摘要: 这篇文章主要目的是为了让大家能够清楚如何用MindSpore2.0来进行模型的迁移。
本文分享自华为云社区《MindNLP-基于Mindspore2.0的GPT2预训练模型迁移教程》,作者: Super_WZB。
大家好,我是Super_WZB,最近MindSpore快要上线2.0版本了,由于之前主要是参与MindSpore的开发工作,一直想找机会多用一用。而自春节开始也是参与到了一项基于MindSpore的迁移工作,积攒了一些经验,搞了一下GPT2的模型迁移工作。目前初步实现了GPT2 Model最基础模型的推理,输出精度能够和hugging face中基于Pytorch的实现完全对标。整个流程我感觉非常的顺利,并且也切实的体会到MindSpore目前已经可以说是从“可用”进化到了“易用”的阶段。出于MindSpore布道师的职责,同时更是自己想要分享MindSpore2.0的使用感受,写下这篇基于MindSpore2.0的模型迁移教程,供大家参考。
这篇文章主要目的是为了让大家能够清楚如何用MindSpore2.0来进行模型的迁移,因此更加注重整体的开发流程介绍,针对迁移中代码的编写不会详细讲解,但是会给出样例以及供查阅的文档链接。最终希望读者能够了解迁移模型需要做什么,每一步应该怎么做,做完了应该怎么验证。话不多说,直接开始:
本章节介绍开发的前期准备工作,简要介绍环境配置、MindSpore安装和寻找迁移参考代码的途径,每一部分的详细操作大家可以百度搜索一下,相关博客非常多,这里就不赘述。这一章节非常的基础,如果已经是老手可以直接跳过。
既然是迁移工作,那么第一件事肯定是确定自己想要迁移的模型,然后找到该模型的开源代码,提供以下几个途径供大家寻找源码,基本上比较知名的模型通过以下几种方式都是可以找到相应代码的:
找到了参考代码之后,大家会发现这些源码基本上都是保存在GitHub上的,因此为了更方便的查阅我们需要迁移的代码,以及跳转和搜索可能存在的依赖函数,我建议大家把参考代码Clone到本地,然后进行对照开发:
常用的git操作可以参考这篇博客:Git的下载、安装与使用
如果大家自己有硬件资源,比如CPU、GPU、服务器,那么可以在自己的电脑本地配置神经网络的运行环境,主要包括以下步骤:
安装anaconda:anaconda是一个非常便捷好用的包管理工具,基本上大家都使用它来管理python运行环境,安装流程参考:anaconda安装-超详细版-CSDN博客
创建并激活虚拟环境:安装好了anaconda之后就可以创建虚拟环境了,之所以要创建自己的虚拟环境是因为不同的项目和开发者需要的运行环境不同,需要的包不同,即使需要同样的包可能需求的版本也不同,因此最好是对每一个项目创建一个单独的虚拟环境,以免影响他人使用,创建虚拟环境流程参考:使用 Anaconda 创建 Python 虚拟环境-CSDN博客
安装依赖包:python开发的一大优势就是有非常多可以直接安装调用的依赖包,这些包中包含了大量奇奇怪怪非常有用的接口,可以大大简化python项目的开发难度。因此大部分基于python的项目都导入了非常多的依赖包,在运行之前必须将它们都安装好否则会报错,依赖包通常采用pip安装的方式,可以从以下几个网址下载:
PyPI · The Python Package Index(官网,不该镜像的话默认从这里下载)
pip更换软件源方法-CSDN博客(如果官网下载异常,可以参考博客切换以下国内镜像)
http://mirrors.aliyun.com/pypi/simple/ (阿里云镜像)
https://pypi.mirrors.ustc.edu.cn/simple/ (中国科技大学镜像)
http://pypi.douban.com/simple/ (豆瓣镜像)
https://pypi.tuna.tsinghua.edu.cn/simple/ (清华大学镜像)
http://pypi.mirrors.ustc.edu.cn/simple/(中科科学技术大学镜像)
OpenI 启智 新一代人工智能开源开放平台
启智AI协作平台,简称启智社区 ,是一个开源在线Web应用,旨在为人工智能算法、模型开发提供在线协同工作环境,它提供了代码托管、数据集管理与共享、免费云端算力资源支持(GPU/NPU)、共享镜像等功能。
启智平台是可以直接在线创建网络运行环境的平台,里面可以白嫖GPU/NPU资源,配置也非常容易,个人感觉非常的好用,如果大家没有自己的硬件资源的话可以创建一个账号,用启智来进行调试:
GPU调试参考:OpenIOSSG/MNIST_PytorchExample_GPU - OpenI - 启智AI开源社区提供普惠算力!
NPU调试参考:OpenIOSSG/MNIST_Example NPU - OpenI - 启智AI开源社区提供普惠算力!
安装之前,请允许我先介绍和宣传一下MindSpore:MindSpore官网介绍
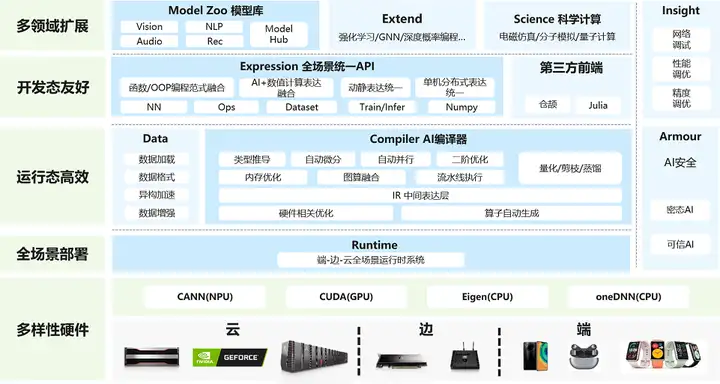
昇思MindSpore是一个全场景深度学习框架,旨在实现易开发、高效执行、全场景覆盖三大目标。
其中,易开发表现为API友好、调试难度低;高效执行包括计算效率、数据预处理效率和分布式训练效率;全场景则指框架同时支持云、边缘以及端侧场景。
昇思MindSpore总体架构如下图所示:
对昇思MindSpore感兴趣的开发者,可以参与昇思MindSpore的社区并一键三连。
MindSpore官网就有非常详细的安装教程,大家可以按照官网的步骤进行安装:
MindSpore安装指南
神经网络其实可以理解为搭积木,而不同框架就可以理解为不同品牌的积木包,比如有乐高、森宝、启蒙等等,不同品牌的积木包中肯定有非常多的积木是类似可代替的。
比如A品牌推出了一个Super Mario超级马里奥的积木套装,而我们手头有B品牌的零散积木,只要我们有了这个Super Mario的搭建步骤图,我们同样可以用B品牌的积木构造出一个基本相同的Super Mario。
那么我们将品牌A替换为框架A、品牌B替换为MindSpore、积木替换为需要用到的API接口,构建图替换为GPT2的论文。那么:
我们有了基于框架A的GPT2模型,而我们手头有MindSpore中大量的可调用接口,那么我们只需要参照GPT2的网络结构图和原论文,就可以用MindSpore写出一个基本相同的GPT2模型,这个过程就是模型迁移。
经过上面的例子,大家应该大致了解网络迁移是在干个什么事情,而实际上网络的迁移工作也非常简单,主要考验开发者对于网络模型构建以及多种深度学习框架的熟悉情况。不过不同的模型网络结构肯定是不相同的,因此本章节只会介绍迁移流程和每一步应该做什么,具体怎么迁移就需要大家读懂源码,然后参照我给出的api映射表具体问题具体分析。
首先介绍一下后续迁移讲解用到的资源情况:
前往huggingface/transformers仓库下载transformers包
之后找到迁移需要用到的configguration_gpt2.py配置文件和modeling_gpt2.py模型文件(没有后缀的一般是pytorch实现,带tf的是tensorflow实现,我个人对于pytorch更熟悉一些所以选择pytorch版本进行迁移)
使用pycharm远程连接,可以直接访问文件代码:
由于迁移之后的源码是需要合入到MindNLP仓库的,因此大家需要去MindNLP官方GitHub仓库进行一键三连(watch+fork+star)
目前MindNLP中已经有了Bert模型的迁移代码,因此我们是可以将这个bert.py与hugging face中的bert代码进行对比来学习应该如何迁移的:
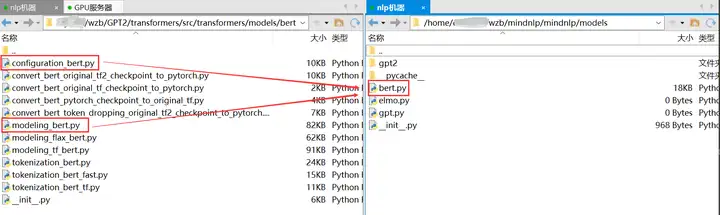
下载好之后同样用pycharm打开,刚下载的mindnlp打开图示的models界面是没有gpt2这个文件夹的,这个是大家需要根据自己的模型创建的,用于存放之后迁移之后的相关文件。我的是GPT2所以创建为gpt2,其他模型同理。
之后在该文件夹下新建init___.py、config_gpt2.py、gpt2.py三个文件,作用分别是:

下载好了参考源码和MindNLP仓库之后我们就可以正式开始网络迁移了,经过上面搭积木的例子,大家其实应该知道我们需要做的其实就是把参考源码中所使用框架(我参考的是pytorch,之后都以它来讲解)的API替换为MindSpore中的API即可。
下面举一个非常简单的例子:
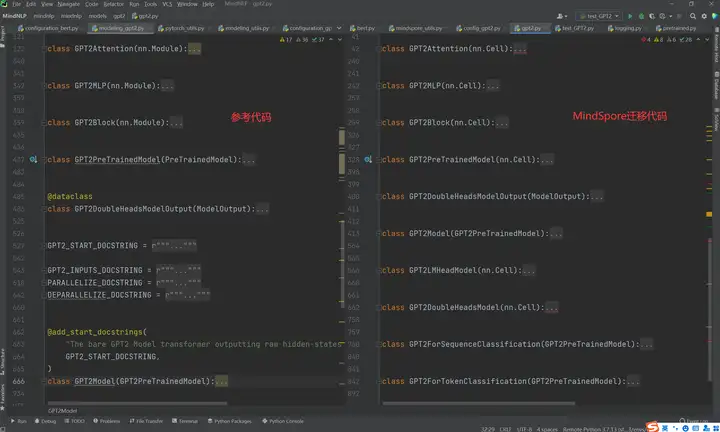
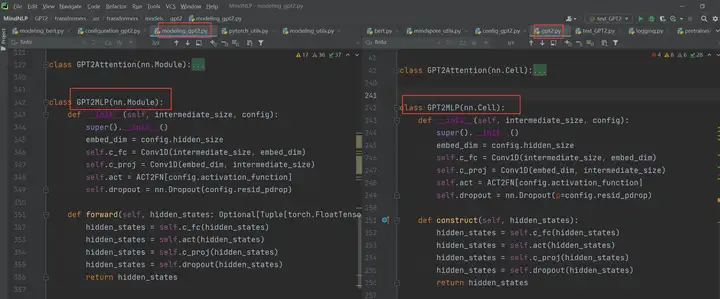
GPT2MLP的迁移:
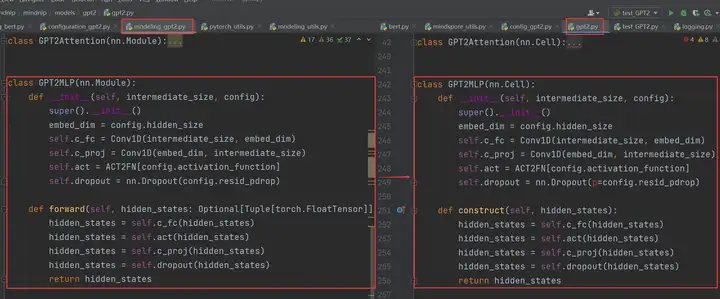
得益于MindSpore中API命令的规范化和统一化,我们可以发现从左边基于pytorch的实现迁移到右边基于mindspore的实现基本上可以直接复制粘贴,图中的Conv1D和ACT2FN是左边hugging face源码自己封装的类别,后面会讲解。而这个GPT2MLP中其他的代码基本上是直接照搬即可,唯一的差异就是这个nn.Dropout()中的参数有些许不同,这个在2.3API差异中会介绍。
通过这一个例子大家会发现其实迁移还是非常简单的,只要把代码逻辑甚至直接把代码搬过来就行了。这得益于目前MindSpore完善的API接口库,大部分神经网络需要用到的接口都是有的,并且对于输入输出等参数的设置也是向大众的一致标准靠齐的,所以会用其他框架就一定能很快的上手MindSpore(打波小广告哈哈哈)。
下面是更多直接API映射的例子:
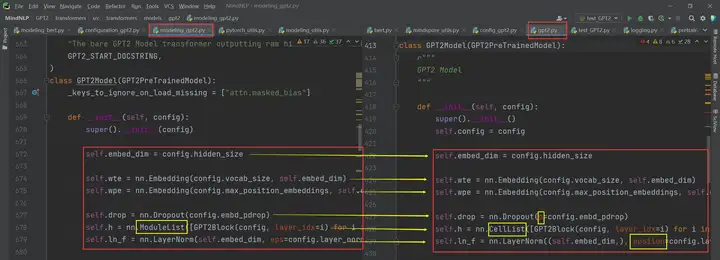
大家会发现,这些直接API映射的例子里面存在一些参数或者名字不对应的情况,这将会在2.3 API差异中为大家讲解。
还是以GPT2MLP举例,其中的Conv1D类别是hugging face实现GPT2时自己封装好的类别:
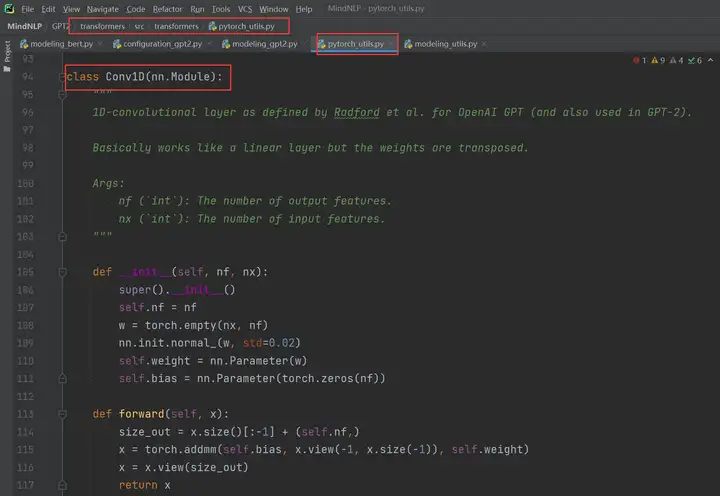
那我们需要做的其实也很简单,把这个类别也迁移过来就好了。而关于这个类别该迁移到哪个文件,这个可以选择迁移到自己的模型文件(即gpt2.py),也可以参照hugging face中的文件路径在MindNLP中相应路径新建文件来保存。我这里以迁移到gpt2.py为例:
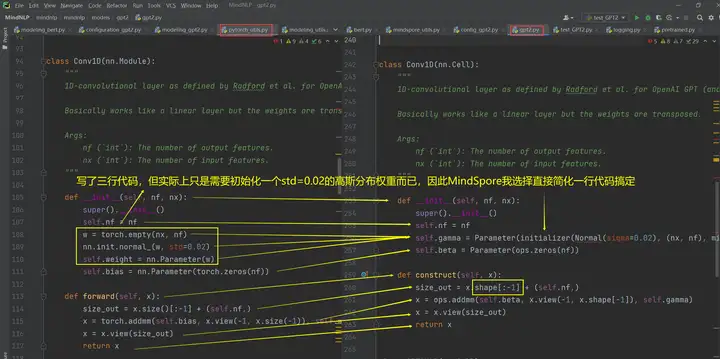
迁移之后呢,这个hugging face自定义的Conv1D类别我们也可以直接使用啦:
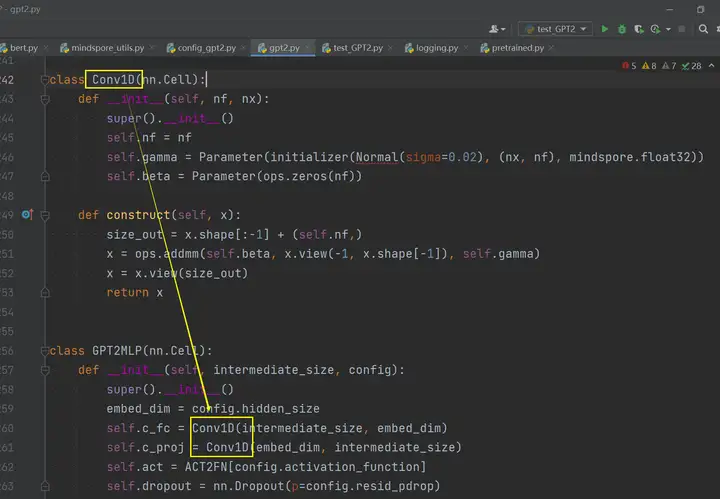
接下来讲一下迁移中出现的API名字或者参数存在差异的问题,API差异主要包括API命名差异、API参数差异、API功能差异。
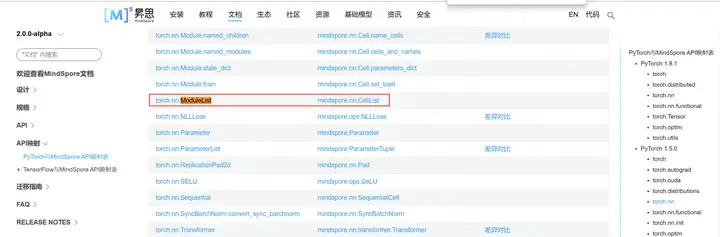
命名差异就是说MindSpore某个接口和pytorch等其他框架的功能是一致的,但是API的名字不同,这时候我们就需要查询pytorch等其他框架中某个API在MindSpore的名字叫啥,而这就需要用到MindSpore官方给出的pytorch/tensorflow API映射表:
可以看到其中收纳了绝大多数常用的API接口,我们只需要在网页中搜索原来pytorch/tensorflow的API名就可以找到MindSpore这边对应的API名字,并且MindSpore这边还非常细致的给出了每个API映射之间的关系,是完全一致、还是存在差异,点赞。
PyTorch与MindSpore API映射表
TensorFlow与MindSpore API映射表
这两张映射表非常重要,是迁移的基础,一定要收藏、一定要收藏、一定要收藏
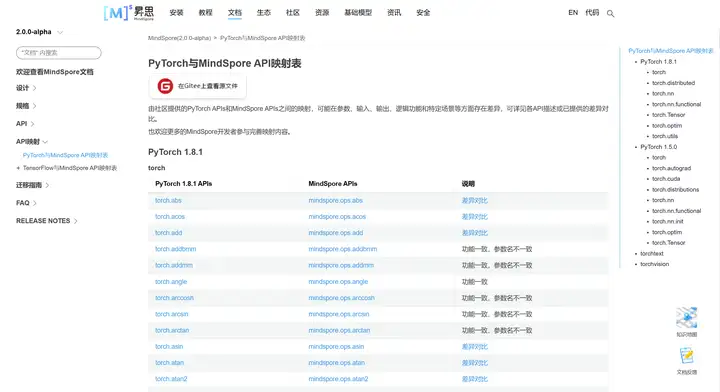
比如这张图中的差异nn.ModuleList是因为Pytorch中网络都继承了nn.Module类别,而MindSpore网络继承的是nn.Cell类别,因此命名有些不同:
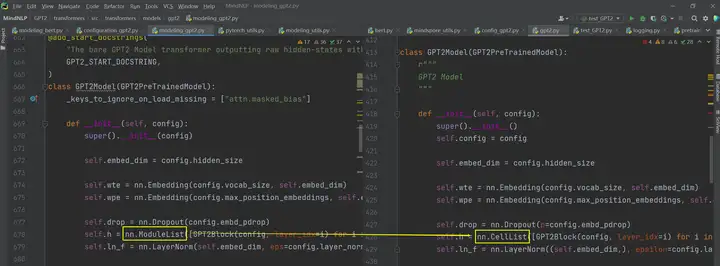
这个差异是可以在映射表中查到的,并且没有显示存在差异,所以我们直接给它替换掉就解决啦:
(1)参数值差异
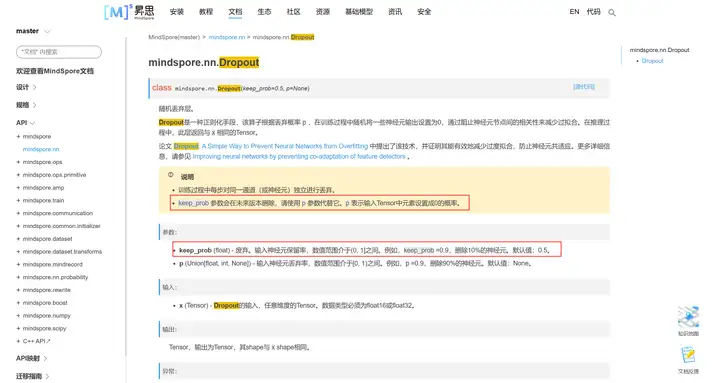
参数值差异是指pytorch/tensorflow与MindSpore中API的名字相同,但是一些参数的名字或者参数的含义不同,导致API在使用时功能会产生差异,比如最经典的nn.Dropout§差异:

PyTorch中默认输入nn.Dropout(0.2)时代表有每个参数有20%的概率被丢弃,而如果在MindSpore中不指定参数名直接输入nn.Dropout(0.2)的话代表每个参数有(1 - 0.2)即80%的概率被丢弃。这就是一个非常经典,如果大家有长期使用MindSpore的话肯定知道的差异,当然最新的版本中已经提示这种默认写法将会删除,之后就也可以直接使用nn.Dropout(0.2)啦:
(2)参数初始化差异
这一块主要是有一些网络API的参数在初始化时存在不同,不要小看初始化的差异,有时候网络结构都是对的,但是结果就是对标补上,很有可能就是某些网络的参数初始化不一样,导致结果大相径庭。
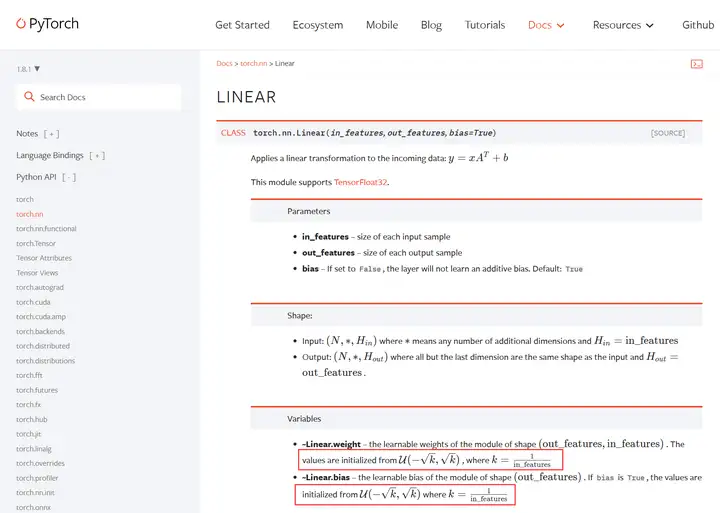
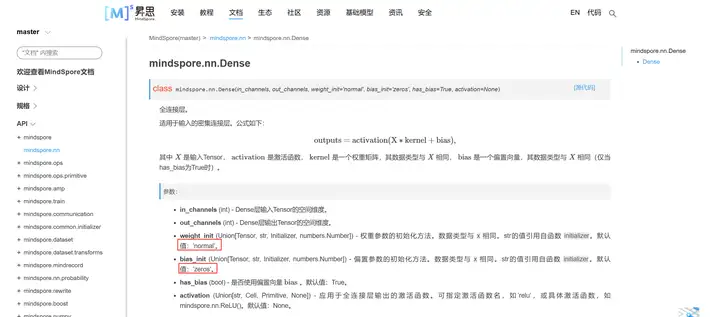
比如将PyTorch线性层nn.Linear()映射为MindSpore线性层nn.Dense():
从Pytorch的官网来看,他的nn.Linear线性层中的weight和bias应该是用均匀分布初始化的
而MindSpore中的nn.Dense线性层中weight使用normal初始化的,而bias使用zeros初始化的
其实大部分的功能差异都是因为2.3.2中参数没设置好,但是也存在一小部分API确实是功能有差异,这里举一个很简单的例子:
torch中的Tensor.transpose在MindSpore中应该是swapaxes

而MindSpore中的Tensor.transpose实际上对应torch.Tensor.permute

所以如果不仔细检查,看到mindspore中有transpose API就直接迁移过来的话最后的结果往往是不正确。因此大家在迁移时一定要仔细核对每一步迁移的API是否是正确的映射,多查表、多查表、多查表!!!
极少出的情况会出现pytorch/tensorflow中的API在MindSpore查不到的情况:
比如mindspore中没有这个finfo API

我们可以用numpy.finfo得到相同的数据之后包装成mindspore.Tensor

Tensor.contiguous()
Tensor.to(device)
清楚了网络迁移应该干什么,以及如何查找对应的API之后,我们就可以对自己迁移的网络进行验证了,验证主要包括两个方面:输出shape验证、输出精度验证,验证流程从小到大依次为单模块验证、整网验证、checkpoint验证。
单模块验证就是对网络中每个单独的模块进行验证,比如对于迁移好的GPT2MLP:
我们需要对它进行测试验证,那怎么做呢?实际上网络说复杂了是网络,说简单点就是一堆函数的拼接,我们测试的一个模块就是一个小的函数,只不过它是一个类别的正向运行函数(forward/construct,只是命名差异,pytorch中叫forward,mindspore中叫construct)罢了。所以想要验证迁移结果是否正确,我们只需要实例化迁移前和迁移后的两个类别,然后给他们的正向运行函数输入相同的数值,再对标两个函数的输出结果即可。以下给出简单的实现:
import numpy as np import modeling_gpt2, gpt2, configuration_gpt2, config_gpt2 if __name__ == "__main__": config_pt = configuration_gpt2.GPT2Config() // 获取pytorch的配置 config_ms = config_gpt2.GPT2Config() // 获取mindspore的配置 pt_net = modeling_gpt2.GPT2MLP(config_pt) // 实例化pytorch的GPT2MLP模块 ms_net = gpt2.GPT2MLP(config_ms) // 实例化mindsproe的GPT2MLP模块 input_np = np.random.randint(0, 10, (2, 512)) // 使用numpy随机生成一个shape为(2, 512)的numpy.array pt_input = torch.tensor(input_np) // 将numpy.array转化为pytorch.Tensor ms_input = mindspore.Tensor(input_np) // 将numpy.array转化为mindspore.Tensor pt_out = pt_net(pt_input) // 调用pytorch正向函数GPT2MLP.forward()计算结果 ms_out = ms_net(ms_input) // 调用mindspore正向函数GPT2MLP.construct()计算结果 assert pt_out.size() == ms_out.shape // 对比pytorch和mindspore输出的shape,必须相同否则迁移出错 loss = 1e-3 // 精度误差一般为1e-5,最大为1e-3,必须小于1e-3否则迁移出错 assert np.allclose(pt_out.detach().numpy(), ms_out.asnumpy(), loss, loss) // 将结果全部转成array然后对比精度复制
最终我们的目的就是要给pytorch和mindspore的两个模块输入相同的数据,他们的输出shape完全一致,精度误差在1e-3之内就代表该模块基本迁移成功了。每个模块都这样子验证正确之后,我们就可以尝试把整个网络搭建起来然后进行验证了
整网验证其实和每个模块测试验证没啥区别,网络说白了就是个大函数,所以就把GPT2MLP改成GPT2Model其实就差不多了,无非就是输出可能多几个。
当然我说的仅仅只是测试代码很好写,和模块测试没啥区别,但是整个网络连起来之后可能会出现单模块测试时未出现的bug,这也很正常,如果出现bug一点点debug检查就好了。
import numpy as np import modeling_gpt2, gpt2, configuration_gpt2, config_gpt2 if __name__ == "__main__": config_pt = configuration_gpt2.GPT2Config() // 获取pytorch的配置 config_ms = config_gpt2.GPT2Config() // 获取mindspore的配置 pt_net = modeling_gpt2.GPT2Model(config_pt) // 实例化pytorch的GPT2MLP模块 ms_net = gpt2.GPT2Model(config_ms) // 实例化mindsproe的GPT2MLP模块 input_np = np.random.randint(0, 10, (2, 512)) // 使用numpy随机生成一个shape为(2, 512)的numpy.array pt_input = torch.tensor(input_np) // 将numpy.array转化为pytorch.Tensor ms_input = mindspore.Tensor(input_np) // 将numpy.array转化为mindspore.Tensor pt_out = pt_net(pt_input) // 调用pytorch正向函数GPT2MLP.forward()计算结果 ms_out = ms_net(ms_input) // 调用mindspore正向函数GPT2MLP.construct()计算结果 assert pt_out.size() == ms_out.shape // 对比pytorch和mindspore输出的shape,必须相同否则迁移出错 loss = 1e-3 // 精度误差一般为1e-5,最大为1e-3,必须小于1e-3否则迁移出错 assert np.allclose(pt_out.detach().numpy(), ms_out.asnumpy(), loss, loss) // 将结果全部转成array然后对比精度复制
最终我们需要达到的目的和模块验证一致,向pytorch和mindspore的整个网络输入相同的数据,最终要求网络输出的个数相同、shape一致、精度误差在1e-3以内。满足以上要求我们就可以进行最后的checkpoint验证了。
以上的验证都是在检查网络的流程以及计算是否正确,而其中网络的参数都是随机初始化的,而为了达到迁移的最终目的:”直接调用训练好的预训练模型,可以达到与原论文相同的结果“。我们必须将预训练好的模型参数checkpoint导入进来,然后在”指定参数“的情况下再进行一次整网验证,如果也能够满足网络输出的个数相同、shape一致、精度误差在1e-3以内的要求,那么我们的checkpoint验证也就成果啦,这就说明这个GPT2Model真正迁移成功了。下面我简要介绍一下应该如何进行checkpoint验证
一般NLP这边的大模型官方是有预训练的参数的,但是有些官方放出来的网站死活就是打不开,因此我还是推荐大家使用hugging face中来下载checkpoint:
以GPT2为例,我们前往GPT2的hugging face网址gpt2 at main (http://huggingface.co),点击其中的Files and version,这个界面存放了gpt2不同版本的配置文件以及模型预训练参数,我使用的是pytorch版本,因此我下载pytorch_model.bin以及pytorch和tensorflow通用的config.json配置文件。
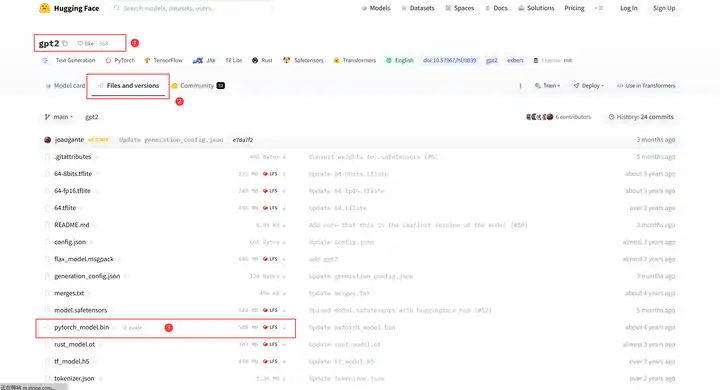
将pytorch_model.bin和config.json上传到服务器的同一个文件夹内:

接下来进行checkpoint的导入和转换
由于我们手上的是pytorch的预训练参数,所以我们先参照hugging face中提供的使用样例将这个pytorch_model.bin导入
(1)导入pytorch预训练参数
import torch from transformers import GPT2Model, GPT2Config model_name = '/home/xxxxxx/wzb/mindnlp/pt_pretrained' // pytorch checkpoint存放路径 model_config = GPT2Config.from_pretrained(model_name) // 导入GPT2配置 pt_net = GPT2Model.from_pretrained(model_name, config=model_config) // 导入GPT2 checkpoint中的参数复制
(2)创建MindSpore的GPT2Model模型
import mindspore from mindnlp.models.gpt2 import gpt2, config_gpt2 ms_config = config_gpt2.GPT2Config() // 获取mindspore GPT2配置 ms_net = gpt2.GPT2Model(config=ms_config) // 创建mindspore GPT2Model复制
(3)核对参数是否对应
获取pytorch和mindspore的网络参数字典,而由于pytorch和mindspore中有部分网络参数的命名不同,所以我们需要核对一下两边的参数是不是都能对应的上:
pt_dict = pt_net.state_dict() // 获取pytorch整网参数字典 ms_dict = ms_net.parameters_dict() // 获取mindspore整网参数字典复制
常见参数命名差异对比

获取了pt_dict和ms_dict之后我们可以将他们打印出来看看参数是否能够对应:
for pt_key in pt_dict: // 打印pytorch所有参数名 print(pt_key) print("+++++++++++++++++++++++++++++++++++++++++") // 分界线 for ms_key in ms_dict: // 打印mindspore所有参数名 print(ms_key)复制
打印出来之后自己人眼核对那可太累了,我推荐大家使用excel来进行比对。由于print()会自动换行,所以我们将pytorch和mindspore的参数复制之后直接粘贴到excel表格中的两列,复制好之后第一件事就是直接看一下两边的参数个数是否相同(查看这两列的行数是否相同):
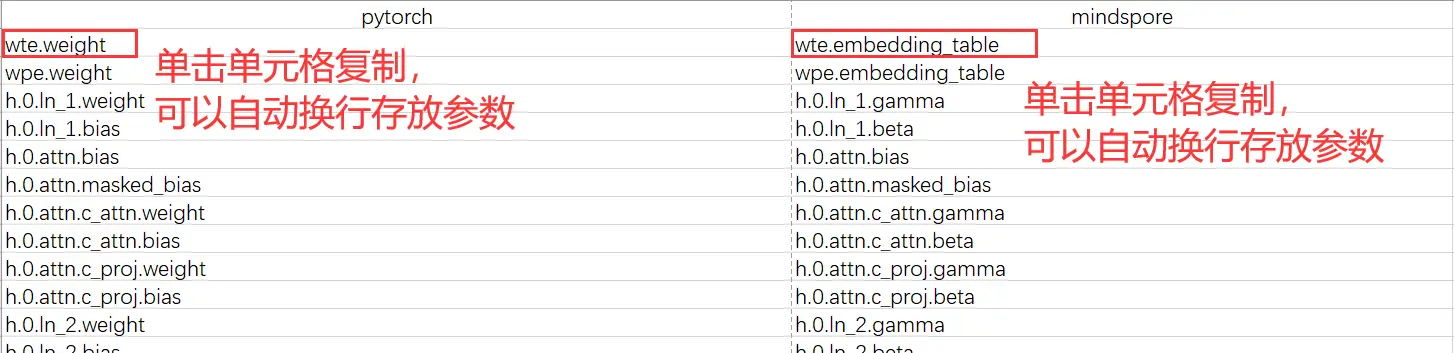

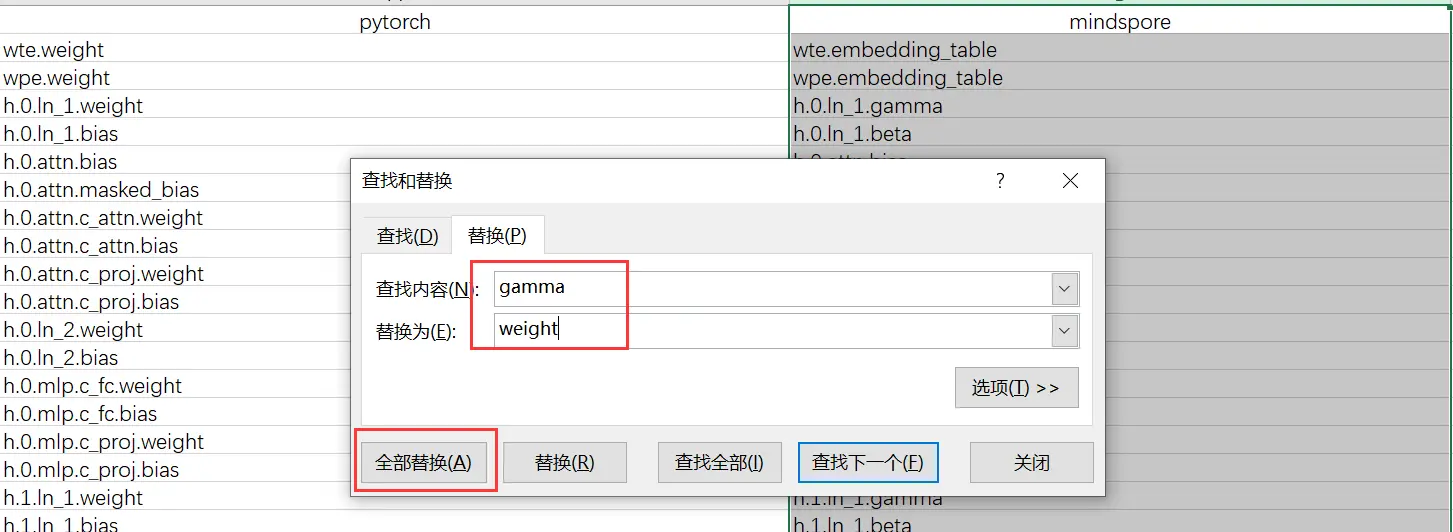
粘贴之后,由于我们知道存在一些命名的差异,因此我们点击mindspore这一列然后ctrl+f之后选择替换,将gamma换成weight,将beta换成bias,得到:

之后我们利用Excel的Exact()函数直接比较pytorch和mindspore每一行的字符串是否相同:
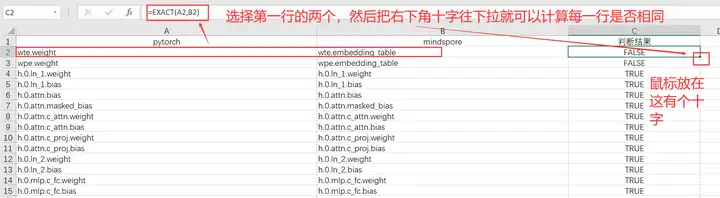
可以看到,除了前两行,后面的参数都是一致的,而前两行不一致其实也是正常的,因为只有一个embeeding层,所以我就没有将embedding_table替换为weight,实际上是对的,至此参数全部对应正确后核对结束。
(4)参数导入
参数对应一致后,我们需要将pytorch网络的参数导入mindspore的网络,同时需要注意对名称不一致参数的替换处理:
for key, parameter in ms_net.parameters_and_names(): // 获取ms模型的参数名和数值 if 'embedding_table' in key: // 参数名中的embedding_table替换为weight key = key.replace('embedding_table', 'weight') elif 'gamma' in key: key = key.replace('gamma', 'weight') // 参数名中的gamma替换为weight elif 'beta' in key: key = key.replace('beta', 'bias') // 参数名中的beta替换为bias // 依据key获取pytorch中相应参数的数值并赋给mindspore当前参数parameter,上面替换参数名就是为了get(key)的时候不会找不到 parameter.set_data(mindspore.Tensor(pt_dict.get(key).detach().numpy()))复制
参数全部正确导入之后我们就可以进入最终的checkpoint整网验证了
获取了Pytorch和MindSpore导入了参数的网络后,我们就可以和之前的3.2整网验证一样,构造输入然后验证输出是否对标,最终整体代码如下:
import torch import mindspore import numpy as np from transformers import GPT2Model, GPT2Config from mindnlp.models.gpt2 import gpt2, config_gpt2 if __name__ == "__main__": model_name = '/home/xxxxxx/wzb/mindnlp/pt_pretrained' model_config = GPT2Config.from_pretrained(model_name) pt_net = GPT2Model.from_pretrained(model_name, config=model_config) ms_config = config_gpt2.GPT2Config() ms_net = gpt2.GPT2Model(config=ms_config) pt_dict = pt_net.state_dict() ms_dict = ms_net.parameters_dict() for key, parameter in ms_net.parameters_and_names(): if 'embedding_table' in key: key = key.replace('embedding_table', 'weight') elif 'gamma' in key: key = key.replace('gamma', 'weight') elif 'beta' in key: key = key.replace('beta', 'bias') parameter.set_data(mindspore.Tensor(pt_dict.get(key).detach().numpy())) input_ids = np.random.randint(0, 10, (2, 512)) pt_input = torch.tensor(input_ids) ms_input = mindspore.Tensor(input_ids) pt_out = pt_net(pt_input) ms_out = ms_net(ms_input) assert pt_out.size() == ms_out.shape print("shape对标通过") loss = 1e-3 assert np.allclose(pt_out.detach().numpy(), ms_out.asnumpy(), loss, loss) print("精度对标通过,误差:%f", loss)复制
如果最终输出个数、shape和精度全部通过,那么恭喜你网络GPT2Model迁移成功,之后你只需要重复以上的操作,把其他的GPT2变形全部迁移成功,本次MindNLP的预训练模型迁移工作就做完成了,完结撒花!!!
通过本文的阅读,大家应该是能够了解MindNLP的预训练模型迁移工作需要做什么,怎么做以及怎么验证结果。而如果大家能够独立完成一个Model的迁移工作,就会发现目前的MindSpore2.0.0实际上已经比较好用了,API丰富并且映射表格非常详细,对于差异的描述也非常清晰,报错信息也比之前精准多了(当然还是需要努力)。看来在大家共同的努力下,MindSpore还是取得了非常显著的提升,当然距离最初设想的动静统一目标还是有不小的差距,还是需要不断的查漏补缺。
综合来说,国产深度学习框架的发展道阻且长、任重而道远,很开心自己能够为其贡献自己的一份力。同时作为昇思MindSpore的布道师我想说:从未使用过MindSpore的同学可以基于这篇文章来体验一下MindSpore,曾经使用过但是因为各种原因“退坑”了的同学也不妨试一下MindSpore2.0,真的比以前的体验好了很多!