摘要:tcp_nodelay参数主要是对TCP套接字来说的,那对于服务器硬件,如果要使其能够支撑上百万甚至上千万的并发,我们该如何对其进行优化呢?
本文分享自华为云社区《【高并发】高并发场景下如何优化服务器的性能?》,作者: 冰 河 。
最近,有小伙伴在群里提问:Linux系统怎么设置tcp_nodelay参数?也有小伙伴说问我。那今天,我们就来根据这个问题来聊聊在高并发场景下如何优化服务器的性能这个话题。
其实,tcp_nodelay参数并不是在操作系统级别进行配置的,而是在TCP套接字上添加tcp_nodelay参数来关闭粘包算法,以便使数据包能够立即投递出去。tcp_nodelay参数主要是对TCP套接字来说的,那对于服务器硬件,如果要使其能够支撑上百万甚至上千万的并发,我们该如何对其进行优化呢?
这里,我使用的操作系统为CentOS 8,我们可以输入如下命令来查看操作系统的版本。
CentOS Linux release 8.0.1905 (Core)复制
对于高并发的场景,我们主要还是优化操作系统的网络性能,而操作系统中,有很多关于网络协议的参数,我们对于服务器网络性能的优化,主要是对这些系统参数进行调优,以达到提升我们应用访问性能的目的。
在CentOS 操作系统中,我们可以通过如下命令来查看所有的系统参数。
/sbin/sysctl -a复制
部分输出结果如下所示。
这里的参数太多了,大概有一千多个,在高并发场景下,我们不可能对操作系统的所有参数进行调优。我们更多的是关注与网络相关的参数。如果想获得与网络相关的参数,那么,我们首先需要获取操作系统参数的类型,如下命令可以获取操作系统参数的类型。
/sbin/sysctl -a|awk -F "." '{print $1}'|sort -k1|uniq复制
运行命令输出的结果信息如下所示。
abi crypto debug dev fs kernel net sunrpc user vm复制
其中的net类型就是我们要关注的与网络相关的操作系统参数。我们可以获取net类型下的子类型,如下所示。
/sbin/sysctl -a|grep "^net."|awk -F "[.| ]" '{print $2}'|sort -k1|uniq复制
输出的结果信息如下所示。
bridge core ipv4 ipv6 netfilter nf_conntrack_max unix复制

在Linux操作系统中,这些与网络相关的参数都可以在/etc/sysctl.conf 文件里修改,如果/etc/sysctl.conf 文件中不存在这些参数,我们可以自行在/etc/sysctl.conf 文件中添加这些参数。
在net类型的子类型中,我们需要重点关注的子类型有:core和ipv4。
如果服务器的网络套接字缓冲区太小,就会导致应用程序读写多次才能将数据处理完,这会大大影响我们程序的性能。如果网络套接字缓冲区设置的足够大,从一定程度上能够提升我们程序的性能。
我们可以在服务器的命令行输入如下命令,来获取有关服务器套接字缓冲区的信息。
/sbin/sysctl -a|grep "^net."|grep "[r|w|_]mem[_| ]"复制
输出的结果信息如下所示。
net.core.rmem_default = 212992 net.core.rmem_max = 212992 net.core.wmem_default = 212992 net.core.wmem_max = 212992 net.ipv4.tcp_mem = 43545 58062 87090 net.ipv4.tcp_rmem = 4096 87380 6291456 net.ipv4.tcp_wmem = 4096 16384 4194304 net.ipv4.udp_mem = 87093 116125 174186 net.ipv4.udp_rmem_min = 4096 net.ipv4.udp_wmem_min = 4096复制
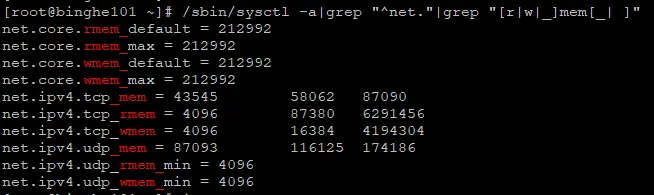
其中,带有max、default、min关键字的为分别代表:最大值、默认值和最小值;带有mem、rmem、wmem关键字的分别为:总内存、接收缓冲区内存、发送缓冲区内存。
这里需要注意的是:带有rmem 和 wmem关键字的单位都是“字节”,而带有mem关键字的单位是“页”。“页”是操作系统管理内存的最小单位,在 Linux 系统里,默认一页是 4KB 大小。
如果在高并发场景下,需要频繁的收发大文件,我们该如何优化服务器的性能呢?
这里,我们可以修改的系统参数如下所示。
net.core.rmem_default net.core.rmem_max net.core.wmem_default net.core.wmem_max net.ipv4.tcp_mem net.ipv4.tcp_rmem net.ipv4.tcp_wmem复制
这里,我们做个假设,假设系统最大可以给TCP分配 2GB 内存,最小值为 256MB,压力值为 1.5GB。按照一页为 4KB 来计算, tcp_mem 的最小值、压力值、最大值分别是 65536、393216、524288,单位是“页” 。
假如平均每个文件数据包为 512KB,每个套接字读写缓冲区最小可以各容纳 2 个数据包,默认可以各容纳 4 个数据包,最大可以各容纳 10 个数据包,那我们可以算出 tcp_rmem 和 tcp_wmem 的最小值、默认值、最大值分别是 1048576、2097152、5242880,单位是“字节”。而 rmem_default 和 wmem_default 是 2097152,rmem_max 和 wmem_max 是 5242880。
注:后面详细介绍这些数值是如何计算的~~
这里,还需要注意的是:缓冲区超过了 65535,还需要将 net.ipv4.tcp_window_scaling 参数设置为 1。
经过上面的分析后,我们最终得出的系统调优参数如下所示。
net.core.rmem_default = 2097152 net.core.rmem_max = 5242880 net.core.wmem_default = 2097152 net.core.wmem_max = 5242880 net.ipv4.tcp_mem = 65536 393216 524288 net.ipv4.tcp_rmem = 1048576 2097152 5242880 net.ipv4.tcp_wmem = 1048576 2097152 5242880复制
对计算机网络有一定了解的小伙伴都知道,TCP的连接需要经过“三次握手”和“四次挥手”的,还要经过慢启动、滑动窗口、粘包算法等支持可靠性传输的一系列技术支持。虽然,这些能够保证TCP协议的可靠性,但有时这会影响我们程序的性能。
那么,在高并发场景下,我们该如何优化TCP连接呢?
如果用户对于请求的耗时很敏感,我们就需要在TCP套接字上添加tcp_nodelay参数来关闭粘包算法,以便数据包能够立刻发送出去。此时,我们也可以设置net.ipv4.tcp_syncookies的参数值为1。
网络连接的创建和回收是非常消耗性能的,我们可以通过关闭空闲的连接、重复利用已经分配的连接资源来优化服务器的性能。重复利用已经分配的连接资源大家其实并不陌生,像:线程池、数据库连接池就是复用了线程和数据库连接。
我们可以通过如下参数来关闭服务器的空闲连接和复用已分配的连接资源。
net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_fin_timeout = 30 net.ipv4.tcp_keepalive_time=1800复制
TCP支持超时重传机制。如果发送方将数据包已经发送给接收方,但发送方并未收到反馈,此时,如果达到设置的时间间隔,就会触发TCP的超时重传机制。为了避免发送成功的数据包再次发送,我们需要将服务器的net.ipv4.tcp_sack参数设置为1。
在Linux操作系统中,一个网络连接也会占用一个文件描述符,连接越多,占用的文件描述符也就越多。如果文件描述符设置的比较小,也会影响我们服务器的性能。此时,我们就需要增大服务器文件描述符的数量。
例如:fs.file-max = 10240000,表示服务器最多可以打开10240000个文件。