摘要:迁移前后结果集row_number字段值前后不一致,前在DWS上运行不一致。
本文分享自华为云社区《GaussDB(DWS)迁移 - oracle兼容 --row_number输出结果不一致》,作者:譡里个檔 。
迁移前后结果集row_number字段值前后不一致,前在DWS上运行不一致。
这种问题大部分都是因为PARTITION BY 列 + ORDER BY 列组合起来不唯一,导致row_number()开窗函数结果集不稳定。
如果不关注PARTITION BY 列 + ORDER BY 列组合值一样的记录的排序,那么可以使用函数rank()代替函数row_number(),二者的区别请戳这里;如果关注PARTITION BY 列 + ORDER BY 列组合值一样的记录的排序,那么需要增 ORDER BY 列,以保证同一个组内所有记录的唯一性。
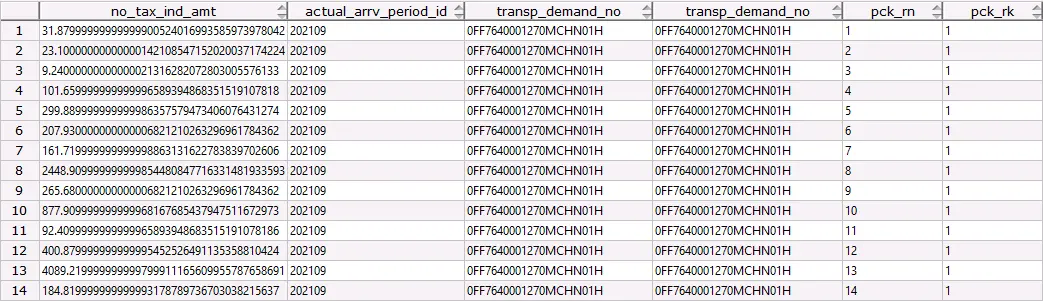
某客户反馈进行Orale迁移前,如下SQL结果集稳定;迁移后DWS运行结果和oracle不一致,且DWS本身运行结果不稳定
SELECT no_tax_ind_amt, row_number() OVER(PARTITION BY s.actual_arrv_period_id, s.transp_demand_no ORDER BY s.transp_demand_no DESC) pck_rn FROM fin_dwl_cbchnl.dwl_cbg_cst_tms_freigh_expen_f s LEFT JOIN dwrdim_dw1.dwr_dim_company_d c ON s.ship_company_key = c.company_key LEFT JOIN dwrdim_dw1.dwr_dim_supplier_d d ON s.supplier_key = d.supplier_key WHERE actual_arrv_period_id = 202109 AND s.transp_demand_no='0FF7640001270MCHN01H' ;复制
前后两次执行结果
1)第一次执行
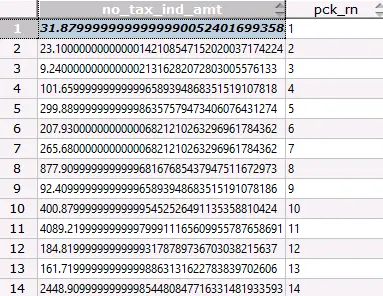
2)第二次执行
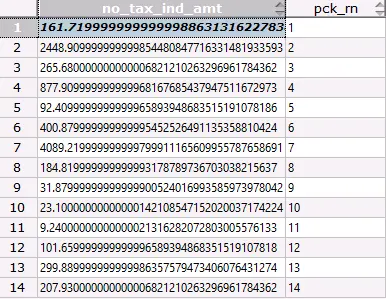
问题定位分析方位为执行如下语句
SELECT no_tax_ind_amt, s.actual_arrv_period_id, s.transp_demand_no, s.transp_demand_no, -- PARTITION BY 列 + ORDER BY 列 row_number() OVER(PARTITION BY s.actual_arrv_period_id, s.transp_demand_no ORDER BY s.transp_demand_no DESC) pck_rn, rank() OVER(PARTITION BY s.actual_arrv_period_id, s.transp_demand_no ORDER BY s.transp_demand_no DESC) pck_rk FROM fin_dwl_cbchnl.dwl_cbg_cst_tms_freigh_expen_f s LEFT JOIN dwrdim_dw1.dwr_dim_company_d c ON s.ship_company_key = c.company_key LEFT JOIN dwrdim_dw1.dwr_dim_supplier_d d ON s.supplier_key = d.supplier_key WHERE actual_arrv_period_id = 202109 AND s.transp_demand_no='0FF7640001270MCHN01H' ;复制
可以看出相同的开窗逻辑下rank()值都1,而且所有记录中s.actual_arrv_period_id, s.transp_demand_no, s.transp_demand_no(即PARTITION BY 列 + ORDER BY 列)的值都是一样的