摘要:该文为大模型评估方向的综述论文。
本文分享自华为云社区《【论文分享】《Holistic Evaluation of Language Models》》,作者:DevAI。
大模型(LLM)已经成为了大多数语言相关的技术的基石,然而大模型的能力、限制、风险还没有被大家完整地认识。该文为大模型评估方向的综述论文,由Percy Liang团队打造,将2022年四月份前的大模型进行了统一的评估。其中,被评估的模型包括GPT-3,InstructGPT等。在经过大量的实验之后,论文提出了一些可供参考的经验总结。
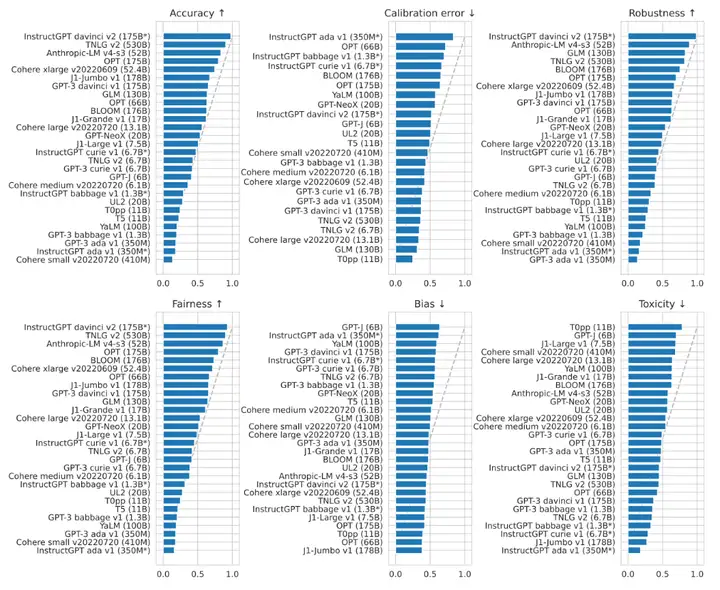
1.在所有被评估的模型中,InstructGPT davinci v2(175B) 在准确率,鲁棒性,公平性三方面上表现最好。论文主要聚焦的是国外大公司的语言大模型,而国内的知名大模型,如华为的Pangu系列以及百度的文心系列,论文并没有给出相关的测评数据。下图展示了各模型间在各种NLP任务中头对头胜率(Head-to-head win rate)的情况。可以看到,出自OpenAI的InstructGPT davinci v2在绝大多数任务中都可以击败其他模型。最近的大火的ChatGPT诞生于这篇论文之后,因此这篇论文没有对ChatGPT的测评,但ChatGPT是InstructGPT的升级版,相信ChatGPT可以取得同样优异的成绩。在下图中,准确率的综合第二名由微软的TNLG获得,第三名由初创公司Anthropic获得。同时我们也可以看到,要想在准确率额上获得55%及以上的胜率,需要至少50B的大小,可见大模型是趋势所向。
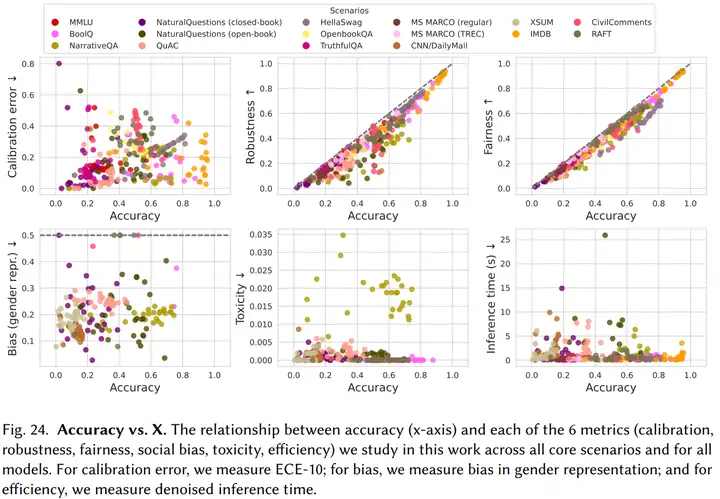
2. 由于硬件、架构、部署模式的区别,不同模型的准确率和效率之间没有强相关性。而准确率与鲁棒性(Robustness)、公平性(Fairness)之间有一定的正相关关系(如下图所示)。
如今,大模型的参数规模都非常巨大。GPT-3具有1750亿个参数,部署这样一个大模型,无论在成本上还是工程上都是极大的挑战。同时,由于需要开放API给用户使用,OpenAI还需要考虑GPT-3的推理速度。文章的测试结果显示,GPT-3的推理速度并没有显著地比参数更少地模型慢,可能是在硬件、架构和部署模式上都有一定地优势,足以弥补参数规模上的劣势。
3. InstructGPT davinci v2(175B) 在知识密集型的任务上取得了远超其他模型的成绩,在TruthfulQA数据集上获得了62.0%的准确率,远超第二名Anthropic-LM v4-s3 (52B) 36.2%的成绩。(TruthfulQA是衡量语言模型在生成问题答案时是否真实的测评数据集。该数据集包括817个问题,涵盖38个类别,包括健康,法律,金融和政治。作者精心设计了一些人会因为错误的先验知识或误解而错误回答的问题。)与此同时,TNLG v2(530B)在部分知识密集型任务上也有优异的表现。作者认为模型的规模对学习真实的知识起到很大的贡献,这一点可以从两个大模型的优异表现中推测得到。
4. 在推理(Reasoning)任务上,Codex davinci v2在代码生成和文本推理任务上表现都很优异,甚至远超一些以文本为训练语料的模型。这一点在数学推理的数据上表现最明显。在GSM8K数据集上,Codex davinci v2获得了52.1%的正确率,第二名为InstructGPT davinci v2(175B)的35.0%,且没有其他模型正确率超过16%。Codex davinci v2主要是用于解决代码相关的问题,例如代码生成、代码总结、注释生成、代码修复等,它在文本推理任务上的优秀表现可能是其在代码数据上训练的结果,因为代码是更具有逻辑关系的语言,在这样的数据集上训练也许可以提升模型的推理能力。
5. 所有的大模型都对输入(Prompt)的形式非常敏感。论文主要采用few-shot这种In-context learning的形式增强输入(Prompt)。
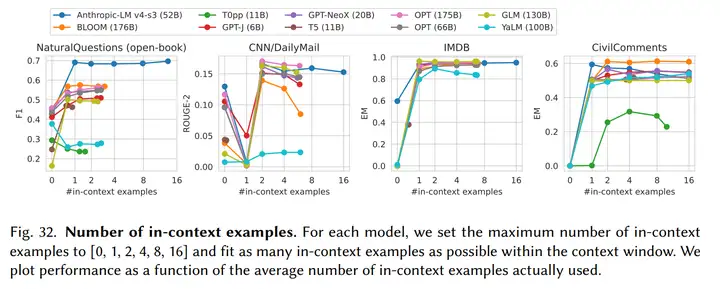
如上图所示,在不同任务上,in-context examples的数量影响不同,在不同的模型上也是如此。由于有些任务比较简单,例如二分类的IMDB数据库,增加in-context examples并不会对结果有明显的影响。在模型方面,由于window size的限制,过多的in-context examples可能导致剩余的window size不足以生成一个完成答案,因而对生成结果造成负面的影响。
文章来自:PaaS技术创新Lab,PaaS技术创新Lab隶属于华为云,致力于综合利用软件分析、数据挖掘、机器学习等技术,为软件研发人员提供下一代智能研发工具服务的核心引擎和智慧大脑。我们将聚焦软件工程领域硬核能力,不断构筑研发利器,持续交付高价值商业特性!加入我们,一起开创研发新“境界”!
PaaS技术创新Lab主页链接:https://www.huaweicloud.com/lab/paas/home.html
相关文献:
【1】Holistic Evaluation of Language Models,论文地址:https://arxiv.org/abs/2211.09110