摘要:对于那些希望使用华为云的云原生服务的人来说,这篇文章提供了很好的指导,让他们了解如何通过容错来保证他们的服务的可用性和稳定性。
本文分享自华为云社区《构建高可用云原生应用,如何有效进行流量管理?》,作者: breakDawn。
随着云原生的概念越来越火,服务的架构应该如何发展和演进,成为很多程序员关心的话题。大名鼎鼎的《深入理解java虚拟机》一书作者于21年推出了新作《凤凰架构》,从这本书中可以看到当前时下很多最新的技术或者理念。

因此本文以及后续都将持续沉淀发布这本书的学习笔记和思考,也欢迎购买该书进行详细学习,或者关注后续的学习笔记内容发布,了解精华内容和总结思考。
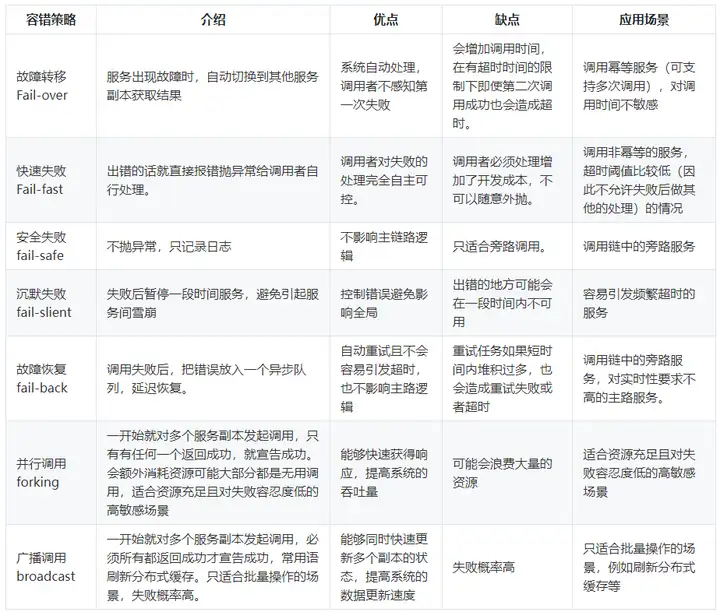
文章中介绍了故障转移、快速失败、安全失败、沉默失败、故障恢复、并行调用、广播调用等几种容错策略,我用表格的形式直观呈现一下这几种策略的区别,方便理解和选型:
1.断路器模式
即服务中发请求的地方都通过一个断路器模块来转发发送
当10秒内请求数量达到20,且失败阈值达到50%以上(这些参数都可以调整), 则认为出现问题, 于是主动进行服务熔断, 断路器收到的请求自动返回错误,不再去调用远程服务, 这样可避免请求线程各种阻塞,能及时返回报错。
中间会保持有间隔的重试直到恢复后,关闭断路。
2.舱壁隔离模式
如果一个服务中,可能要同时调用A\B\C三个服务,但是却共用一个线程池。
如果调用C服务超时,而调用C的请求源源不断打来,会造成C服务的请求线程全在阻塞,直接把整体线程池给占满了,影响了对A\B服务的调用。
一种隔离措施是对每个调用服务分别维护一个线程池。缺点是额外增加了排队、调度、上下文切换的开销,据说Hystrix线程池如果开启了服务隔离,会增加3~10ms的延迟。
另一种隔离措施是直接自己定义三个服务的计数器,当服务线程数量到达阈值,自动对这个服务调用做限流。
3.重试模式
故障转移和故障恢复这2个策略一般都是借助重试模式来处理的,进行重复调用。
重试模式应该满足以下条件才能使用:
重试模式应该有明确的终止条件,例如:
重试一定要谨慎开启, 有时候在网关、负载均衡器里也会配置一些默认的重试, 一旦链路很长且都有重试,那么系统中重试的次数将会大大增加。
流量控制需要解决以下3个问题
通过限制最大TPS来限流的话,不能够准确反映出系统的压力, 因此主流系统倾向使用HPS作为首选的限流指标。
流量计数器模式
统计每秒内的请求数是否大于阈值
缺点:
滑动时间窗模式
滑动时间窗专门解决了流量计数器模式的缺点。准备一个长度为10的数组,每秒触发1次的定时器。
缺点在于只能用于否决式限流, 必须强制失败或者降级,无法进行阻塞等待的处理。
漏桶模式
漏桶和令牌桶可以适用于阻塞等待的限流。漏桶就是一个以请求对象作为元素的先入先出队, 队列程度等于漏桶大小,当队列已满拒绝信的请求进入。比较困难的原因在于很难确定通的大小和水的流出速度,调参难度很大。
令牌桶模式
每隔一定时间,往桶里放入令牌,最多可以放X个,每次请求消耗掉一个。
可以不依赖定时器实现令牌的放入,而是根据时间戳,在取令牌的时候当发现时间戳满足条件则在那个时候放入令牌即可
前面的4个限流模式都只是单机限流,经常放在网关入口处,不适用于整个服务集群的复杂情况,例如有的服务消耗多有的服务消耗少,都放在入口处限流情况其实很多。
可以基于令牌桶的基础上,在入口网关处给不同服务加不同的消耗令牌权重,达到分布式集群限流的目的
以上主要介绍了服务容错和容错设计模式,涉及到不同的容错策略和容错设计模式,如故障转移、快速失败、安全失败、沉默失败、故障恢复、并行调用和广播调用。
这2个设计可以保证系统的稳定性和健壮性。这篇文章涉及的话题与云原生服务息息相关,因为云原生应用程序之间会频繁通过进行请求和交互,需要通过容错和弹性来保证高可用性。
因此,对于那些希望使用华为云的云原生服务的人来说,这篇文章提供了很好的指导,让他们了解如何通过容错来保证他们的服务的可用性和稳定性。
如果能通过将服务API注册到华为云提供的APIG网关上,似乎能够很方便地达成上述2个设计。
比如APIG支持断路器策略,是API网关在后端服务出现性能问题时保护系统的内置机制。当API的后端服务出现连续N次超时或者时延较高的情况下,会触发断路器的降级机制,向API调用方返回固定错误或者将请求转发到指定的降级后端。当后端服务恢复正常后,断路器关闭,请求恢复正常。APIG-断路器策略
同时APIG还提供了流量控制策略,支持从用户、凭据和时间段等不同的维度限制对API的调用次数,保护后端服务。支持按分/按秒粒度级别的流量控制,阅读了上文中提到的几个流量策略,再去看APIG里配置的流量策略值,则会很容易理解。APIG-流量控制策略
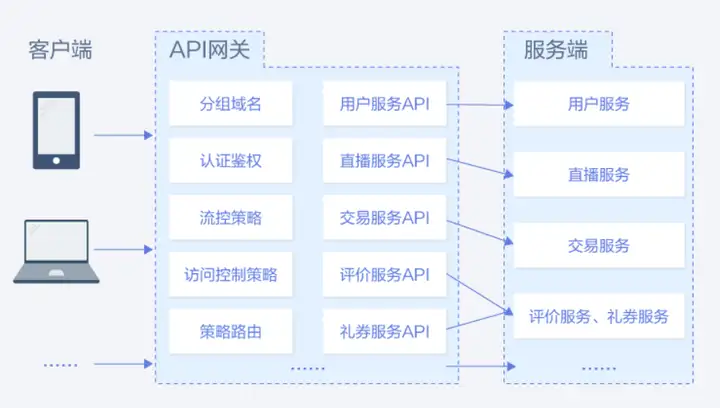
可以看到对于这些常见的经典服务设计策略,无需再重复造轮子,使用已有云服务,可以很快地实现相关功能,提升产品的上线速度和迭代效率。