摘要:我们提供了一键运行的notebook AI作画 Dreambooth 生成自定义主体,可以在ModelArts平台上调试开发自己的文生图模型。
本文分享自华为云社区《DreamBooth+LoRA微调生成主体》,作者: 杜甫盖房子 。
文生图风靡一时,但预训练的文生图模型无法控制生成特定的主体。DreamBooth提供了一种方法,只需要特定主体的几张图就可以微调文生图模型,生成包含特定主体的图片。例如,提供如下主体图片,给定主体名称为biu model:

微调文生图模型后,使用"biu model in the garden"作为prompt推理,将生成包含该主体的图片:

我们提供了一键运行的notebook AI作画 Dreambooth 生成自定义主体,可以在ModelArts平台上调试开发自己的文生图模型。此外,我们还提供了零代码运行的Workflow DreamBooth自定义生成主体,可以通过简单的可视化配置完成模型训练、AI应用打包、在线推理服务部署等全流程,无需任何开发即可玩转个性化文生图模型微调。
DreamBooth 是一种生成个性化文生图模型的方法,用户可以给定3~5张某个主体的图像及该主体的名称,微调文生图模型(本案例使用的是Stable Diffusion v1-4),微调后的模型可以使用主体名称作为prompt,生成对应主体的图像,如图:
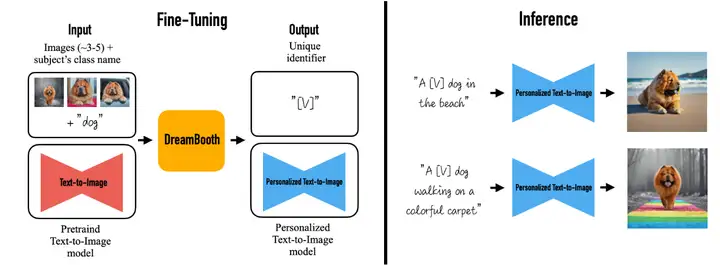
图源:DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
DreamBooth想要将定义的主体名称与特定主体绑定,同时保留主体对应类别的细节特征。因此,在构建主体名称时可以加入大类别名,如主体是一只可爱的小猫,则主体名称可以定义为"a [V] cat",其中大类名"cat"可以保留大类特征,[V]作为稀有标识符,可以避免主体受通用词组先验知识的影响。
为了减少微调导致的语义漂移,以及保持扩散模型生成内容的多样性,DreamBooth引入了prior preservation loss,利用大类的先验知识生成与训练主体相同大类的不同实例对模型进行监督:
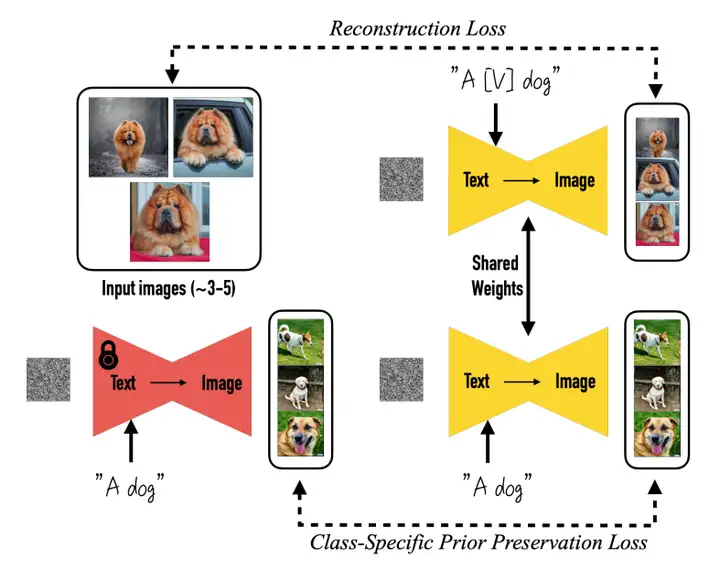
图源:DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
Low-Rank Adaptation of Large Language Models (LoRA) 是一种训练方法,可以在消耗较少内存的同时加速大模型的训练。大模型通常具有很多参数,直接微调大模型将是一个缓慢而昂贵的过程。在Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning中提出一个洞见:预训练语言模型微调后,权重矩阵中表征特征的部分其实是很低秩的。作者受此启发,认为模型微调时,更新的权重表征特征的部分应该也是低秩的,即在模型微调时,权重可以表示为:W=W0+ΔWW=W0+ΔW,其中,W0W0为不更新的预训练权重矩阵,ΔWΔW为实际更新的、可以进行低秩分解的权重矩阵,如图,蓝色部分为不更新的预训练权重,橙色部分为分解为两个低秩矩阵的微调权重:
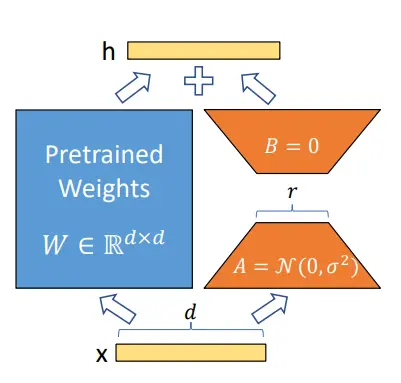
图源:LoRA: Low-Rank Adaptation of Large Language Models
LoRA有几个显而易见的优势:
我们提供了两种形式的案例:一键运行的notebook AI作画 Dreambooth 生成自定义主体 和零代码运行的Workflow DreamBooth自定义生成主体。
notebook使用上灵活程度更高,适合有一定代码能力的朋友玩一下。Workflow封装程度更高,提供了详细的使用文档,同时包含了AI应用等节点,不需要写任何代码也可以生成自己的模型并在线测试。