摘要:本文为大家详解数据结构中栈的定义和操作。
本文分享自华为云社区《数据结构:详细讲解栈的定义、栈的操作》,作者: 高彬滔 。
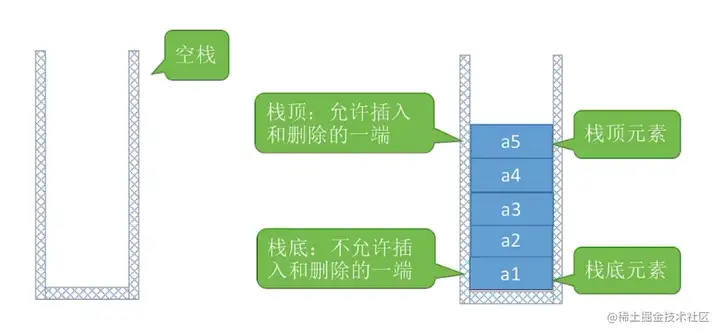
栈(stack):是只允许在一端进行插入或者删除操作的线性表(即后进先出,大概可以理解为吃饱了吐出来)
其他常见操作: StackEmpty(S):判断一个栈S是否为空,若S为空,则返回true,否则返回false

#define MaxSize 10 //定义栈中元素的最大个数 typedef struct{ ElemType data[MaxSize]; //静态数组存放栈中的元素 int top; //栈顶指针 }SqStack; //结构体重命名复制
声明一个顺序栈后就会在内存中分配一整片连续的空间,其中内存大小为:MaxSize*sizeof(ELemType)
void testStack(){ SqStack S; //声明一个顺序栈 }复制
由于栈顶指针top需要指向此时栈顶元素,所以让top指向0是不合理的,可以初始化让top指向-1;判断一个栈是否为空,即判断S.top是否等于-1
初始化栈:
void Inittack(SqStack){ SqStack S; //声明一个顺序栈 S.top=-1; }复制
判断栈空:
bool StackEmpty(SqStack S){ if(S.top==-1) //栈空 return true; else return false; //非空 }复制
分析:
bool Push(SqStack &S,ElemType x){ if(S.top==NaxSize-1) return false; S.top+=1; S.data[S.top]=x; return true; }复制
bool Push(SqStack &S,ElemType &x){ if(S.top==-1) return false; x=S.data[S.top--]; return true; }复制
bool GetTop(SqStack &S,ElemType &x){ if(S.top==-1) return false; x=S.data[S.top]; return true; }复制
两个栈共享同一片空间
#define MaxSize 10 //定义栈中元素的最大个数 typedef struct{ ElemType data[MaxSize]; //静态数组存放栈中的元素 int top0; //0号栈栈顶指针 int top1; //1号栈栈顶指针 }SqStack; //结构体重命名 初始化栈: void InitStack(ShStack &S){ S.top0=-1; S.top1=MaxSize; }复制
typedef struct Linknode{ ElemType data; //数据域 struct Linknode *next; //指针域 }*LiStack //栈类型定义复制