摘要:本案例我们使用FairMOT进行车辆检测与跟踪、yolov5进行车牌检测、crnn进行车牌识别,在停车场入口、出口、停车位对车辆进行跟踪与车牌识别,无论停车场路线多复杂,小车在你掌控之中!
本文分享自华为云社区《AI寻车》,作者:杜甫盖房子。
本案例我们使用FairMOT进行车辆检测与跟踪、yolov5进行车牌检测、crnn进行车牌识别,在停车场入口、出口、停车位对车辆进行跟踪与车牌识别,无论停车场路线多复杂,小车在你掌控之中!最终效果如下:

我们使用ModelBox Windows SDK进行开发,如果还没有安装SDK,可以参考ModelBox端云协同AI开发套件(Windows)设备注册篇、ModelBox端云协同AI开发套件(Windows)SDK安装篇完成设备注册与SDK安装。
这个应用对应的ModelBox版本已经做成模板放在华为云OBS中,可以用sdk中的solution.bat工具下载,接下来我们给出该应用在ModelBox中的完整开发过程:
执行.\solution.bat -l可看到当前公开的技能模板:
PS ███> .\solution.bat -l
...
Solutions name:
mask_det_yolo3
...
vehicle_plate_multi_centernet_yolov5_crnn
结果中的vehicle_plate_multi_centernet_yolov5_crnn即为AI寻车应用模板,可使用如下命令下载模板:
PS ███> .\solution.bat -s vehicle_plate_multi_centernet_yolov5_crnn
...
solution.bat工具的参数中,-l 代表list,即列出当前已有的模板名称;-s代表solution-name,即下载对应名称的模板。下载下来的模板资源,将存放在ModelBox核心库的solution目录下。
在ModelBox sdk目录下使用create.bat创建vehicle_plate工程:
PS ███> .\create.bat -t server -n vehicle_plate -s vehicle_plate_multi_centernet_yolov5_crnn sdk version is modelbox-xxx success: create vehicle_plate in ███\modelbox\workspace
create.bat工具的参数中,-t 表示创建事务的类别,包括工程(server)、Python功能单元(Python)、推理功能单元(infer)等;-n 代表name,即创建事务的名称;-s 代表solution-name,表示将使用后面参数值代表的模板创建工程,而不是创建空的工程。
workspace目录下将创建出vehicle_plate工程,工程内容如下所示:
vehicle_plate |--bin │ |--main.bat:应用执行入口 │ |--mock_task.toml:应用在本地执行时的输入输出配置,此应用默认使用4路本地视频文件为输入源,最终结果拼接为四宫格输出到屏幕,可根据需要修改 |--CMake:存放一些自定义CMake函数 |--data:存放应用运行所需要的图片、视频、文本、配置等数据 │ |--chuchang_10.mp4:停车场出口测试视频 │ |--ruchang_10.mp4:停车场入口测试视频 │ |--ruku_10.mp4:停车位1测试视频 │ |--kong_10.mp4:停车位2测试视频 │ |--plate_keys.txt:车牌字符文件 │ |--content_file.json:技能参数全局配置文件 |--dependence │ |--modelbox_requirements.txt:应用运行依赖的外部库在此文件定义,本应用依赖pillow、scipy等工具包 |--etc │ |--flowunit:应用所需的功能单元存放在此目录 │ │ |--cpp:存放C++功能单元编译后的动态链接库,此应用没有C++功能单元 │ │ |--collapse_ocr:归拢功能单元,车牌识别后处理 │ │ |--condition:条件功能单元,判断是否检测到车辆/车牌 │ │ |--draw_full_screen:多路视频拼接输出功能单元 │ │ |--draw_plate:车牌检测结果绘制 │ │ |--draw_track_bbox:车辆跟踪结果绘制 │ │ |--expand_image:展开功能单元,展开车辆检测/车牌检测结果并行推理 │ │ |--letter_resize:车辆检测预处理功能单元 │ │ |--object_tracker:跟踪功能单元 │ │ |--plate_det_post:车牌检测后处理功能单元 │ │ |--url_cfg:流单元,多路输入解析 │ │ |--vehicle_det_post:车牌检测结果绘制 |--flowunit_cpp:存放C++功能单元的源代码,此应用没有C++功能单元 |--graph:存放流程图 │ |--vehicle_plate.toml:默认流程图,使用本地视频文件作为输入源 │ |--modelbox.conf:modelbox相关配置 |--hilens_data_dir:存放应用输出的结果文件、日志、性能统计信息 |--model:推理功能单元目录 │ |--vehicle_det:车辆检测推理功能单元 │ │ |--vehicle_det.toml:车辆检测推理功能单元的配置文件 │ │ |--vehicle_det_320x576.onnx:车辆检测onnx模型 │ |--plate_det:车牌检测推理功能单元 │ │ |--plate_det.toml:车牌检测推理功能单元的配置文件 │ │ |--plate_det.onnx:车牌检测onnx模型 │ |--plate_rec:车牌识别推理功能单元 │ │ |--plate_rec.toml:车牌识别推理功能单元的配置文件 │ │ |--plate_rec.onnx:车牌识别onnx模型 |--build_project.sh:应用构建脚本 |--CMakeLists.txt |--rpm:打包rpm时生成的目录,将存放rpm包所需数据 |--rpm_copyothers.sh:rpm打包时的辅助脚本
vehicle_plate工程graph目录下存放流程图,默认的流程图vehicle_plate.toml与工程同名,其内容为(以Windows版ModelBox为例):
# 功能单元的扫描路径,包含在[]中,多个路径使用,分隔 # ${HILENS_APP_ROOT} 表示当前应用的实际路径 # ${HILENS_MB_SDK_PATH} 表示ModelBox核心库的实际路径 [driver] dir = [ "${HILENS_APP_ROOT}/etc/flowunit", "${HILENS_APP_ROOT}/etc/flowunit/cpp", "${HILENS_APP_ROOT}/model", "${HILENS_MB_SDK_PATH}/flowunit", ] skip-default = true [profile] # 通过配置profile和trace开关启用应用的性能统计 profile = false # 是否记录profile信息,每隔60s记录一次统计信息 trace = false # 是否记录trace信息,在任务执行过程中和结束时,输出统计信息 dir = "${HILENS_DATA_DIR}/mb_profile" # profile/trace信息的保存位置 [graph] format = "graphviz" # 流程图的格式,当前仅支持graphviz graphconf = """digraph vehicle_plate{ node [shape=Mrecord] queue_size = 1 batch_size = 1 input1[type=input,flowunit=input,device=cpu,deviceid=0] data_source_parser[type=flowunit, flowunit=data_source_parser, device=cpu, deviceid=0] url_cfg[type=flowunit, flowunit=url_cfg, device=cpu, deviceid=0] video_demuxer[type=flowunit, flowunit=video_demuxer, device=cpu, deviceid=0] video_decoder[type=flowunit, flowunit=video_decoder, device=cpu, deviceid=0, pix_fmt="rgb"] letter_resize[type=flowunit, flowunit=letter_resize, device=cpu] color_transpose[type=flowunit, flowunit=packed_planar_transpose, device=cpu, deviceid=0] normalize[type=flowunit, flowunit=normalize, device=cpu, deviceid=0, standard_deviation_inverse="0.003921568627451, 0.003921568627451, 0.003921568627451"] vehicle_det[type=flowunit, flowunit=vehicle_det, device=cpu, deviceid=0, batch_size=1] vehicle_det_post[type=flowunit, flowunit=vehicle_det_post, device=cpu, deviceid=0] object_tracker[type=flowunit, flowunit=object_tracker, device=cpu, deviceid=0] vehicle_condition[type=flowunit, flowunit=condition, device=cpu, deviceid=0] expand_car[type=flowunit, flowunit=expand_image, device=cpu, deviceid=0, img_h=640, img_w=640] plate_color_transpose[type=flowunit flowunit=packed_planar_transpose device=cpu deviceid="0"] plate_normalize[type=flowunit flowunit=normalize device=cpu deviceid=0 standard_deviation_inverse="0.003921568627451,0.003921568627451,0.003921568627451"] plate_det[type=flowunit flowunit=plate_det device=cpu deviceid="0", batch_size=1] plate_det_post[type=flowunit, flowunit=plate_det_post, device=cpu, deviceid=0] plate_condition[type=flowunit, flowunit=condition, device=cpu, deviceid=0, key="plate"] expand_plate[type=flowunit, flowunit=expand_image, device=cpu, deviceid=0, img_h=48, img_w=168, key="plate"] ocr_color_transpose[type=flowunit flowunit=packed_planar_transpose device=cpu deviceid="0"] ocr_mean[type=flowunit flowunit=mean device=cpu deviceid="0" mean="149.94,149.94,149.94"] ocr_normalize[type=flowunit flowunit=normalize device=cpu deviceid=0 standard_deviation_inverse="0.020319,0.020319,0.020319"] plate_rec[type=flowunit flowunit=plate_rec device=cpu deviceid="0", batch_size=1] collapse_ocr[type=flowunit flowunit=collapse_ocr device=cpu deviceid="0"] draw_plate[type=flowunit, flowunit=draw_plate, device=cpu, deviceid=0] draw_track_bbox[type=flowunit, flowunit=draw_track_bbox, device=cpu, deviceid=0] draw_full_screen[type=flowunit, flowunit=draw_full_screen, device=cpu, deviceid=0] video_out[type=flowunit, flowunit=video_out, device=cpu, deviceid=0, full_screen=true] input1:input -> data_source_parser:in_data data_source_parser:out_video_url -> url_cfg:in_1 url_cfg:out_1 -> video_demuxer:in_video_url video_demuxer:out_video_packet -> video_decoder:in_video_packet video_decoder:out_video_frame -> letter_resize:in_image letter_resize:resized_image -> color_transpose:in_image color_transpose:out_image -> normalize:in_data normalize:out_data -> vehicle_det:input vehicle_det:output -> vehicle_det_post:in_feat letter_resize:out_image -> vehicle_det_post:in_image vehicle_det_post:out_feat -> object_tracker:in_feat object_tracker:out_track -> vehicle_condition:in_track video_decoder:out_video_frame -> vehicle_condition:in_image vehicle_condition:out_track -> expand_car:in_image expand_car:out_image -> plate_color_transpose:in_image plate_color_transpose:out_image -> plate_normalize:in_data plate_normalize:out_data -> plate_det:input plate_det:output -> plate_det_post:in_feat expand_car:out_image -> plate_det_post:in_image plate_det_post:out_tracks -> plate_condition: in_track vehicle_condition:out_track -> plate_condition: in_image plate_condition:out_track -> expand_plate:in_image expand_plate:out_image -> ocr_color_transpose:in_image ocr_color_transpose:out_image -> ocr_mean:in_data ocr_mean:out_data -> ocr_normalize:in_data ocr_normalize:out_data -> plate_rec:input plate_rec:output -> collapse_ocr:in_feat expand_plate:out_image -> collapse_ocr:in_image collapse_ocr:out_tracks -> draw_plate:in_feat plate_condition:out_track -> draw_plate:in_image draw_plate:out_image -> draw_track_bbox:in_image plate_condition:out_image -> draw_track_bbox:in_image draw_track_bbox:out_image -> draw_full_screen:in_image vehicle_condition:out_image -> draw_full_screen:in_image draw_full_screen:out_image -> video_out:in_video_frame }""" [flow] desc = "vehicle_plate run in modelbox-win10-x64"
将流程图可视化:
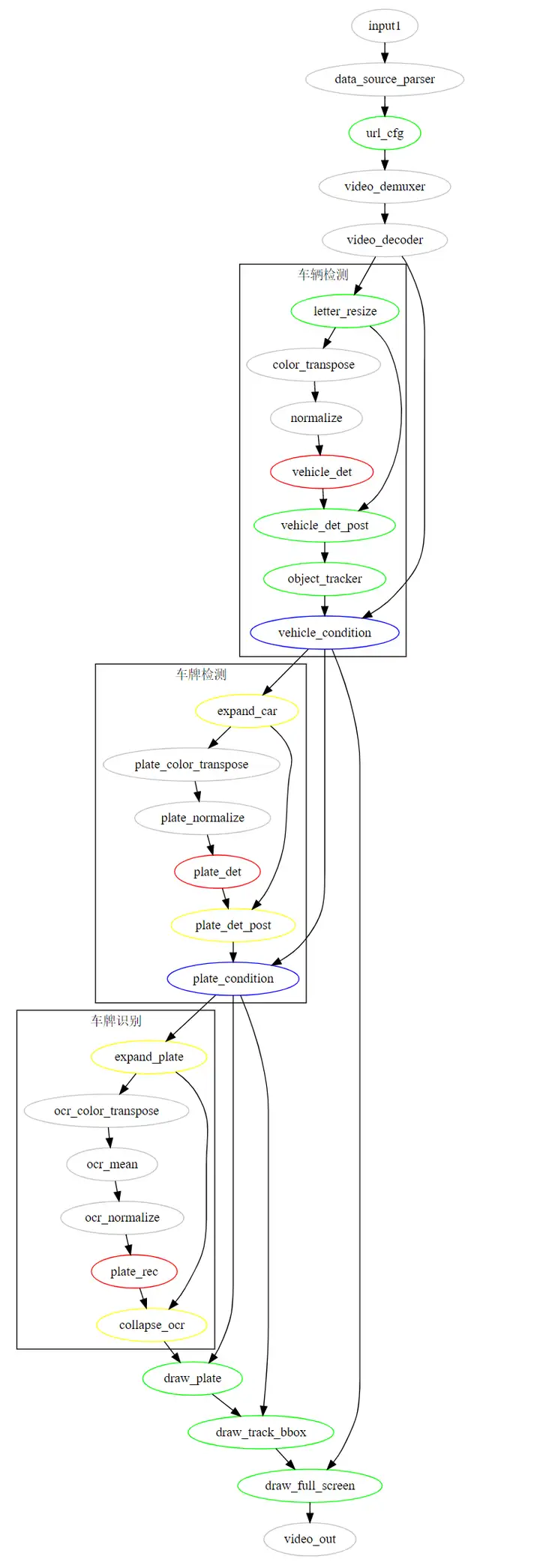
图示中,灰色部分为预置功能单元,其余颜色为我们实现的功能单元,其中绿色为一般通用功能单元,红色为推理功能单元,蓝色为条件功能单元,黄色为展开归拢功能单元。整个应用逻辑相对复杂一些,视频解码后做图像预处理,接着是车辆检测,模型后处理得到车形框与128维车辆reid特征,送入跟踪算法进行实时跟踪,经过条件功能单元判断,检测到车辆的图送入展开功能单元,切图进行车牌检测,车牌检测结果归拢后同样要判断是否检测到车牌,检测到车牌的帧再展开并行进行车牌识别,未检测到的则直接绘制车辆信息。而未检测到车辆的帧则直接送入多路拼接功能单元,最终输出。
本应用核心逻辑中的跟踪与区域判断参照客流统计实战营的应用设计,跟踪逻辑在object_tracker功能单元中,检测与跟踪使用的是FairMOT算法,算法介绍可参考论文。
首先查看object_tracker功能单元中返回的跟踪对象结构:
def get_tracking_objects(self, online_targets_dict): tracking_objects = {} for cls_id in range(self.num_classes): online_targets = online_targets_dict[cls_id] for t in online_targets: obj = {} tlwh = t.tlwh if tlwh[2] * tlwh[3] < self.min_box_area: continue tid = t.track_id obj["bbox"] = [max(0, tlwh[0]), max(0, tlwh[1]), tlwh[0] + tlwh[2], tlwh[1] + tlwh[3]] obj["licence"] = "" obj["licence_score"] = 0.0 obj["plate"] = np.zeros((4, 2)).tolist() obj["plate_score"] = 0.0 obj["bbox_score"] = t.score tracking_objects[tid] = obj return tracking_objects
可以看到,我们返回的跟踪对象包括车型框、车辆检测得分等已有信息以及车牌、车牌得分、车牌框、车牌框得分等包含默认数据的占位信息,方便后续功能单元获取更新。
从流程图中可以看到,object_tracker后结果送入车辆检测条件功能单元,同样的在流程图中还包含车牌检测条件功能单元,我们当然是希望使用同一个功能单元完成两个判断,所以在条件功能单元condition中,我们配置了参数key,默认为key = "bbox",即对结构体中的车型框进行判断,具体实现为:
if track_result and np.any([v.get(self.key) for k, v in track_result.items()]): buffer_img.set("track", track_json) out_track.push_back(buffer_img) else: buffer_img.set("track", track_json) out_image.push_back(buffer_img)
这样的话如果是对车型框进行判断,只需要在流程图中配置key = “plate”即可。
同样的,图展开功能单元expand_image也使用了同样的方法,使车辆检测与车牌检测可以共用功能单元:
tracking_objects = json.loads(buffer_img.get("track")) for idx, target in tracking_objects.items(): box = np.array(target.get(self.key)) ...
此外,由于本应用输入为4路视频,因此需要在url_cfg单元中进行session级别信息配置:
url_str = str(self.count) + input_meta.get_private_string("source_url") self.count += 1 data_context.get_session_context().set_private_string("multi_source_url", url_str)
session级别的信息在功能单元之间是同步的,这样就可以在后续的功能单元中获取当前输入为哪路输入:
url = data_context.get_session_context().get_private_string("multi_source_url") image_index = int(url[0])
同样的,对于多路输入,我们需要在本地mock时在bin/mock_task.toml文件中进行输入配置:
[input] type = "url" url = "${HILENS_APP_ROOT}/data/ruchang_10.mp4" [input1] type = "url" url = "${HILENS_APP_ROOT}/data/chuchang_10.mp4" [input2] type = "url" url = "${HILENS_APP_ROOT}/data/ruku_10.mp4" [input3] type = "url" url = "${HILENS_APP_ROOT}/data/kong_10.mp4"
对于多路输入的感兴趣区域划定,我们使用content_file配置:
[common] content_file = "../data/content_file.json"
配置文件内容为:
[ { "vehicle_area": "190,245,382,656,1265,630,956,249", "plate_area": "190,245,382,656,1265,630,956,249" }, { "vehicle_area": "663,467,228,675,994,682,1167,459", "plate_area": "663,467,228,675,994,682,1167,459" }, { "vehicle_area": "0,0,1280,0,1280,720,0,720", "plate_area": "0,0,1280,0,1280,720,0,720" }, { "vehicle_area": "0,0,1280,0,1280,720,0,720", "plate_area": "0,0,1280,0,1280,720,0,720" } ]
即针对不同输入配置各自的车型车牌感兴趣区域,在后续功能单元中获取配置的参数信息进行处理,如plate_det_post功能单元:
self.areas = json.loads(data_context.get_session_config().get_string("iva_task_common")) url = data_context.get_session_context().get_private_string("multi_source_url") image_index = int(url[0]) self.area = self.areas[image_index].get("plate_area") if self.area: self.area = np.array(list(map(int, self.area.split(",")))).reshape(-1, 1, 2).astype(np.int32)
我们目前对于车型和车牌检测的参数配置是保持一致的,也可以配置为不同参数。
本应用依赖scipy等工具包,ModelBox应用不需要手动安装三方依赖库,只需要配置在dependence\modelbox_requirements.txt,应用在编译时会自动安装。
在项目目录下执行.\bin\main.bat运行应用:
PS ███> .\bin\main.bat
...
可以看到屏幕出现技能画面:

白线即配置的感兴趣区域,区域外/未过线车辆根据id赋色,区域内/已过线车辆的使用灰色框,可在输入输出配置中修改划区域任务类型与坐标点。
我们1.5.0版本SDK提供了debug工具,在VSCode中打开项目根目录,在创建项目时已经自动生成了调试配置文件:
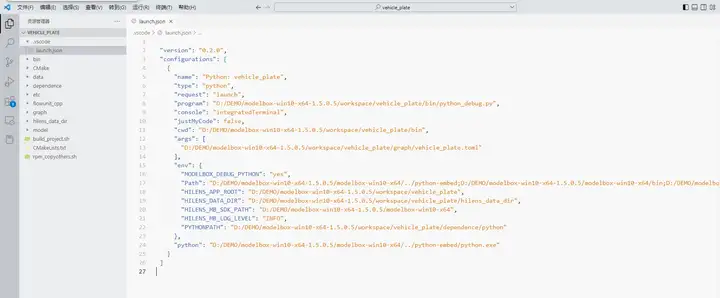
如果有其他安装包,可以在配置文件中增加PYTHONPATH参数。
在调试时,可以直接在感兴趣的代码处打断点调试即可:
启动调试后与其他程序调试操作一致: