摘要:本文将介绍如何在 Docker 环境下搭建 MS SQL Server 的主从同步,帮助读者了解主从同步的原理和实现方式,进而提高数据的可靠性和稳定性。
在当今信息化的时代,数据的安全性和稳定性显得尤为重要。数据库是许多企业和组织存储和管理数据的核心,因此如何保证数据库的高可用性和数据的同步性是一个非常关键的问题。而基于主从同步的技术可以有效地解决这个问题。本文将介绍如何在 Docker 环境下搭建 MS SQL Server 的主从同步,帮助读者了解主从同步的原理和实现方式,进而提高数据的可靠性和稳定性。
主从同步是一种常用的技术,用于在多个 SQL Server 实例之间保持数据同步。在主从同步中,一个 SQL Server 实例被用作数据的源,而另一个或多个 SQL Server 实例则作为数据的接收端。当主节点上的数据发生更改时,这些更改将被捕获并保存到一个事务日志中。从节点会定期检查主节点的事务日志,并将主节点上的更改应用到自己的数据库中,从而保持两个数据库之间的数据同步。
在开始安装之前,需要确保CentOS上已经安装了Docker和Docker Compose。可以通过以下命令来进行安装:
sudo yum remove docker \ docker-client \ docker-client-latest \ docker-common \ docker-latest \ docker-latest-logrotate \ docker-logrotate \ docker-selinux \ docker-engine-selinux \ docker-engine复制
按照下列步骤依次进行安装,中间过程直接略过
# 1.安装需要的软件包: sudo yum install -y yum-utils # 2.设置docker的stable存储库: sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo # 3.安装docker: sudo yum install -y docker-ce docker-ce-cli containerd.io # 4.启动docker服务: sudo systemctl start docker # 5.设置开机自启动docker服务: sudo systemctl enable docker复制
挖坑002:后续会写关于docker文章,对于docker image 逻辑原理,进行讲解
问答区有人提问该问题:https://ask.csdn.net/questions/7923009/54161100
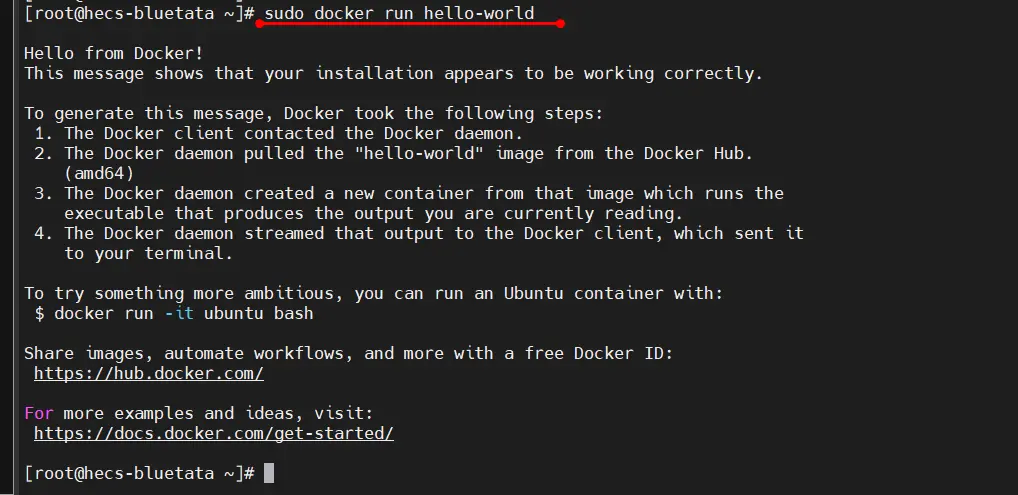
sudo docker run hello-world Hello from Docker! This message shows that your installation appears to be working correctly. ...复制
在进行主从搭建之前,需要先创建一个 Docker 网络。这个网络用于连接所有的 SQL Server 容器。
在创建网络之前,需要先确认已经启动了 Docker:
sudo systemctl start docker复制
然后,可以使用以下命令来创建一个名为sync-net的 Docker 网络:
[root@hecs-bluetata ~]# docker network create -d bridge sync-net 538c142757e91c0b798ce0e45dc02b6038f00adaf37cfe3b09659dea8c950c93复制
其中参数 -d 指定了网络的类型,bridge 指的是桥接网络,sync-net 指的是新创建的网络的名称。
创建 SQL Server 容器之前,需要先准备 SQL Server 的 Docker 镜像。可以通过以下命令来获取 SQL Server 2019 的 Docker 镜像:
docker pull mcr.microsoft.com/mssql/server:2019-latest复制
获取到 Docker 镜像之后,就可以创建 SQL Server 容器了。可以通过以下命令来创建2个 SQL Server 容器,分别命名为 sqlserver-master、和 sqlserver-slave,并加入所创建的 Docker 网络中。
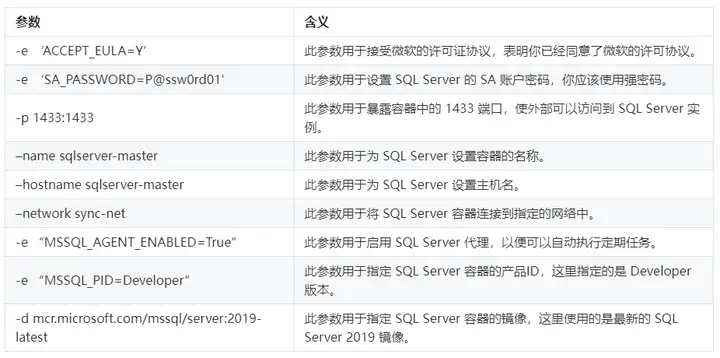
docker run --name sqlserver-master --hostname sqlserver-master --network sync-net \ -p 1433:1433 \ -e 'ACCEPT_EULA=Y' \ -e 'SA_PASSWORD=P@ssw0rd01' \ -e "MSSQL_AGENT_ENABLED=True" \ -e "MSSQL_PID=Developer" \ -d mcr.microsoft.com/mssql/server:2019-latest docker run --name sqlserver-slave --hostname sqlserver-slave --network sync-net \ -p 1434:1433 \ -e 'ACCEPT_EULA=Y' \ -e 'SA_PASSWORD=P@ssw0rd02' \ -e "MSSQL_AGENT_ENABLED=True" \ -e "MSSQL_PID=Developer" \ -d mcr.microsoft.com/mssql/server:2019-latest复制
针对上述命令,相关参数的解释:
请确确保在创建上述 Docker 的过程中没有错误。
如果在创建过程中出现端口占用,或者名称占用等错误,可以查看相应容器,选择性的删除容器后,重新创建,相关命令:
docker ps -a docker rm d3d3a4712b5f docker stop d3d3a4712b5f复制
进入 SQL Server 主节点容器,并创建主从同步端点:
docker exec -it sqlserver-master /opt/mssql-tools/bin/sqlcmd \ -S localhost -U SA -P P@ssw0rd01 \ -Q "CREATE ENDPOINT endpoint_mirroring STATE = STARTED AS TCP (LISTENER_PORT=7022) FOR DATABASE_MIRRORING (ROLE=PARTNER)"复制
进入 SQL Server 从节点容器,并创建主从同步端点:
docker exec -it sqlserver-slave /opt/mssql-tools/bin/sqlcmd \ -S localhost -U SA -P P@ssw0rd02 \ -Q "CREATE ENDPOINT endpoint_mirroring STATE = STARTED AS TCP (LISTENER_PORT=7022) FOR DATABASE_MIRRORING (ROLE=PARTNER)"复制

回到 SQL Server 主节点容器,并创建主从同步数据库:
docker exec -it sqlserver-master /opt/mssql-tools/bin/sqlcmd \ -S localhost -U SA -P P@ssw0rd01 \ -Q "CREATE DATABASE mydb" \ -Q "BACKUP DATABASE mydb TO DISK='/var/opt/mssql/data/mydb.bak'" \ -Q "RESTORE DATABASE mydb WITH NORECOVERY" \ -Q "ALTER DATABASE mydb SET PARTNER = 'TCP://sqlserver-slave:7022'"复制
回到 SQL Server 从节点容器,并创建主从同步数据库:
docker exec -it sqlserver-slave /opt/mssql-tools/bin/sqlcmd -S localhost -U SA -P P@ssw0rd02 docker exec -it sqlserver-slave /opt/mssql-tools/bin/sqlcmd -S localhost -U SA -P P@ssw0rd02' \ -Q "CREATE DATABASE mydb" \ -Q "RESTORE DATABASE mydb FROM DISK='/var/opt/mssql/data/mydb.bak' WITH NORECOVERY" \ -Q "ALTER DATABASE mydb SET PARTNER = 'TCP://sqlserver-master:7022'"复制
回到 SQL Server 主节点容器,并启动主从同步:
docker exec -it sqlserver-master /opt/mssql-tools/bin/sqlcmd ` -S localhost -U SA -P P@ssw0rd01 \ -Q "ALTER DATABASE mydb SET PARTNER SAFETY OFF" \ -Q "ALTER DATABASE mydb SET PARTNER SAFETY ON" \复制
回到 SQL Server 主节点容器,并查看主从同步状态:
docker exec -it sqlserver-master /opt/mssql-tools/bin/sqlcmd \ -S localhost -U SA -P P@ssw0rd01 \ -Q "SELECT database_id, synchronization_state_desc FROM sys.database_mirroring WHERE database_id = DB_ID('mydb')"复制
可以看到以下的输出结果:
database_id synchronization_state_desc ----------- ------------------------ 5 SYNCHRONIZED复制
这表示主从同步已经成功地建立,并且 mydb 数据库已经在主从节点之间同步。
注意:这里我这里使用了开发版的 SQL Server 镜像,如果你在生产环境中使用 SQL Server,请使用适当版本的镜像,并根据需要进行调整。
本文介绍了在 Docker 环境下搭建 MS SQL Server 的主从同步,并演示了如何进行配置和管理。通过本文的学习,你可以了解主从同步技术的实现原理和具体操作方法,并为提高数据可靠性和稳定性提供了一种有效的解决方案。同时,也需要认真考虑主从同步的一些限制和要求,并根据实际情况进行配置和管理。