摘要:输入一个图像,通过Segment Anything模型即可获得图像所有目标的分割点位置,再通过位置将图像进行分割保存。
本文分享自华为云社区《一键分割图像》,作者:雨落无痕 。
Segment Anything Model(SAM)通过点或框等输入提示生成高质量的对象分割区域,并且可以用于为图像中的所有对象生成分割区域。它已经在1100万张图像和11亿个分割区域的数据集上进行了训练,并且在各种分割任务上具有强大的零样本性能。


在自然语言处理和最近的计算机视觉领域,最令人兴奋的发展之一是基础模型的发展,这些基础模型可以使用提示技术(prompting)对新数据集和任务执行零样本和小样本学习。我们从这类工作中汲取了灵感。
我们训练 SAM 为任何提示返回有效的分割掩码,其中提示可以是前景/背景点、粗框或掩码、自由格式文本。或者一般来说,提示图像中要分割的内容的任何信息。有效掩码的要求仅仅意味着即使提示不明确并且可能指代多个对象(例如,衬衫上的一个点可能表示衬衫或穿着它的人),输出也应该是一个合理的掩码对象之一。此任务用于预训练模型并通过提示解决一般的下游分割任务。
我们观察到预训练任务和交互式数据收集对模型设计施加了特定的限制。特别是,该模型需要在Web浏览器的CPU上实时运行,以允许我们的标注者实时交互地使用 SAM 以高效地进行标注。虽然运行时限制意味着质量和运行时之间的权衡,但我们发现简单的设计在实践中会产生良好的结果。具体地,图像编码器为图像生成一次性嵌入向量,而轻量级编码器将任何提示实时转换为嵌入向量。然后将这两个信息源组合在一个预测分割掩码的轻量级解码器中。在计算图像嵌入后,SAM 可以在 50 毫秒内根据网络浏览器中的任何提示生成一个分割。
SAM模型总体上分为3部分:
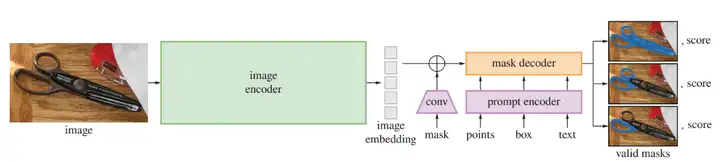
绿色的图像编码器,基于可扩展和强大的预训练方法,我们使用MAE预训练的ViT,最小限度地适用于处理高分辨率输入。图像编码器对每张图像运行一次,在提示模型之前进行应用。
紫色的提示编码器,考虑两组prompt:稀疏(点、框、文本)和密集(掩码)。我们通过位置编码来表示点和框,并将对每个提示类型的学习嵌入和自由形式的文本与CLIP中的现成文本编码相加。密集的提示(即掩码)使用卷积进行嵌入,并通过图像嵌入进行元素求和。
橙色的提示编码器,掩码解码器有效地将图像嵌入、提示嵌入和输出token映射到掩码。该设计的灵感来自于DETR,采用了对(带有动态掩模预测头的)Transformer decoder模块的修改。
使用方法:
输入一个图像,通过Segment Anything模型即可获得图像所有目标的分割点位置,再通过位置将图像进行分割保存。
本案例需使用 Pytorch-1.8 GPU-P100 及以上规格运行
点击Run in ModelArts,将会进入到ModelArts CodeLab中,这时需要你登录华为云账号,如果没有账号,则需要注册一个,且要进行实名认证,参考《ModelArts准备工作_简易版》 即可完成账号注册和实名认证。登录之后,等待片刻,即可进入到CodeLab的运行环境
出现 Out Of Memory ,请检查是否为您的参数配置过高导致,修改参数配置,重启kernel或更换更高规格资源进行规避❗❗❗
为了方便用户下载使用及快速体验,本案例已将代码及segment-anything预训练模型转存至华为云OBS中。模型下载与加载需要几分钟时间。
import os import torch import os.path as osp import moxing as mox path = osp.join(os.getcwd(),'segment-anything') if not os.path.exists(path): mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/segment-anything', path) if os.path.exists(path): print('Download success') else: raise Exception('Download Failed') else: print("Model Package already exists!")复制
check GPU & 安装依赖
大约耗时1min
%cd segment-anything !pip install --upgrade pip !pip install torch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 !pip install opencv-python matplotlib !python setup.py install import numpy as np import matplotlib.pyplot as plt import cv2 import copy import torch import torchvision print("PyTorch version:", torch.__version__) print("Torchvision version:", torchvision.__version__) print("CUDA is available:", torch.cuda.is_available())复制
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor sam_checkpoint = "sam_vit_h_4b8939.pth" model_type = "vit_h" device = "cuda" sam = sam_model_registry[model_type](checkpoint=sam_checkpoint) sam.to(device=device) mask_generator = SamAutomaticMaskGenerator( model=sam, #points_per_side=32, #pred_iou_thresh=0.86, #stability_score_thresh=0.92, #crop_n_layers=1, #crop_n_points_downscale_factor=2, #min_mask_region_area=100, # Requires open-cv to run post-processing )复制
def show_anns(anns,image): segment_image = copy.copy(image) segment_image.astype("uint8") if len(anns) == 0: return sorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True) for ann in sorted_anns: mask_2d = ann['segmentation'] h,w = mask_2d.shape mask_3d_color = np.zeros((h,w,3), dtype=np.uint8) mask = (mask_2d!=0).astype(bool) rgb = np.random.randint(0, 255, (1, 3), dtype=np.uint8) mask_3d_color[mask_2d[:, :] == 1] = rgb segment_image[mask] = segment_image[mask] * 0.5 + mask_3d_color[mask] * 0.5 return segment_image image = cv2.imread('images/dog.jpg') image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) masks = mask_generator.generate(image) segment_image = show_anns(masks,image) fig = plt.figure(figsize=(25, 10)) ax1 = fig.add_subplot(1, 2, 1) plt.title('Original image', fontsize=16) ax1.axis('off') ax1.imshow(image) ax2 = fig.add_subplot(1, 2, 2) plt.title('Segment image', fontsize=16) ax2.axis('off') ax2.imshow(segment_image) plt.show()复制

将所有识别出来的分割位置进行分割,并保存成图片。
def apply_mask(image, mask, alpha_channel=True):#应用并且响应mask if alpha_channel: alpha = np.zeros_like(image[..., 0])#制作掩体 alpha[mask == 1] = 255#兴趣地方标记为1,且为白色 image = cv2.merge((image[..., 0], image[..., 1], image[..., 2], alpha))#融合图像 else: image = np.where(mask[..., None] == 1, image, 0) return image def mask_image(image, mask, crop_mode_=True):#保存掩盖部分的图像(感兴趣的图像) if crop_mode_: y, x = np.where(mask) y_min, y_max, x_min, x_max = y.min(), y.max(), x.min(), x.max() cropped_mask = mask[y_min:y_max+1, x_min:x_max+1] cropped_image = image[y_min:y_max+1, x_min:x_max+1] masked_image = apply_mask(cropped_image, cropped_mask) else: masked_image = apply_mask(image, mask) return masked_image def save_masked_image(image, filepath): if image.shape[-1] == 4: cv2.imwrite(filepath, image, [cv2.IMWRITE_PNG_COMPRESSION, 9]) else: cv2.imwrite(filepath, image) print(f"Saved as {filepath}") def save_anns(anns,image,path): if len(anns) == 0: return sorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True) index = 1 for ann in sorted_anns: mask_2d = ann['segmentation'] segment_image = copy.copy(image) masked_image = mask_image(segment_image, mask_2d) filename = str(index) + '.png' filepath = os.path.join(path, filename) save_masked_image(masked_image, filepath) index = index + 1 save_path = 'result/' if not os.path.exists(save_path): os.mkdir(save_path) image = cv2.imread('images/dog.jpg') masks = mask_generator.generate(image) save_anns(masks,image,save_path)复制
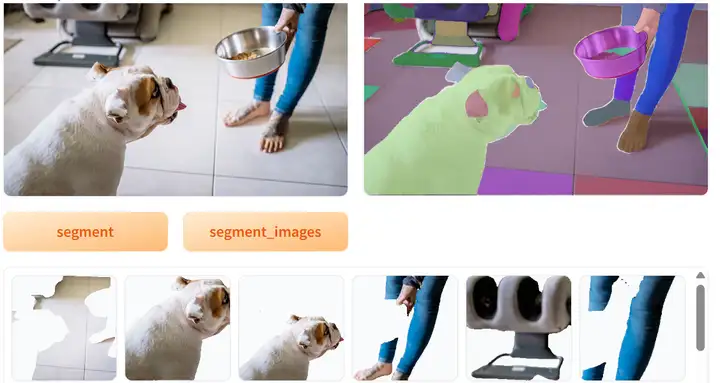
为了方便大家使用一键分割案例,当前增加了Gradio可视化部署案例演示。
运行如下代码,Gradio应用启动后可在下方页面进行一键分割图像,您也可以分享public url在手机端,PC端进行访问生成图像。
示例效果如下:
!pip install gradio==3.24.1 def segment_image(image): masks = mask_generator.generate(image) return show_anns(masks,image) def show_image(image): masks = mask_generator.generate(image) if len(masks) == 0: return sorted_anns = sorted(masks, key=(lambda x: x['area']), reverse=True) index = 1 image_list = [] for ann in sorted_anns: mask_2d = ann['segmentation'] segment_image = copy.copy(image) masked_image = mask_image(segment_image, mask_2d) image_list.append(masked_image) return image_list import gradio as gr with gr.Blocks() as demo: with gr.Row(): with gr.Column(): img_in = gr.Image(source='upload') with gr.Row(): segment_button = gr.Button("segment",variant="primary") save_button = gr.Button("segment_images",variant="primary") with gr.Row(): with gr.Column(): img_out = gr.Image() with gr.Row(): result_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery").style(grid=6, height='auto') segment_button.click(segment_image, inputs= [img_in], outputs=[img_out]) save_button.click(show_image, inputs= [img_in], outputs=[result_gallery]) demo.launch(share=True)复制
Notebook案例地址:一键分割图像
AI Gallery:https://developer.huaweicloud.com/develop/aigallery/home.html
速来体验!