摘要:合理地管理和分配系统资源,是保证数据库系统稳定高效运行的关键。
本文分享自华为云社区《GaussDB(DWS)资源管理能力介绍与应用示例》,作者: 门前一棵葡萄树 。
数据库运行过程中使用的公共资源包含:系统资源(CPU、内存、网络等)和数据库共享资源(锁、计数等)。作业运行过程中总是希望获得更多的公共资源,以获得最好的执行性能。但是公共资源的滥用可能导致数据库系统的不稳定,引发资源过载,影响高优业务的QoS(服务质量),甚至阻塞业务运行。因此,合理地管理和分配系统资源,是保证数据库系统稳定高效运行的关键。
资源管理的目标:
资源池是一种用于对系统资源进行划分的技术,通过为资源池设置资源上限的方式,实现对其内运行作业的资源管控。资源池可以帮助系统管理员更好地管理和分配系统资源,提高系统的可用性和稳定性。
GaussDB(DWS)提供了资源管理功能,借助资源池实现业务之间的资源隔离和查询调度(不同业务路由至不同资源池)。GaussDB(DWS)支持两种路由策略:
实际应用过程中,建议优先使用用户-资源池的路由方式;在用户-资源池的路由方式无法满足隔离诉求时,使用query_band负载识别实现业务隔离。
GaussDB(DWS)支持负载管理、资源管控、异常规则、查询过滤器以及负载计划等资源管理能力,不同的资源管理能力有不同的使用场景,实际应用中可能会用到其中1~N个资源管理能力。
支持基于并发和估算内存的查询调度,防止并发过大引发资源争抢严重、导致查询堆积。多CN场景下,CN之间互相不感知负载情况,因此无法精确控制整个集群的并发和内存使用,可能触发内存不足报错。因此为保证多CN场景下的并发和内存可控,设计实现CCN用于查询的统一调度。CM在第一次集群启动时,通过集群部署形式,选择编号最小的CN作为CCN,CCN故障之后,由CM选择新的CCN进行替换。
虽然CCN管控可以实现更为精准的管控,但是CCN管控逻辑更为复杂且涉及CN-CCN间通信,通信延迟(10ms~1s之间)和复杂的管控逻辑可能导致作业性能不稳定,此外CCN还可能成为提高系统并发的瓶颈。因此设计实现“短查询加速”功能,实现对简单查询和复杂查询的分别管控。复杂查询执行时间长、内存消耗大,CCN管控对其性能影响有限;简单查询执行时间短、内存消耗小,CN管控可以降低管控对其的性能影响。CCN管控的主要目的是防止内存不足报错,因此我们根据估算内存对查询进行分类:
为提升简单查询性能,默认情况下简单查询只进行并发控制,而不进行内存和CPU管控。实际应用场景下,优先级低的业务可能性能不敏感,而且需要精准管控其使用的CPU和内存资源,此时简单查询也需要进行资源管控。为适应更多的使用场景,短查询加速功能支持开启和关闭:
为了便于区分,我们将CN管控称为快车道,CCN管控称为慢车道。快车道只在CN上进行并发控制,不支持内存和CPU管控;慢车道在CCN上进行并发和内存控制,同时支持CPU管控。其中,快车道并发对应资源池max_dop参数,慢车道并发对应资源池active_statements参数,慢车道内存对应资源池mem_percent参数。
GaussDB(DWS)基于cgroups实现了两种CPU管控能力:基于cpu.shares的共享配额管控和基于cpuset的专属限额管控。
专属限额限制资源池内作业可以使用的CPU核,隔离更为彻底,用于防止低优作业占用过多CPU,影响高优作业性能。
共享配额仅在CPU繁忙时生效,不同资源池之间按照配额比例轮询占用CPU,不同业务之间存在CPU争抢,可能影响业务性能。
GaussDB(DWS)支持基于SP+DWRR算法的网络调度与基于令牌桶的网络流控,实现资源池之间按比例的网络调度的同时,实现了网络欠佳SQL的降级与流控。
空间管控主要有两层目的:一是防止磁盘满,一是对业务使用磁盘空间进行限制。GaussDB(DWS)支持以下空间管控能力:
数据库只读:CM每10分钟检测一次数据盘使用率,使用率超过阈值时,设置数据库只读;使用率低于阈值时,解除数据库只读。数据库只读情况下,只允许只读作业执行。数据库只读后,通过读写事务内执行DROP/TRUNCATE清理磁盘空间: " START TRANSACTION READ WRITE;DROP/TRUNCATE TABLE;COMMIT; "。
用户空间管控:限制用户在单个CN/DN上可以使用的空间上限,根据表的属主(owner)进行管控,而不管执行插入的用户是谁。相关语法:CREATE ALTER USER xxx PERM SPACE ‘xxx G/M/K’。
Schema空间管控:提供Schema级别的单实例空间管控能力,相关语法:CREATE/ALTER SCHEMA xxx WITH PERM SPACE 'xx G/M/K'。
异常规则用于预防单个作业占用资源过多、执行时间过长,防止单个作业长时间大量占用资源,导致系统整体吞吐下降、影响其他作业性能。GaussDB(DWS)支持以下异常规则:

GaussDB(DWS)查询过滤器提供查询过滤功能,对加入黑名单的作业进行过滤,禁止执行。主要应用场景包含以下两种:
用户在不同时间需要重点保障的业务可能不一样,每个业务所需的并发和资源在不同时间段也可能不相同,因此用户在不同时间所需的资源管理配置可能就有所不同。资源管理计划支持在指定时间自动切换资源管理配置,用户可按需创建多个资源管理计划。创建资源管理计划、配置计划生效时间并启动计划后,GaussDB(DWS)将在计划生效时间自动切换资源配置。
首先,需要明确的一点是资源管理不是万能的,并不是所有的资源类问题资源管理都能解决,大部分资源不足类问题资源管理基本都解决不了。 其次需要清楚资源管理有两个主要目的:其一是为了避免资源的无序使用,从而防止系统级故障的发生,同时避免查询堆积的情况出现;其二是为了实现业务之间的资源隔离,防止不同业务之间因为资源争抢而导致高优业务性能下降,从而影响高优业务的QoS。明确了以上几点,我们再来看资源管理能干什么、不能干什么,可能就更好理解了:
资源管理的目的是对业务进行隔离管控,因此设计资源管理方案前,首先需要确认用户业务场景:业务分类、业务优先级、业务类型、业务并发情况、业务执行时间段以及业务高峰时间段。
为了避免过多的资源池对整体吞吐率产生负面影响,同时为了简化资源管理方案,建议将资源池数量控制在5个以下,最好是3个及以下。如果业务分类较少(3个及以下),可以为每个业务分类创建一个资源池,以便更好地进行分类管理。如果业务分类较多,可以将优先级相同的业务归为同一类,并使用同一个资源池来管理。
业务优先级一般分为以下几类:
确认业务场景后,下一步就需要和用户明确管控诉求。第一步确认业务场景后,其实已经可以形成初步资源管理方案,比如:应该创建几个资源池、限制低优业务并发和资源使用(限额)、是否使用资源管理计划等。
示例:
业务场景:用户业务包含:入库、查询和外部接入。其中入库和查询使用同一用户(user1),外部接入使用一个用户(user2);入库优先级略低于查询且入库不能影响查询性能,外部接入优先级很低、接受报错和长时间不出结果;入库并发较大、消耗CPU较高。
对于以上业务场景,有以下基本诉求和初步资源管理方案:
初步资源管理方案资源池配置如下:
单CN并发上限:max_active_statements = 300/500 ??
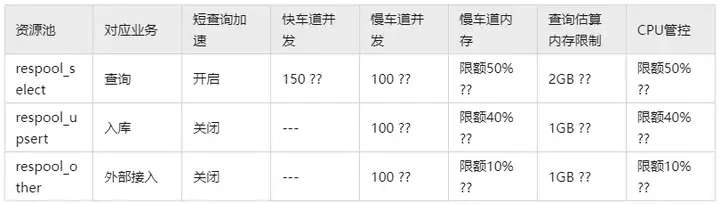
其中,参数值后有“??”的表示参数大小为初步预估,需要与用户沟通确认参数最终大小。
形成初步资源管理方案后,与用户针对资源管理方案进行讨论,确认管控诉求:
以上只是列举了常见的管控诉求讨论点,实际应用中可以多发散。
以上一章节中资源管理方案为例,说明如何配置资源管理方案。
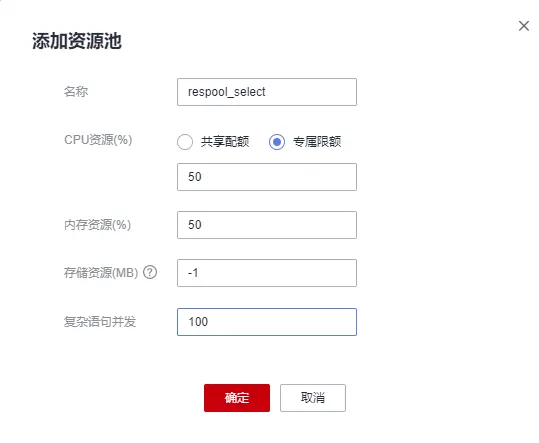
如下图所示,以respool_select资源池为例,按照用户指南添加资源池中步骤添加资源池。名称填写“respool_select”;CPU资源选择专属限额,限额50%;内存资源限额50%;查询并发(特指慢车道并发)上限100。填写完成后点击确认,完成资源池添加。资源池操作说明详见:添加资源池、修改资源池、删除资源池。
添加资源池完成后,显示下图所示界面。刚刚配置完成的参数在资源配置标签内显示;短查询加速默认开启且不限制简单语句并发上限;中间位置显示资源池关联的异常规则,默认情况下关联有两个默认异常规则:单DN平均消耗CPU占比不超过50%,单DN算子下盘不超过数据盘的1/10,超过限制后作业报错退出;最下方显示资源池关联的用户,点击关联用户按钮将“查询用户”关联至该资源池。同理创建另外两个资源池,并将“外部接入用户”关联至respool_other资源池。
注:对于需要设置自定义异常规则的资源池,在下方异常规则标签栏点击编辑即可配置异常规则。
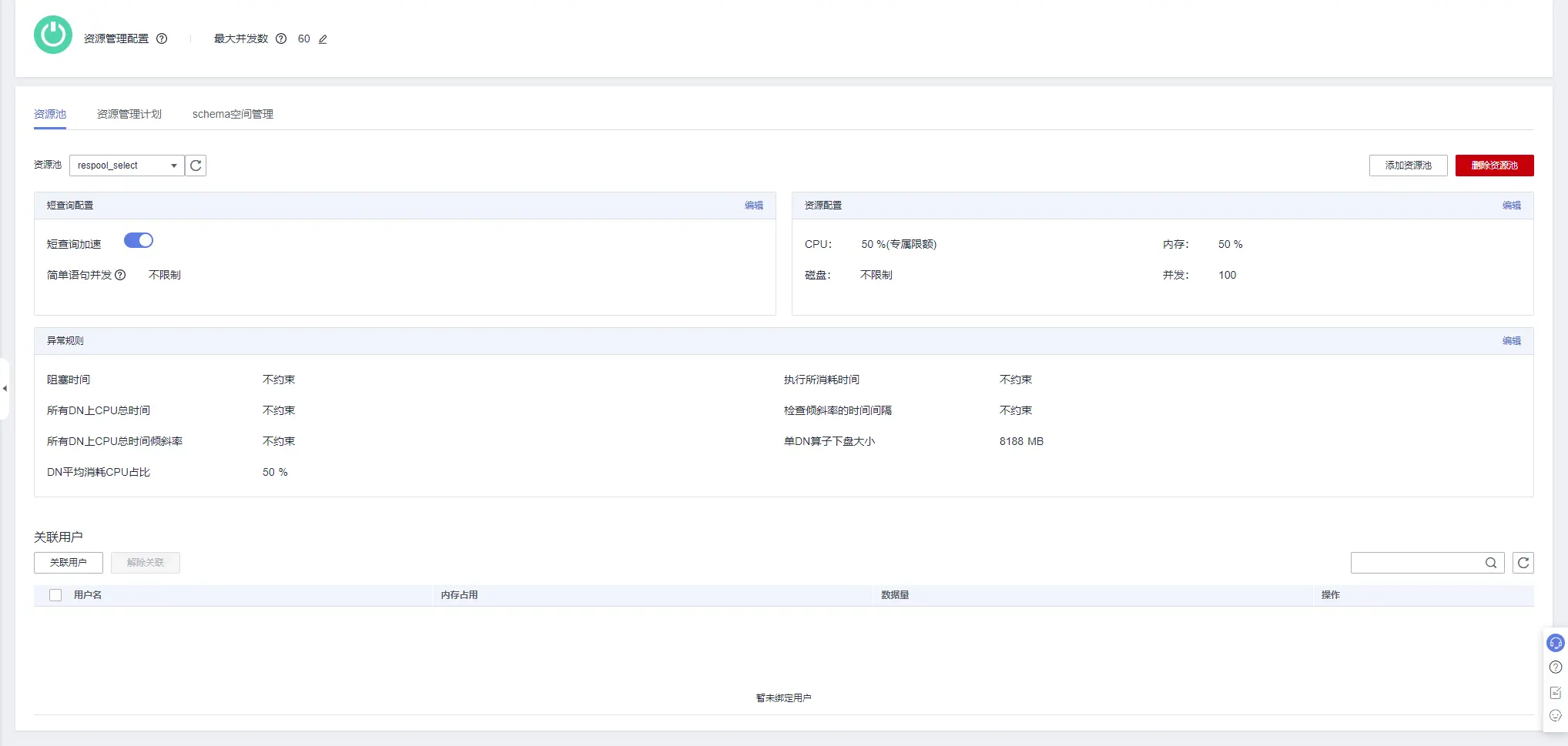
在资源池下拉列表中选择刚刚添加的资源池respool_select,点击短查询配置右上方的编辑,修改简单语句并发为150,修改完成后点击保存。
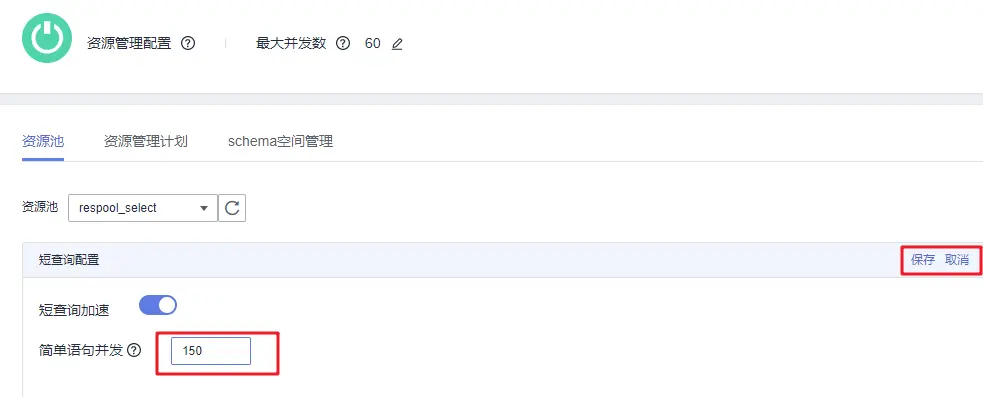
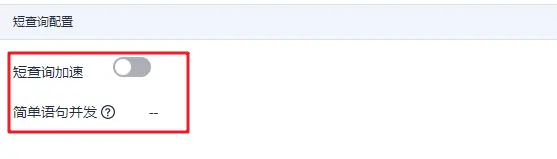
对于另外两个资源池,需要关闭短查询加速,在资源池下拉列表中选择对应资源池后,点击短查询配置中“短查询加速”开关,关闭短查询加速。
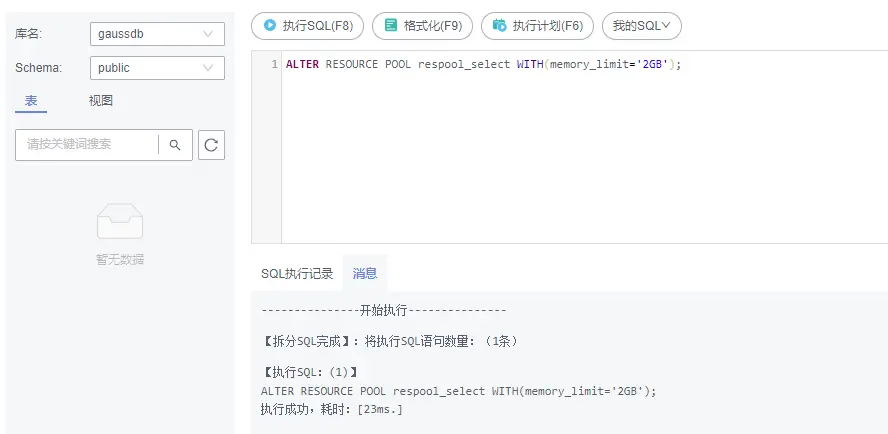
查询估算内存上限暂时还不支持在界面配置,可以通过DAS执行SQL直接修改:
1. 修改用户入库业务,入库业务会话内设置query_band:SET query_band='Jobname=upsert';--执行业务;--作业执行完重置query_band:reset query_band;示例:
postgres=> SET query_band='Jobname=copy_upsert'; SET postgres=> INSERT INTO t1 SELECT generate_series(1,10000); INSERT 0 10000 postgres=> RESET query_band; RESET
2. 配置query_band,将入库业务路由至资源池respool_upsert运行:
postgres=# SELECT * FROM gs_wlm_set_queryband_action('Jobname=copy_upsert', 'respool=respool_upsert'); gs_wlm_set_queryband_action ----------------------------- t (1 row)
3. 查询pg_queryband_action视图,确认query_band配置成功:
postgres=# select * from pg_queryband_action; qband | respool_id | respool | priority | qborder ---------------------+------------+----------------+----------+--------- Jobname=copy_upsert | 2147483648 | respool_upsert | medium | -1 (1 row)
4. 运行入库作业过程中,查询TopSQL实时视图,确认query_band是否生效
postgres=# SELECT username, query_band, resource_pool, substr(query, 1, 30) FROM pgxc_wlm_session_statistics WHERE query_band IS NOT NULL; username | query_band | resource_pool | substr ----------+---------------------+----------------+-------------------------------- user_elk | Jobname=copy_upsert | respool_upsert | INSERT INTO t1 SELECT generate (1 row)
1. 需要使用资源管理计划的,可以参考资源管理计划操作配置资源管理计划。
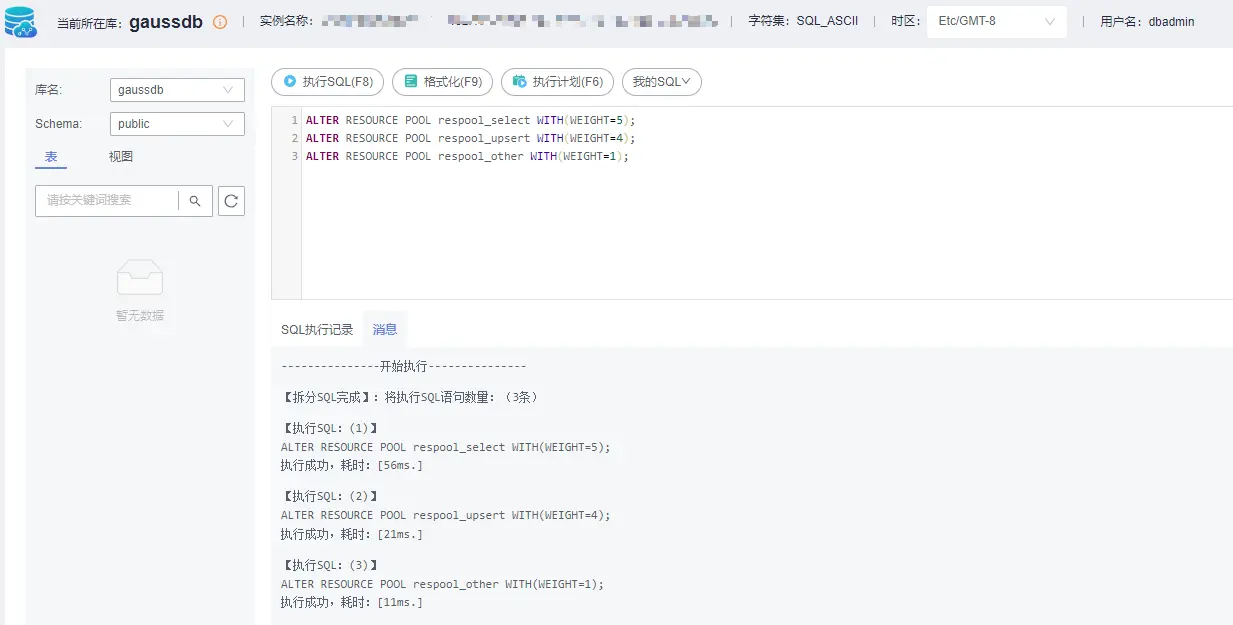
2. GaussDB(DWS) 8.2.1及以上版本支持网络资源管控,假设三个资源池网络带宽权重配比为respool_select:respool_upsert:respool_other = 5:4:1,使用DAS执行以下SQL配置网络管控:
ALTER RESOURCE POOL respool_select WITH(WEIGHT=5); ALTER RESOURCE POOL respool_upsert WITH(WEIGHT=4); ALTER RESOURCE POOL respool_other WITH(WEIGHT=1);
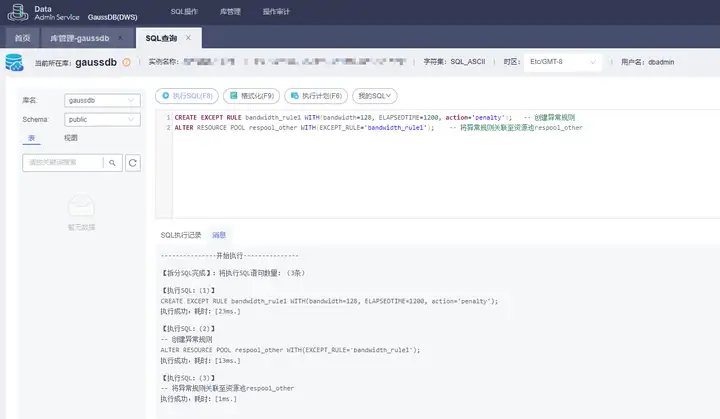
配置示例参见下图:
假设外部接入业务运行超过20min,且网络带宽占用超过128MB降级:
CREATE EXCEPT RULE bandwidth_rule1 WITH(bandwidth=128, ELAPSEDTIME=1200, action='penalty'); -- 创建异常规则 ALTER RESOURCE POOL respool_other WITH(EXCEPT_RULE='bandwidth_rule1'); -- 将异常规则关联至资源池respool_other
配置示例参见下图: