_cfg/ai_core/<soc_version>/add_dsl.ini”,包含了算子的类型,输入输出的名称、数据类型、数据排布格式等信息,msopgen工具已经根据add_dsl.json文件将上述内容自动填充,开发者无需修改。
AddDSL算子的信息库如下:
[AddDSL] // 算子的类型 input0.name=x1 // 第一个输入的名称 input0.dtype=float16 // 第一个输入的数据类型 input0.paramType=required // 代表此输入必选,且仅有一个 input0.format=NCHW // 第一个输入的数据排布格式 input1.name=x2 // 第二个输入的名称 input1.dtype=float16 // 第二个输入的数据类型 input1.paramType=required // 代表此输入必选,且仅有一个 input1.format=NCHW // 第二个输入的数据排布格式 output0.name=y // 算子输出的名称 output0.dtype=float16 // 算子输出的数据类型 output0.paramType=required // 代表此输出必选,有且仅有一个 output0.format=NCHW // 算子输出的数据排布格式 opFile.value=add_dsl // 算子实现文件的名称 opInterface.value=add_dsl // 算子实现函数的名称
实现算子适配插件。
算子适配插件实现文件的路径为“framework/tf_plugin/tensorflow_add_dsl_plugin.cc”,针对原始框架为TensorFlow的算子,CANN提供了自动解析映射接口“AutoMappingByOpFn”,如下所示:
#include "register/register.h" namespace domi { // register op info to GE REGISTER_CUSTOM_OP("AddDSL") // CANN算子的类型 .FrameworkType(TENSORFLOW) // type: CAFFE, TENSORFLOW .OriginOpType("AddDSL") // 原始框架模型中的算子类型 .ParseParamsByOperatorFn(AutoMappingByOpFn); //解析映射函数 } // namespace domi
以上为工程自动生成的代码,开发者仅需要修改.OriginOpType("AddDSL")中的算子类型即可。此处我们仅展示算子开发流程,不涉及原始模型,我们不做任何修改。
至此,AddDSL算子的所有交付件都已开发完毕。
算子开发过程完成后,需要编译自定义算子工程,生成自定义算子安装包并进行自定义算子包的安装,将自定义算子部署到算子库。
算子工程编译
1. 修改build.sh脚本,配置算子编译所需环境变量。
将build.sh中环境变量ASCEND_TENSOR_COMPILER_INCLUDE配置为CANN软件头文件所在路径。
修改前,环境变量配置的原有代码行如下:
# export ASCEND_TENSOR_COMPILER_INCLUDE=/usr/local/Ascend/ascend-toolkit/latest/compiler/include
修改后,新的代码行如下:
export ASCEND_TENSOR_COMPILER_INCLUDE=${INSTALL_DIR}/include
${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。例如,若安装的Ascend-cann-toolkit软件包,则安装后文件存储路径为:$HOME/Ascend/ascend-toolkit/latest。
2. 在算子工程目录下执行如下命令,进行算子工程编译。
./build.sh
编译成功后,会在当前目录下创建build_out目录,并在build_out目录下生成自定义算子安装包custom_opp_<target os>_<target architecture>.run。
自定义算子安装包部署
以运行用户执行如下命令,安装自定义算子包。
./custom_opp_<target os>_<target architecture>.run
命令执行成功后,自定义算子包中的相关文件部署到CANN算子库中。
算子包部署完成后,可以进行ST测试(System Test)和网络测试,对算子进行运行验证。
ST测试
ST测试的主要功能是:基于算子测试用例定义文件*.json生成单算子的om文件;使用AscendCL接口加载并执行单算子om文件,验证算子执行结果的正确性。ST测试会覆盖算子实现文件,算子原型定义与算子信息库,不会对算子适配插件进行测试。
网络测试
你可以将算子加载到网络模型中进行整网的推理验证,验证自定义算子在网络中运行结果是否正确。网络测试会覆盖算子开发的所有交付件,包含实现文件,算子原型定义、算子信息库以及算子适配插件。
具体的验证过程请参考“昇腾文档中心”。
以上就是CANN自定义算子开发的相关知识点,您也可以在“昇腾社区在线课程”板块学习视频课程,学习过程中的任何疑问,都可以在“昇腾论坛”互动交流!
[1]昇腾文档中心
[2]昇腾社区在线课程
[3]昇腾论坛