摘要:从图像提取人体姿态,用姿态信息控制生成具有相同姿态的新图像。
本文分享自华为云社区《Pose泰裤辣! 一键提取姿态生成新图像》,作者: Emma_Liu 。
相关链接:Notebook案例地址: 人体姿态生成图像 ControlNet-Human Pose in Stable Diffusion
AI gallery:https://developer.huaweicloud.com/develop/aigallery/home.html
也可通过AI Gallery,搜索【人体姿态生成图像】一键体验!
什么是ControlNet?ControlNet最早是在L.Zhang等人的论文《Adding Conditional Control to Text-to-Image Diffusion Model》中提出的,目的是提高预训练的扩散模型的性能。它引入了一个框架,支持在扩散模型 (如 Stable Diffusion) 上附加额外的多种空间语义条件来控制生成过程。
ControlNet可以复制构图和人体姿势。它解决了生成想要的确切姿势困难的问题。
Human Pose使用OpenPose检测关键点,如头部、肩膀、手的位置等。它适用于复制人类姿势,但不适用于其他细节,如服装、发型和背景。
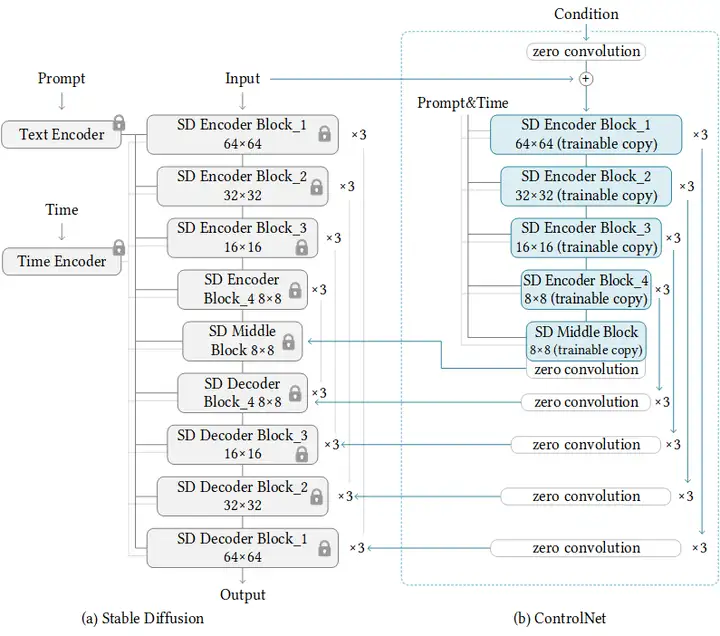
ControlNet 的工作原理是将可训练的网络模块附加到稳定扩散模型的U-Net (噪声预测器)的各个部分。Stable Diffusion 模型的权重是锁定的,在训练过程中它们是不变的。在训练期间仅修改附加模块。
研究论文中的模型图很好地总结了这一点。最初,附加网络模块的权重全部为零,使新模型能够利用经过训练和锁定的模型。
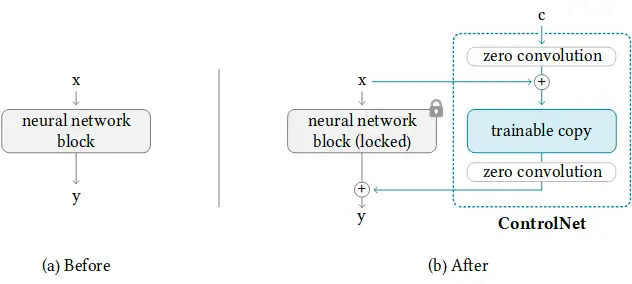
训练 ControlNet 包括以下步骤:
从图上看,训练ControlNet是这样的:
ControlNet提供了八个扩展,每个扩展都可以对扩散模型进行不同的控制。这些扩展是Canny, Depth, HED, M-LSD, Normal, Openpose, Scribble, and Semantic Segmentation。
使用方法:
输入一个图像,并提示模型生成一个图像。Openpose将为你检测姿势,从图像提取人体姿态,用姿态信息控制生成具有相同姿态的新图像。
对两张图像分别为进行人体骨骼姿态提取,然后根据输入描述词生成图像,如下图所示:

本案例需使用Pytorch-1.8 GPU-P100及以上规格运行
点击Run in ModelArts,将会进入到ModelArts CodeLab中,这时需要你登录华为云账号,如果没有账号,则需要注册一个,且要进行实名认证,参考《ModelArts准备工作_简易版》 即可完成账号注册和实名认证。 登录之后,等待片刻,即可进入到CodeLab的运行环境
为了方便用户下载使用及快速体验,本案例已将代码及control_sd15_openpose预训练模型转存至华为云OBS中。注意:为了使用该模型与权重,你必须接受该模型所要求的License,请访问huggingface的lllyasviel/ControlNet, 仔细阅读里面的License。模型下载与加载需要几分钟时间。
import os import moxing as mox parent = os.path.join(os.getcwd(),'ControlNet') if not os.path.exists(parent): mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/ControlNet/ControlNet',parent) if os.path.exists(parent): print('Code Copy Completed.') else: raise Exception('Failed to Copy the Code.') else: print("Code already exists!") pose_model_path = os.path.join(os.getcwd(),"ControlNet/models/control_sd15_openpose.pth") body_model_path = os.path.join(os.getcwd(),"ControlNet/annotator/ckpts/body_pose_model.pth") hand_model_path = os.path.join(os.getcwd(),"ControlNet/annotator/ckpts/hand_pose_model.pth") if not os.path.exists(pose_model_path): mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/ControlNet/ControlNet_models/control_sd15_openpose.pth',pose_model_path) mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/ControlNet/ControlNet_models/body_pose_model.pth',body_model_path) mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/ControlNet/ControlNet_models/hand_pose_model.pth',hand_model_path) if os.path.exists(pose_model_path): print('Models Download Completed') else: raise Exception('Failed to Copy the Models.') else: print("Model Packages already exists!")复制
check GPU & 安装依赖
大约耗时1min
!nvidia-smi %cd ControlNet !pip uninstall torch torchtext -y !pip install torch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 !pip install omegaconf==2.1.1 einops==0.3.0 !pip install pytorch-lightning==1.5.0 !pip install transformers==4.19.2 open_clip_torch==2.0.2 !pip install gradio==3.24.1 !pip install translate==3.6.1 !pip install scikit-image==0.19.3 !pip install basicsr==1.4.2复制
导包
import config import cv2 import einops import gradio as gr import numpy as np import torch import random from pytorch_lightning import seed_everything from annotator.util import resize_image, HWC3 from annotator.openpose import OpenposeDetector from cldm.model import create_model, load_state_dict from cldm.ddim_hacked import DDIMSampler from translate import Translator from PIL import Image import matplotlib.pyplot as plt复制
apply_openpose = OpenposeDetector() model = create_model('./models/cldm_v15.yaml').cpu() model.load_state_dict(load_state_dict('./models/control_sd15_openpose.pth', location='cuda')) model = model.cuda() ddim_sampler = DDIMSampler(model)复制
def infer(input_image, prompt, a_prompt, n_prompt, num_samples, image_resolution, detect_resolution, ddim_steps, guess_mode, strength, scale, seed, eta): trans = Translator(from_lang="ZH",to_lang="EN-US") prompt = trans.translate(prompt) a_prompt = trans.translate(a_prompt) n_prompt = trans.translate(n_prompt) # 图像预处理 with torch.no_grad(): if type(input_image) is str: input_image = np.array(Image.open(input_image)) input_image = HWC3(input_image) detected_map, _ = apply_openpose(resize_image(input_image, detect_resolution)) detected_map = HWC3(detected_map) img = resize_image(input_image, image_resolution) H, W, C = img.shape # 初始化检测映射 detected_map = cv2.resize(detected_map, (W, H), interpolation=cv2.INTER_NEAREST) control = torch.from_numpy(detected_map.copy()).float().cuda() / 255.0 control = torch.stack([control for _ in range(num_samples)], dim=0) control = einops.rearrange(control, 'b h w c -> b c h w').clone() # 设置随机种子 if seed == -1: seed = random.randint(0, 65535) seed_everything(seed) if config.save_memory: model.low_vram_shift(is_diffusing=False) cond = {"c_concat": [control], "c_crossattn": [model.get_learned_conditioning([prompt + ', ' + a_prompt] * num_samples)]} un_cond = {"c_concat": None if guess_mode else [control], "c_crossattn": [model.get_learned_conditioning([n_prompt] * num_samples)]} shape = (4, H // 8, W // 8) if config.save_memory: model.low_vram_shift(is_diffusing=True) # 采样 model.control_scales = [strength * (0.825 ** float(12 - i)) for i in range(13)] if guess_mode else ([strength] * 13) # Magic number. IDK why. Perhaps because 0.825**12<0.01 but 0.826**12>0.01 samples, intermediates = ddim_sampler.sample(ddim_steps, num_samples, shape, cond, verbose=False, eta=eta, unconditional_guidance_scale=scale, unconditional_conditioning=un_cond) if config.save_memory: model.low_vram_shift(is_diffusing=False) # 后处理 x_samples = model.decode_first_stage(samples) x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cpu().numpy().clip(0, 255).astype(np.uint8) results = [x_samples[i] for i in range(num_samples)] return [detected_map] + results复制
设置参数,生成图像
上传您的图像至./ControlNet/test_imgs/ 路径下,然后更改图像路径及其他参数后,点击运行。
img_path:输入图像路径,黑白稿
prompt:提示词
a_prompt:次要的提示
n_prompt: 负面提示,不想要的内容
image_resolution: 对输入的图片进行最长边等比resize
detect_resolution: 中间生成条件图像的分辨率
scale:文本提示的控制强度,越大越强
guess_mode: 盲猜模式,默认关闭,开启后生成图像将不受prompt影响,使用更多样性的结果,生成后得到不那么遵守图像条件的结果
seed: 随机种子
ddim_steps: 采样步数,一般15-30,值越大越精细,耗时越长
DDIM eta: 生成过程中的随机噪声系数,一般选0或1,1表示有噪声更多样,0表示无噪声,更遵守描述条件
strength: 这是应用 ControlNet 的步骤数。它类似于图像到图像中的去噪强度。如果指导强度为 1,则 ControlNet 应用于 100% 的采样步骤。如果引导强度为 0.7 并且您正在执行 50 个步骤,则 ControlNet 将应用于前 70% 的采样步骤,即前 35 个步骤。
#@title ControlNet-OpenPose img_path = "test_imgs/pose1.png" #@param {type:"string"} prompt = "优雅的女士" #@param {type:"string"} seed = 1685862398 #@param {type:"slider", min:-1, max:2147483647, step:1} guess_mode = False #@param {type:"raw", dropdown} a_prompt = '质量最好,非常详细' n_prompt = '长体,下肢,解剖不好,手不好,手指缺失,手指多,手指少,裁剪,质量最差,质量低' num_samples = 1 image_resolution = 512 detect_resolution = 512 ddim_steps = 20 strength = 1.0 scale = 9.0 eta = 0.0 np_imgs = infer(img_path, prompt, a_prompt, n_prompt, num_samples, image_resolution, detect_resolution, ddim_steps, guess_mode, strength, scale, seed, eta) ori = Image.open(img_path) src = Image.fromarray(np_imgs[0]) dst = Image.fromarray(np_imgs[1]) fig = plt.figure(figsize=(25, 10)) ax1 = fig.add_subplot(1, 3, 1) plt.title('Orginal image', fontsize=16) ax1.axis('off') ax1.imshow(ori) ax2 = fig.add_subplot(1, 3, 2) plt.title('Pose image', fontsize=16) ax2.axis('off') ax2.imshow(src) ax3 = fig.add_subplot(1, 3, 3) plt.title('Generate image', fontsize=16) ax3.axis('off') ax3.imshow(dst) plt.show()复制

Gradio应用启动后可在下方页面上传图片根据提示生成图像,您也可以分享public url在手机端,PC端进行访问生成图像。
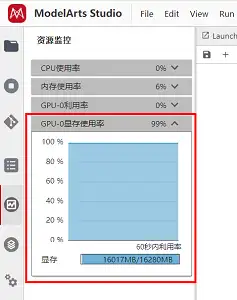
请注意: 在图像生成需要消耗显存,您可以在左侧操作栏查看您的实时资源使用情况,点击GPU显存使用率即可查看,当显存不足时,您生成图像可能会报错,此时,您可以通过重启kernel的方式重置,然后重头运行即可规避。
block = gr.Blocks().queue() with block: with gr.Row(): gr.Markdown("## 人体姿态生成图像") with gr.Row(): with gr.Column(): gr.Markdown("请上传一张人像图,设置好参数后,点击Run") input_image = gr.Image(source='upload', type="numpy") prompt = gr.Textbox(label="描述") run_button = gr.Button(label="Run") with gr.Accordion("高级选项", open=False): num_samples = gr.Slider(label="Images", minimum=1, maximum=3, value=1, step=1) image_resolution = gr.Slider(label="Image Resolution", minimum=256, maximum=768, value=512, step=64) strength = gr.Slider(label="Control Strength", minimum=0.0, maximum=2.0, value=1.0, step=0.01) guess_mode = gr.Checkbox(label='Guess Mode', value=False) detect_resolution = gr.Slider(label="OpenPose Resolution", minimum=128, maximum=1024, value=512, step=1) ddim_steps = gr.Slider(label="Steps", minimum=1, maximum=30, value=20, step=1) scale = gr.Slider(label="Guidance Scale", minimum=0.1, maximum=30.0, value=9.0, step=0.1) seed = gr.Slider(label="Seed", minimum=-1, maximum=2147483647, step=1, randomize=True) eta = gr.Number(label="eta (DDIM)", value=0.0) a_prompt = gr.Textbox(label="Added Prompt", value='best quality, extremely detailed') n_prompt = gr.Textbox(label="Negative Prompt", value='longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality') with gr.Column(): result_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery").style(grid=2, height='auto') ips = [input_image, prompt, a_prompt, n_prompt, num_samples, image_resolution, detect_resolution, ddim_steps, guess_mode, strength, scale, seed, eta] run_button.click(fn=infer, inputs=ips, outputs=[result_gallery]) block.launch(share=True)复制