摘要:GaussDB目前采用的FIFO调度机制,该调度机制无法满足用户的网络隔离需求和QoS需求,同时FIFO调度可能带来比较严重的抖动。
本文分享自华为云社区《【玩转PB级数仓GaussDB(DWS)】GaussDB(DWS)网络调度与隔离管控能力》,作者:门前一棵葡萄树 。
QoS(Quality of Service)即服务质量,是一种调度控制机制,是网络设计和运维的重要技术。在带宽资源有限情况下,针对不同用户/业务采用不同的调度策略,为任务提供端到端的服务质量保证。QoS本身并不会拓展带宽,提升网络吞吐量,相反设计不合理的调度反而有可能降低整体吞吐量。QoS的一个关键点是允许不平等的网络调度,降低时延要求低、性能和抖动不敏感的业务调度优先级,优先调度时延要求高、带宽要求一般不高的业务。
调度器是实现QoS的关键,调度器根据优先级和带宽配比进行业务调度。调度器的输入是要提供服务的数据包队列,输出是完成调度输出的一个个数据包。调度算法是调度器的核心,设计调度算法要充分考虑业务场景和用户需求,没有万能的调度算法,只有合适的调度算法。常见的调度算法有很多,这里我们只简单介绍GaussDB网络调度涉及的调度算法:
FIFO(First In Forst Out)调度使用的是FCFS策略,是一种不考虑QoS的调度算法。FIFO调度不进行报文分类,所有业务共用一个队列,按照请求进入队列顺序进行调度。如下图所示,三种不同业务的请求全部加入到一个队列中,按照FIFO的规则进行调度。
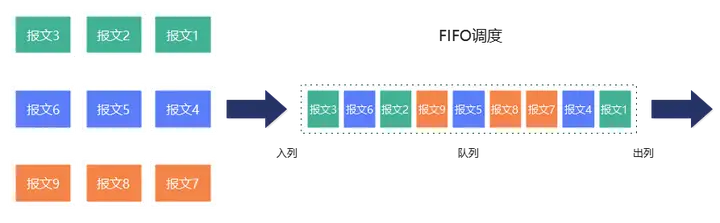
FIFO调度实现简单、开销小,但是FIFO不区分请求类型、不考虑QoS,对时延、抖动敏感的业务不友好,无法保证关键业务服务质量。
SP(Strict Priority)严格优先级调度严格按照队列优先级进行调度,只有在高优先级队列中请求全部调度完成的情况下,才会考虑调度低优先级队列中的请求。如下图所示,三种不同业务分别对应三种不同优先级的队列:高优队列、中优队列和低优队列。不同业务的请求分别加入到相应优先级队列中,调度时优先调度高优队列请求,高优队列中请求调度完成后,依次调度中优和低优队列请求。
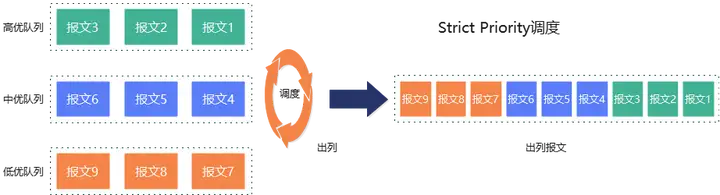
SP调度算法的实现比较简单,优点是可以保证关键业务可以优先调度到,可以最大限度的降低网络延迟和抖动;缺点是网络拥塞,高优先级队列中一直有请求时,会导致低优先级队列中请求一直调度不到,出现“饿死”的情况。
RR(Round Robin)轮询调度通常采用分时机制,为每个队列分配一个时间片或调度时刻。RR调度按照固定顺序循环调度每一个队列中的请求,每次调度相同数量(一般是1个)的请求,且在调度过程中不考虑任何优先级。算法较为简单且容易实现,同时不会产生“饿死”问题。如下图所示,RR调度轮询调度队列1/2/3中的请求,每次调度一个队列中的一个请求,直到请求调度完成。
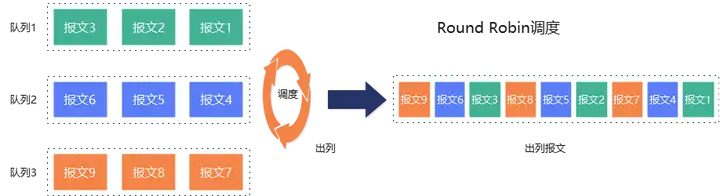
RR调度假设所有队列的优先级和带宽需求都是相同的,调度时不考虑包长、队列时延和带宽需求。队列包长差异比较大时,可能导致不同队列实际占用带宽差异巨大,同时因为不考虑时延和带宽需求,导致无法做到对网络流量的精准隔离和调度。
轮询调度保证了各队列在请求调度时的公平性,但是无法满足个性化的调度需求。WRR(Weighted Round Robin)加权轮询调度在轮询的基础上为队列增加权重,每个队列设置一个计数器,根据权重初始化计数器初始值,每调度一个报文,计数器减1。权重越大,每次轮询调度次数越多,能调度的包数量也就越多。如下图所示,三个队列权重分别是3:2:1,每一轮调度的包数量比例就是3:2:1。
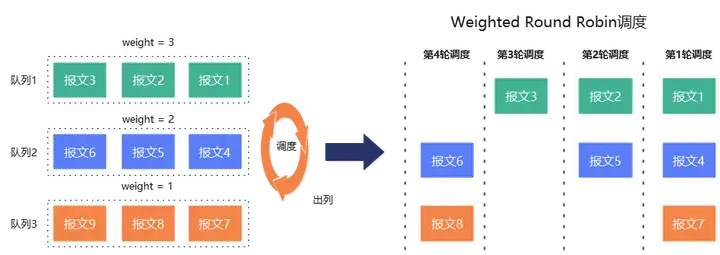
当所有队列权重值都是1时,WRR调度退化为RR调度。WRR的优点是可以按比例调度各个队列的请求,适应性更强,但是由于调度时没有考虑包长,还是按照请求个数进行调度,在请求长度变化时无法保证各队列按照设置比例占用带宽,而用户一般关心和感知到的是带宽。此外队列请求长度不一致时,WRR调度对请求长度较小的队列带来不公平性。
为了解决队列请求长度不一致带来的不公平性,DWRR(Deficit Weighted Round Robin)差分加权轮询调度在WRR基础上,基于请求长度而非请求个数设置权值,按照权重和请求长度进行调度。DWRR为每个队列设置一个计数器,计数器初始化为weight * MTU,每次调度计数器减去请求长度。具体算法逻辑如下:
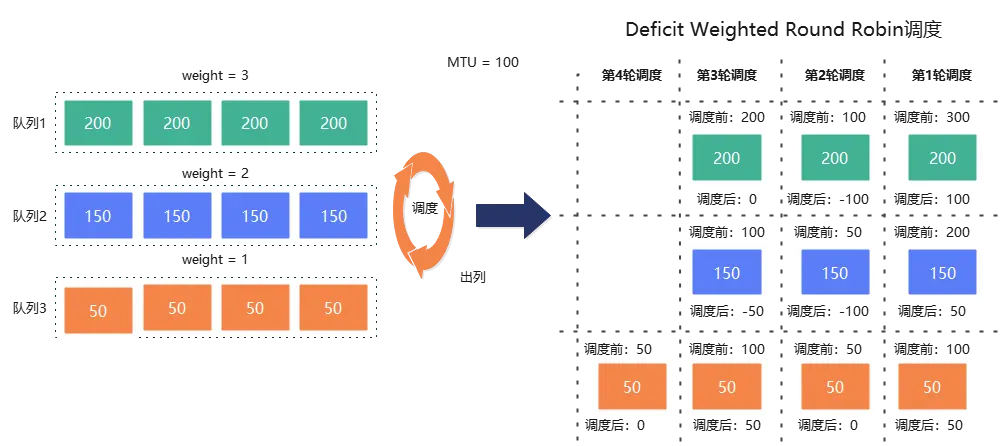
DWRR调度克服了请求长度变化带来的不公平性,提供了更为精准的带宽分配。但是队列数量较大或者MTU设置较大时,调度器完成一轮调度的时间可能比较长,这样可能会引发较大的传输时延抖动,此外DWRR调度无法满足高优队列优先调度的需求。
SP调度可能出现“饿死”问题,同时不能实现带宽按比例调度;而DWRR调度可以实现带宽的按比例调度,同时解决了“饿死”问题,但是无法满足高优业务优先调度的需求。因此结合SP调度和DWRR调度的优点,实现SP+DWRR的调度。调度时优先保证SP调度,在高优队列无请求调度时,才尝试调度低优队列请求。如下图所示,SP调度高优队列、低优队列和普通队列,队列优先级为:高优队列 > 普通队列 > 低优队列。
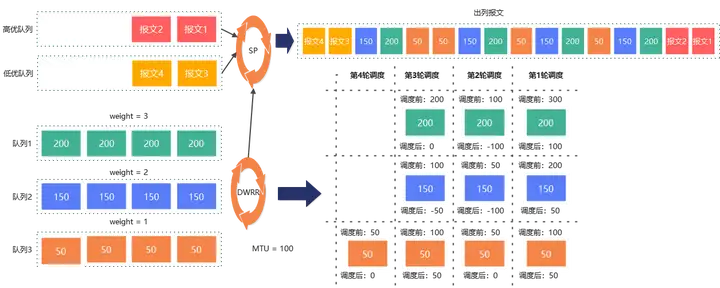
队列1/2/3按照配置权重值进行DWRR调度,高优队列、低优队列和普通队列间按照SP算法进行调度。高优队列无请求调度时,尝试调用普通队列组内的请求,在普通队列组内所有队列均无请求时,才调度低优队列请求。
GaussDB目前采用的FIFO调度机制,该调度机制无法满足用户的网络隔离需求和QoS需求,同时FIFO调度可能带来比较严重的抖动。抖动来自两方面:一方面是不同业务争取同一队列引发的入列时延损耗,另一方面是队列内请求数量变化带来的调度时延变化。因此为了满足用户个性化的网络隔离需求和QoS需求,设计实现GaussDB网络调度。
GaussDB的网络调度有三层需求:
考虑到以上需求,我们采用SP+DWRR调度算法设计实现GaussDB的网络调度,同时考虑到队列数量变化及MTU设置带来的时延影响,对DWRR调度进行改进,每次获取最优队列进行调度(性能损耗较大,但是可以优化改进)。
设计实现三种优先级队列:高优队列、普通队列和低优队列。三种队列优先级顺序为:高优队列 > 普通队列 > 低优队列。三类队列调度的业务类型如下:
GaussDB基于DWRR实现的网络隔离属于配额共享的资源隔离,区别于限流的网络隔离,该隔离方案在保障资源池间网络隔离和带宽占比的前提下,可以最大化地利用网络带宽,有效降低网络隔离对网络吞吐量的影响。GaussDB配额共享的网络隔离有两层含义:
基于SP调度机制实现的网络降级有以下优点:
SP调度可能出现“饿死”情况,因此一般情况下,用户在设计网络隔离方案时,不建议有资源池不设置网络管控参数(带宽权重)。此外网络欠佳SQL降级后如果出现“饿死”情况,一般说明网络带宽资源紧张,需要进行错峰调度或配置并发管控。
考虑一个比较简单的客户场景:用户自定义两个资源池rp1和rp2,两个资源池带宽权重分别配置为4和2,同时配置默认资源池带宽权重值为1。
ALTER RESOURCE POOL rp1 WITH(WEIGHT=4);
ALTER RESOURCE POOL rp2 WITH(WEIGHT=2);
ALTER RESOURCE POOL default_pool WITH(WEIGHT=1);
配置完成后,在三个队列都有请求的情况下,rp1、rp2和default_pool会按照4:2:1的比例进行网络请求调度。网络拥塞,三个队列都有调度不完的请求情况下,rp1占用4/7的带宽,rp2占用2/7的带宽,default_pool占用1/7的带宽。在有队列无请求情况下,其他有请求的队列按照权重配比抢占网络带宽。
设置查询运行超过20min,且网络带宽占用超过512MB时降级:
CREATE EXCEPT RULE bandwidth_rule1 WITH(bandwidth=512, ELAPSEDTIME=1200, action='penalty');
设置查询运行超过30min,且网络带宽占用超过1GB时降级:
CREATE EXCEPT RULE bandwidth_rule2 WITH(bandwidth=1024, ELAPSEDTIME=1800, action='abort');
资源池关联异常规则:
ALTER RESOURCE POOL rp1 WITH(EXCEPT_RULE='bandwidth_rule1, bandwidth_rule2');
关联资源池rp1的用户执行的查询,如果运行时间超过20min,且占用带宽超过512MB时查询即被降级,降级后该查询网络请求由低优队列调度,为了防止报文错乱,降级不可恢复;如果运行时间超过30min,且占用带宽超过1GB时查询即被查杀。
资源池监控视图集成了网络收发速率监控,可以通过查询资源池监控对各资源池网络收发流量进行监控:
查询当前CN/DN上网络收发速率:SELECT rpname,send_speed,recv_speed FROM gs_respool_resource_info;
查询所有CN/DN上网络收发速率:SELECT nodename,rpname,send_speed,recv_speed FROM pgxc_respool_resource_info order by 1,2;
通过资源池网络监控视图可以直观地观察到资源池网络隔离效果,同时对资源池带宽权重配置优化配置进行指导。