摘要:条件表达式函数中出现结果集不一致问题,我们首先要考虑是否入参数据类型不一致导致出参不一致。
本文分享自华为云社区《GaussDB(DWS)条件表达式函数返回错误结果集排查》,作者:yd_211369925 。
客户使用greatest获取并返回参数列表中值最大的表达式的值,子查询中查询结果与将子查询的结果粘出来单独执行结果集不一致。
select greatest(1,2,100,-1,0,nvl(null,0)) --结果为2,select nvl(null,0)的结果为0 select greatest(1,2,100,-1,0,0) --结果为100复制
首先我们要了解greatest和nvl两个函数的用法
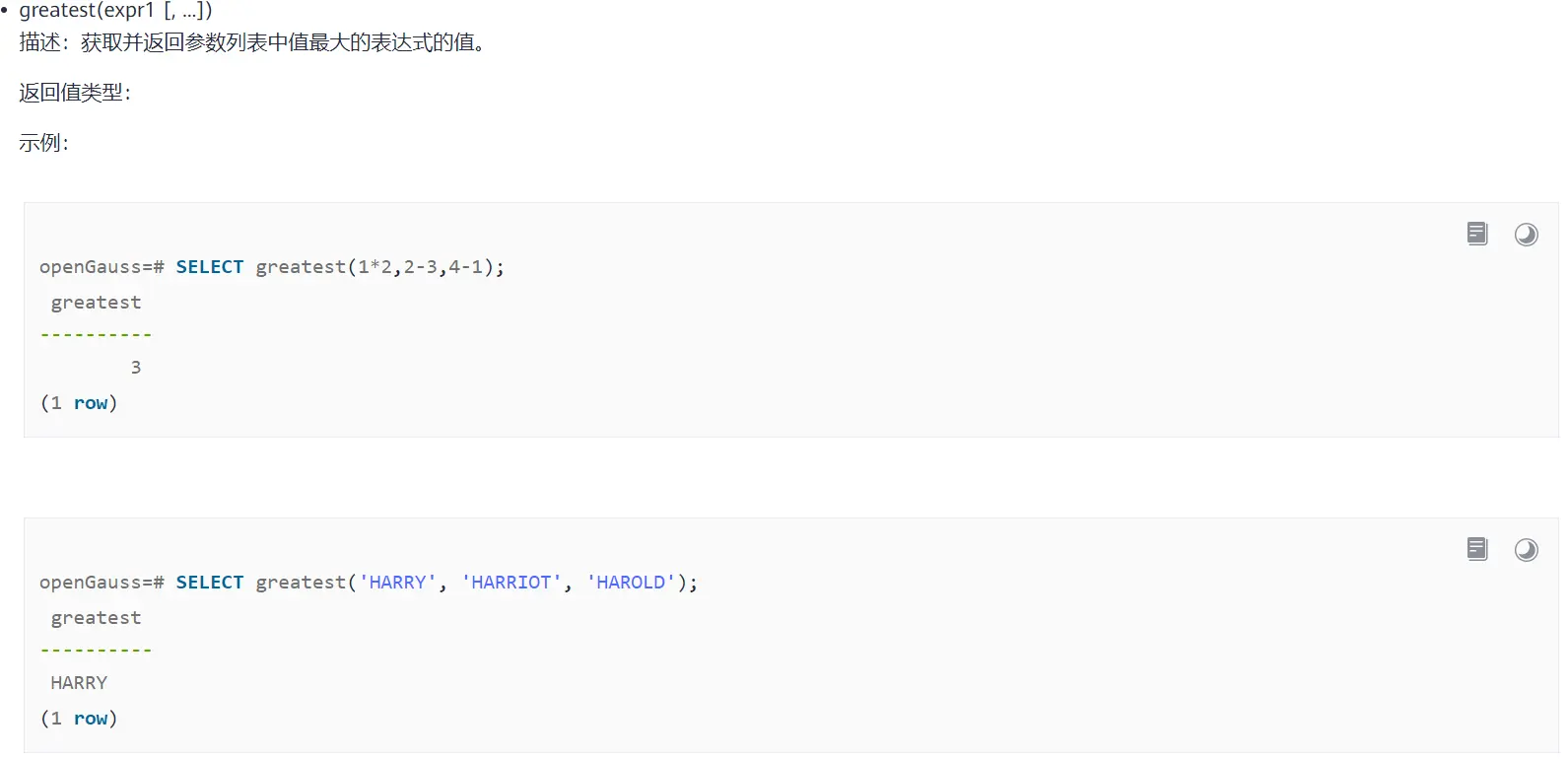

客户使用的版本为dws820环境为mysql兼容模式,nvl(null,0)结果类型为unknown的类型即为text;

第一条greatest(1,2,100,-1,0,nvl(null,0))参数中存在int和text,即按字符排序2最大;
第二条greatest(1,2,100,-1,0)参数均为int,输出按数值排序100最大;
拓展:
对于一些非条件表达式函数可以通过\df+ 函数名(这里用min来举例) 查找入参和出参的数据类型

或者先使用 select proname,proisstrict,provolatile,prorettype,proargtypes,prosrc,proshippable from pg_proc where proname = '函数名';

再使用select oid,typname from pg_type where oid =‘xxx’;(这里oid根据上述的prorettype,proargtypes来查询)

具体函数重要属性参考
GaussDB(DWS)函数下推属性介绍
https://bbs.huaweicloud.com/blogs/250351
从上述排查中可知将,改写第一条语句,使用nvl(null,0)::int替换nvl(null,0)使得greatest函数中所有数据类型均为int即可
SELECT greatest(1,2,100,-1,0,nvl(null,0)::int)复制
此时结果是,100符合客户预期结果。