摘要:该方法的主要思想是使用数值较大的排在前面的梯度进行反向传播,可以认为是一种在线难例挖掘方法,该方法使模型讲注意力放在较难学习的样本上,以此让模型产生更好的效果。
本文分享自华为云社区《ATK Loss论文复现与代码实战》,作者:李长安。
损失是一种非常通用的聚合损失,其可以和很多现有的定义在单个样本上的损失 结合起来,如logistic损失,hinge损失,平方损失(L2),绝对值损失(L1)等等。通过引入自由度 k,损失可以更好的拟合数据的不同分布。当数据存在多分布或类别分布不均衡的时候,最小化平均损失会牺牲掉小类样本以达到在整体样本集上的损失最小;当数据存在噪音或外点的时候,最大损失对噪音非常的敏感,学习到的分类边界跟Bayes最优边界相差很大;当采取损失最为聚合损失的时候(如k=10),可以更好的保护小类样本,并且其相对于最大损失而言对噪音更加鲁棒。所以我们可以推测:最优的k即不是k = 1(对应最大损失)也不是k = n(对应平均损失),而是在[1, n]之间存在一个比较合理的k的取值区间。
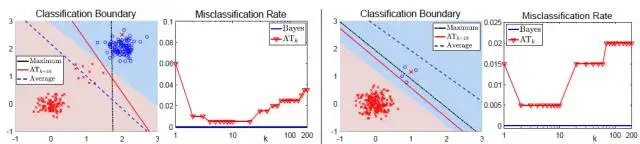
上图结合仿真数据显示了最小化平均损失和最小化最大损失分别得到的分类结果。可以看出,当数据分布不均衡或是某类数据存在典型分布和非典型分布的时候,最小化平均损失会忽略小类分布的数据而得到次优的结果;而最大损失对样本噪音和外点(outliers)非常的敏感,即使数据中仅存在一个外点也可能导致模型学到非常糟糕的分类边界;相比于最大损失损失,第k大损失对噪音更加鲁棒,但其在k > 1时非凸非连续,优化非常困难。
由于真实数据集非常复杂,可能存在多分布性、不平衡性以及噪音等等,为了更好的拟合数据的不同分布,我们提出了平均Top-K损失作为一种新的聚合损失。

本项目最初的思路来自于八月份参加比赛的时候。由于数据集复杂,所以就在想一些难例挖掘的方法。看看这个方法能否带来一个更好的模型效果。该方法的主要思想是使用数值较大的排在前面的梯度进行反向传播,可以认为是一种在线难例挖掘方法,该方法使模型讲注意力放在较难学习的样本上,以此让模型产生更好的效果。代码如下所示。
class topk_crossEntrophy(nn.Layer): def __init__(self, top_k=0.6): super(topk_crossEntrophy, self).__init__() self.loss = nn.NLLLoss() self.top_k = top_k self.softmax = nn.LogSoftmax() return def forward(self, inputs, target): softmax_result = self.softmax(inputs) loss1 = paddle.zeros([1]) for idx, row in enumerate(softmax_result): gt = target[idx] pred = paddle.unsqueeze(row, 0) cost = self.loss(pred, gt) loss1 = paddle.concat((loss1, cost), 0) loss1 = loss1[1:] if self.top_k == 1: valid_loss1 = loss1 index = paddle.topk(loss1, int(self.top_k * len(loss1))) valid_loss1 = loss1[index[1]] return paddle.mean(valid_loss1)复制
此部分使用比赛中的数据集,并带领大家使用Top-k Loss完成模型训练。在本例中使用前70%的Loss。
!cd 'data/data107306' && unzip -q img.zip # 导入所需要的库 from sklearn.utils import shuffle import os import pandas as pd import numpy as np from PIL import Image import paddle import paddle.nn as nn from paddle.io import Dataset import paddle.vision.transforms as T import paddle.nn.functional as F from paddle.metric import Accuracy import warnings warnings.filterwarnings("ignore") # 读取数据 train_images = pd.read_csv('data/data107306/img/df_all.csv') train_images = shuffle(train_images) # 划分训练集和校验集 all_size = len(train_images) train_size = int(all_size * 0.9) train_image_list = train_images[:train_size] val_image_list = train_images[train_size:] train_image_path_list = train_image_list['image'].values label_list = train_image_list['label'].values train_label_list = paddle.to_tensor(label_list, dtype='int64') val_image_path_list = val_image_list['image'].values val_label_list1 = val_image_list['label'].values val_label_list = paddle.to_tensor(val_label_list1, dtype='int64') # 定义数据预处理 data_transforms = T.Compose([ T.Resize(size=(448, 448)), T.Transpose(), # HWC -> CHW T.Normalize( mean = [0, 0, 0], std = [255, 255, 255], to_rgb=True) ]) # 构建Dataset class MyDataset(paddle.io.Dataset): """ 步骤一:继承paddle.io.Dataset类 """ def __init__(self, train_img_list, val_img_list,train_label_list,val_label_list, mode='train'): """ 步骤二:实现构造函数,定义数据读取方式,划分训练和测试数据集 """ super(MyDataset, self).__init__() self.img = [] self.label = [] self.valimg = [] self.vallabel = [] # 借助pandas读csv的库 self.train_images = train_img_list self.test_images = val_img_list self.train_label = train_label_list self.test_label = val_label_list # self.mode = mode if mode == 'train': # 读train_images的数据 for img,la in zip(self.train_images, self.train_label): self.img.append('data/data107306/img/imgV/'+img) self.label.append(la) else : # 读test_images的数据 for img,la in zip(self.test_images, self.test_label): self.img.append('data/data107306/img/imgV/'+img) self.label.append(la) def load_img(self, image_path): # 实际使用时使用Pillow相关库进行图片读取即可,这里我们对数据先做个模拟 image = Image.open(image_path).convert('RGB') image = np.array(image).astype('float32') return image def __getitem__(self, index): """ 步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签) """ # if self.mode == 'train': image = self.load_img(self.img[index]) label = self.label[index] return data_transforms(image), label def __len__(self): """ 步骤四:实现__len__方法,返回数据集总数目 """ return len(self.img) #train_loader train_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='train') train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=4, shuffle=True, num_workers=0) #val_loader val_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='test') val_loader = paddle.io.DataLoader(val_dataset, places=paddle.CPUPlace(), batch_size=4, shuffle=True, num_workers=0) from res2net import Res2Net50_vd_26w_4s # 模型封装 model_re2 = Res2Net50_vd_26w_4s(class_dim=4) import paddle.nn.functional as F import paddle modelre2_state_dict = paddle.load("Res2Net50_vd_26w_4s_pretrained.pdparams") model_re2.set_state_dict(modelre2_state_dict, use_structured_name=True) model_re2.train() epochs = 2 optim1 = paddle.optimizer.Adam(learning_rate=3e-4, parameters=model_re2.parameters()) class topk_crossEntrophy(nn.Layer): def __init__(self, top_k=0.7): super(topk_crossEntrophy, self).__init__() self.loss = nn.NLLLoss() self.top_k = top_k self.softmax = nn.LogSoftmax() return def forward(self, inputs, target): softmax_result = self.softmax(inputs) loss1 = paddle.zeros([1]) for idx, row in enumerate(softmax_result): gt = target[idx] pred = paddle.unsqueeze(row, 0) cost = self.loss(pred, gt) loss1 = paddle.concat((loss1, cost), 0) loss1 = loss1[1:] if self.top_k == 1: valid_loss1 = loss1 # print(len(loss1)) index = paddle.topk(loss1, int(self.top_k * len(loss1))) valid_loss1 = loss1[index[1]] return paddle.mean(valid_loss1) topk_loss = topk_crossEntrophy() from numpy import * # 用Adam作为优化函数 for epoch in range(epochs): loss1_train = [] loss2_train = [] loss_train = [] acc1_train = [] acc2_train = [] acc_train = [] for batch_id, data in enumerate(train_loader()): x_data = data[0] y_data = data[1] y_data1 = paddle.topk(y_data, 1)[1] predicts1 = model_re2(x_data) loss1 = topk_loss(predicts1, y_data1) # 计算损失 acc1 = paddle.metric.accuracy(predicts1, y_data) loss1.backward() if batch_id % 1 == 0: print("epoch: {}, batch_id: {}, loss1 is: {}, acc1 is: {}".format(epoch, batch_id, loss1.numpy(), acc1.numpy())) optim1.step() optim1.clear_grad() loss1_eval = [] loss2_eval = [] loss_eval = [] acc1_eval = [] acc2_eval = [] acc_eval = [] for batch_id, data in enumerate(val_loader()): x_data = data[0] y_data = data[1] y_data1 = paddle.topk(y_data, 1)[1] predicts1 = model_re2(x_data) loss1 = topk_loss(predicts1, y_data1) loss1_eval.append(loss1.numpy()) # 计算acc acc1 = paddle.metric.accuracy(predicts1, y_data) acc1_eval.append(acc1) if batch_id % 100 == 0: print('************Eval Begin!!***************') print("epoch: {}, batch_id: {}, loss1 is: {}, acc1 is: {}".format(epoch, batch_id, loss1.numpy(), acc1.numpy())) print('************Eval End!!***************')复制