本文分享自华为云社区《驾驭网络技术的未来:探索Reactor网络模型在当今应用领域的革新》,作者: Lion Long 。
本文介绍了Linux网络设计中的Reactor网络模型及其在实际应用中的重要性。Reactor模型是一种经典的事件驱动设计模式,广泛应用于构建高性能、可扩展的网络服务器。我们将探讨Reactor模型的基本原理和组成部分,并详细介绍了Reactors模型在Linux网络编程中的实现方式。
reactor是将对IO的检测转换为对事件的处理,是一种异步事件机制。reactor会使用IO多路复用进行IO检测,IO多路复用器一般是:select、poll、epoll。
reactor大致逻辑:
(1)socket()创建一个套接字,listenfd;
(2)bind()、listen()配置listenfd,绑定和监听;
(3)listenfd注册读事件,交由epoll管理;
(4)读事件触发,回调accept;
(5)客户端连接clientfd组成读事件;
(6)相关事件调用相关回调函数
接收客户端连接。
//... int epfd=epoll_create(1);//创建epoll对象 //... int listenfd=socket(AF_INET,SOCK_STREAM,0);//创建套接字 //... struct epoll_event ev; ev.events=EPOLLIN; epoll_ctl(epfd,EPOLL_CTL_ADD,listenfd,&ev)//注册事件 //... // 当触发listenfd的读事件,调用accept接收连接 struct sockaddr_in clientaddr; socklen_t len=sizeof(clientaddr); int clientfd=accept(listenfd,(struct sockaddr *)&clientaddr,&len); struct epoll_event ev; ev.events=EPOLLIN; epoll_ctl(epfd,EPOLL_CTL_ADD,clientfd,&ev)//注册新连接的读事件 //...
连接第三方服务。
//... int epfd=epoll_create(1);//创建epoll对象 //... int fd=socket(AF_INET,SOCK_STREAM,0);//创建套接字 //... struct sockaddr_in clientaddr; socklen_t len=sizeof(clientaddr); connect(fd,(struct sockaddr *)&clientaddr,&len);//连接服务 //... struct epoll_event ev; ev.events=EPOLLOUT; epoll_ctl(epfd,EPOLL_CTL_ADD,fd,&ev)//注册事件 //... // 当触发fd的写事件,连接建立成功 if(status==e_connecting && ev.events==EPOLLOUT) { status=e_connected; epoll_ctl(epfd,EPOLL_CTL_DEL.fd,NULL); } //...
//... if(ev.events & EPOLLRDHUP) { // 关闭服务器读端 close_read(fd); } if(ev.events & EPOLLHUP) { // 关闭服务器读写端 close(fd); } //...
// ... if(ev.events & EPOLLIN) { while(1) { int n=recv(clientfd,buffer,buffer_size,0); if(n<0) { if(errno==EINTR) continue; if(errno==EWOULDBLOCK) break; close(clientfd); } else if(n==0) { close_read(); } else { // 处理业务 } } // ... } // ...
// ... if(ev.events & EPOLLOUT) { int n=send(clientfd,buffer,buffer_size,0); if(n<0) { if(errno==EINTR) continue; if(errno==EWOULDBLOACK) { struct epoll_event e; e.events=EPOLLOUT; epoll_ctl(epfd,EPOLL_CTL_ADD,clientfd,&e)//注册事件 return; // break; } close(clientfd); } else if(n==buffer_size) { epoll_ctl(epfd,EPOLL_CTL_DEL,clientfd,NULL); // epoll_ctl(epfd,EPOLL_CTL_MOD,clientfd,&e); } // ... } //...
何为”惊群“?网络编程经常使用多线程、多进程模型,每个线程或进程中都有一个epoll对象,通过socket()、bind()、listen()生成的listenfd可能会给多个epoll对象管理,当一个accept到来时所有的epoll都收到通知,所有进程或线程同时响应这一事件,然而最终只有一个accept成功。这就是”惊群“。
水平触发:当读缓冲区中有数据时,一直触发,直到数据被读完。
边沿触发:来一次事件触发一次。读写操作一般需要配合循环才能全部读写完成。
主要是三方面原因:
(1)多线程环境下,一个listenfd会被多个epoll(IO多路复用器)对象管理,当一个连接到来时所有的epoll都收到通知,所有的epoll都会去响应,但最终只有一个accept成功;如果使用阻塞,那么其他的epoll将一直被阻塞着。所以最好使用非阻塞IO及时返回。
(2)边沿触发下,事件触发才会读事件,那么需要在一次事件循环中把缓冲区读空;如果使用阻塞模式,那么当读缓冲区的数据被读完后,就会一直阻塞住无法返回。
(3)select bug。当某个socket接收缓冲区有新数据分节到达,然后select报告这个socket描述符可读,但随后,协议栈检查到这个新分节检验和错误,然后丢弃了这个分节,这时调用recv/read则无数据可读;如果socket没有设置成nonblocking,此recv/read将阻塞当前线程。
不是,也可以使用阻塞模式。比如MySQL使用select接收连接,然后一个连接使用一个线程进行处理;也可以使用一个系统调用先获取读缓冲区的字节数,然后读一次就把数据读完,但是这样就导致效率比较低。
int n=EVBUFFER_MAX_READ_DEFAULT; ioctl(fd,FIONREAD,&n);//获取读缓冲区的数据字节数
使用单个reactor的场景和使用多个reactor的场景。使用多个reactor又有多线程和多进程的不同用法。
redis是一种key-value结构、有丰富的数据结构、对内存进行操作的网络数据库组件。redis的命令处理是单线程的。
要理解redis为什么只使用单个reactor,需要明白redis的命令处理是单线程的。
redis提供丰富的数据结构,对这些数据结构进行加锁非常复杂,所以redis使用单线程进行处理;因为使用单线程进行命令处理,核心业务逻辑是单线程,那么使用再多的reactor是无法处理过来的;所以,redis使用单个reactor。
另外,redis操作具体命令的时间复杂度比较低,更加没有必要使用多个reactor。
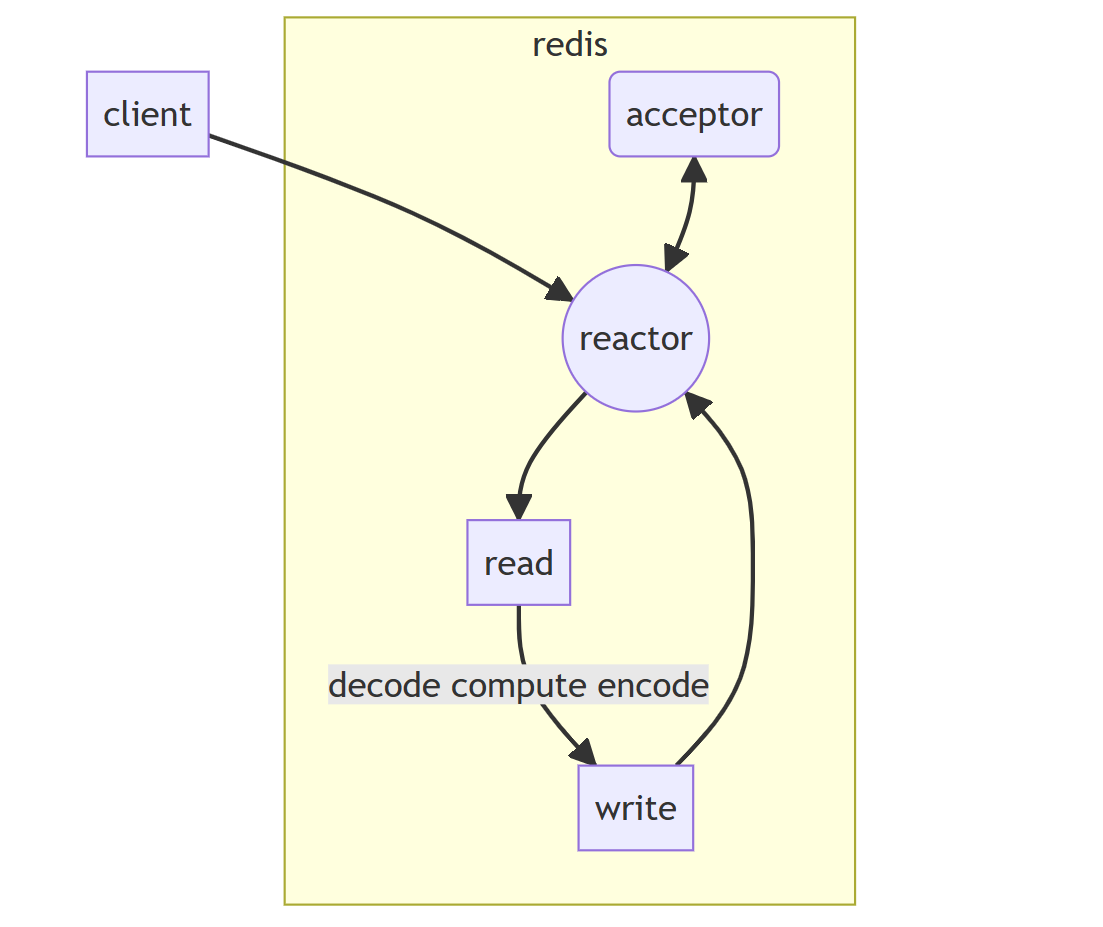
对业务逻辑进行了优化,引入IO线程:
接收完数据后,将数据抛到IO线程进行处理;发送数据之前,将打包数据放在IO线程进行处理,再发送出去。参考上图,就是将(read+decode)放到线程中处理,将(encode+write)放在线程中处理。
原因:
对于单线程而言,当接收的数据或发送的数据过大时,会造成线程负载过大,需要引用多线程做IO数据处理。特别是解协议过程,数据庞大而且耗时,需要开一个IO线程进行处理。
场景例子:
客户端上传日志记录;客户端获取排行榜记录。
创建一个epoll对象:

创建套接字,绑定监听:
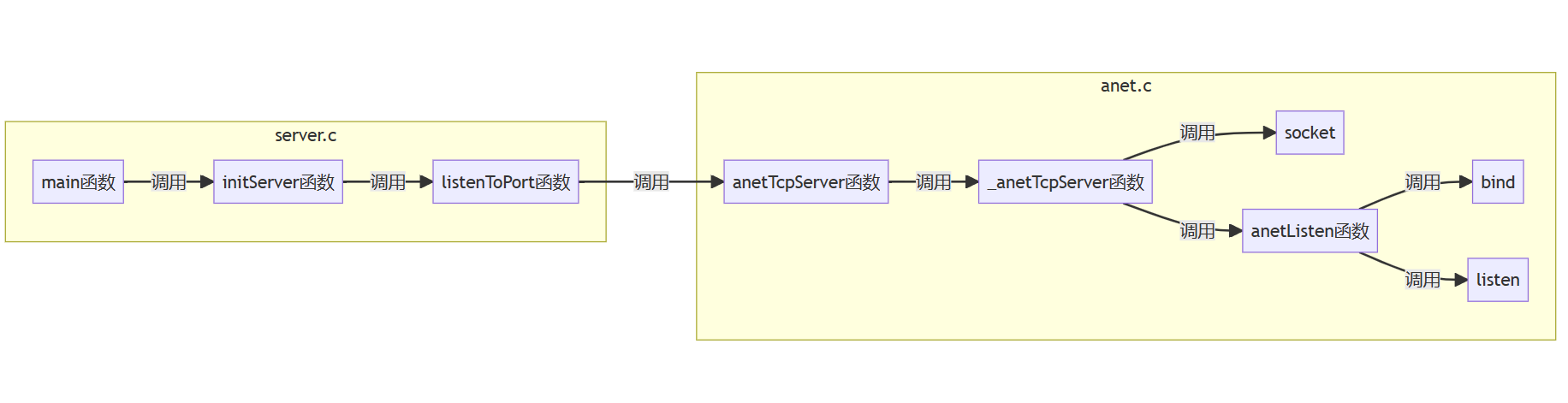
listenfd放到epoll管理:
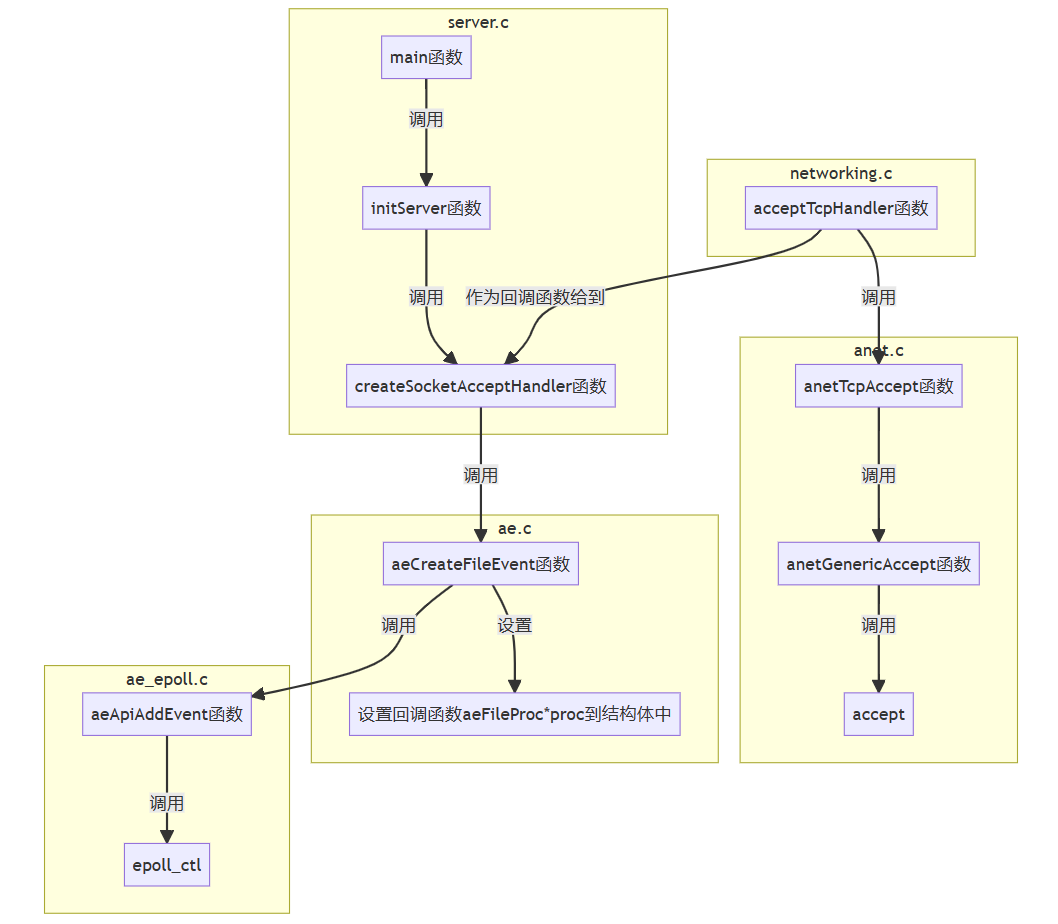
监听事件:

处理事件:
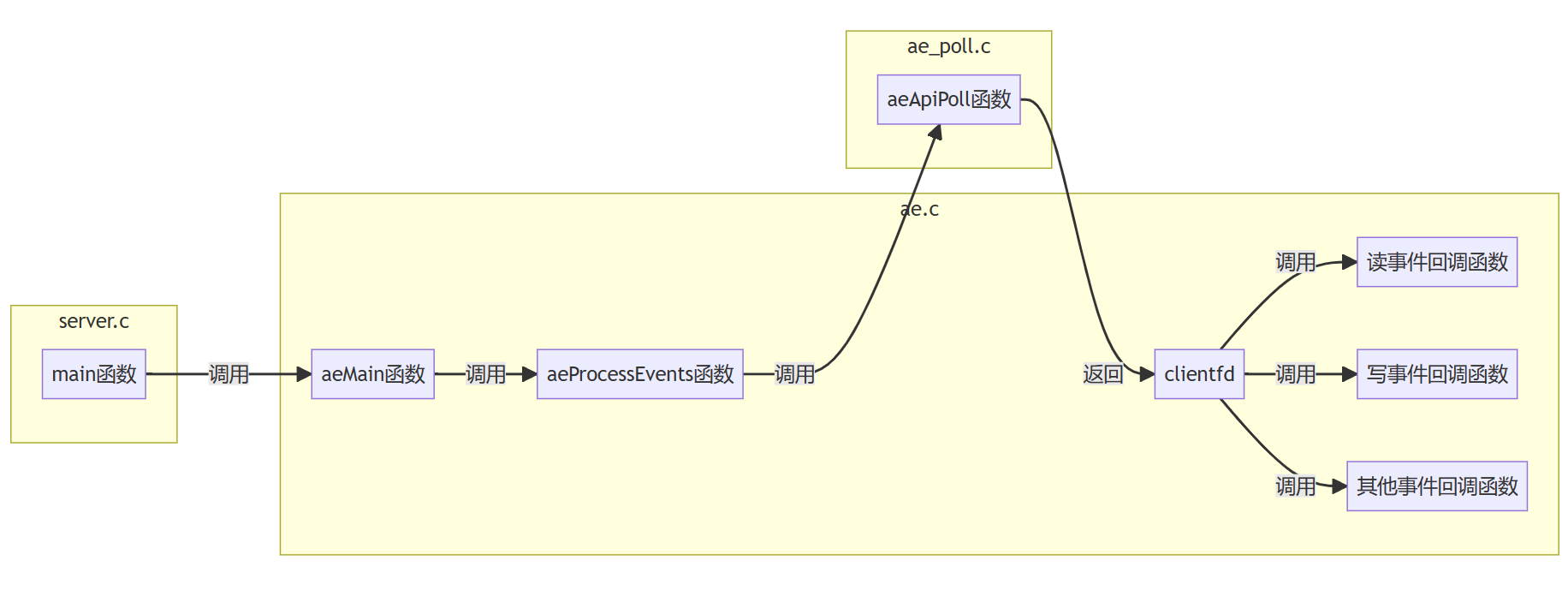
为clientfd注册读事件:
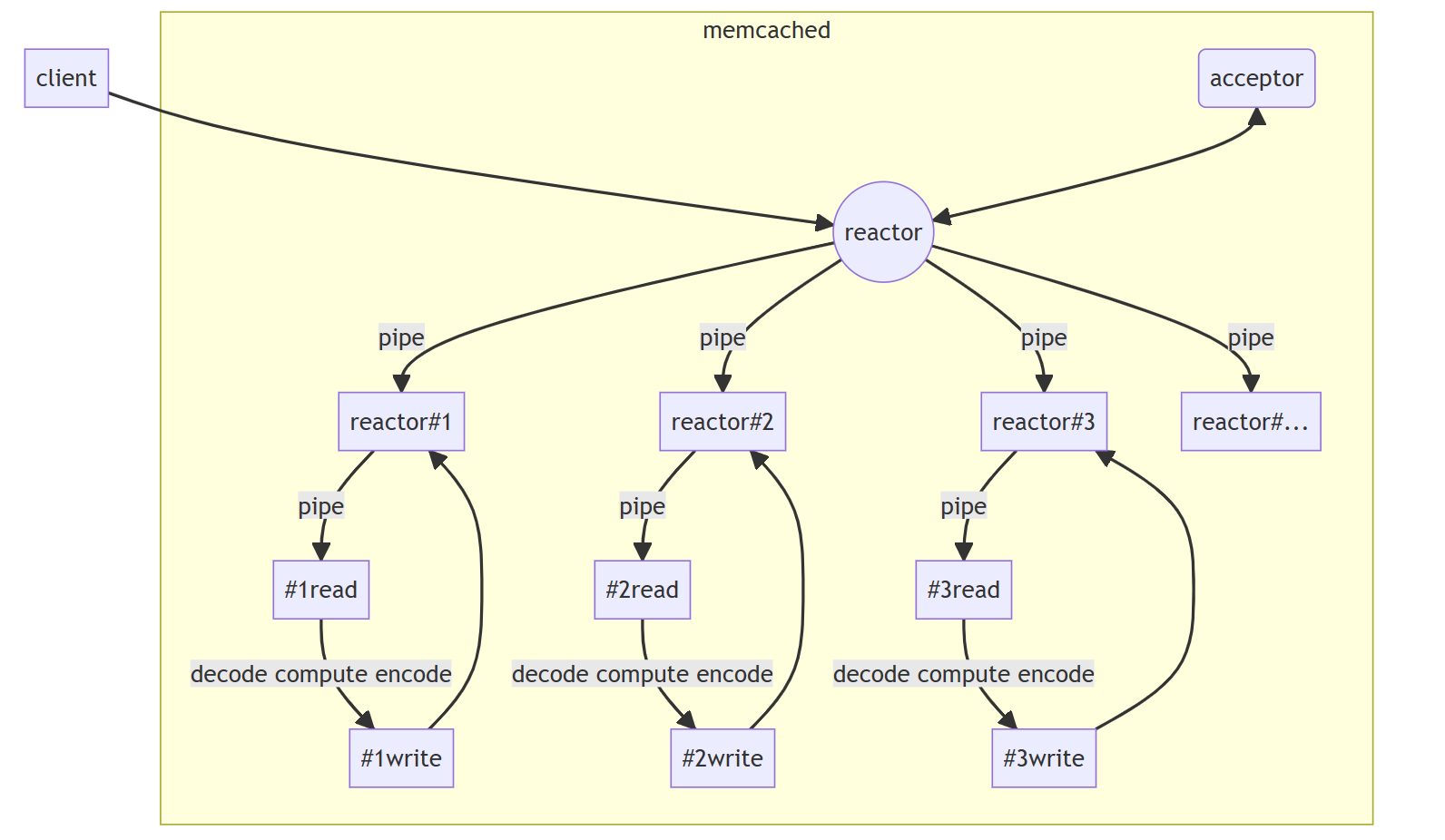
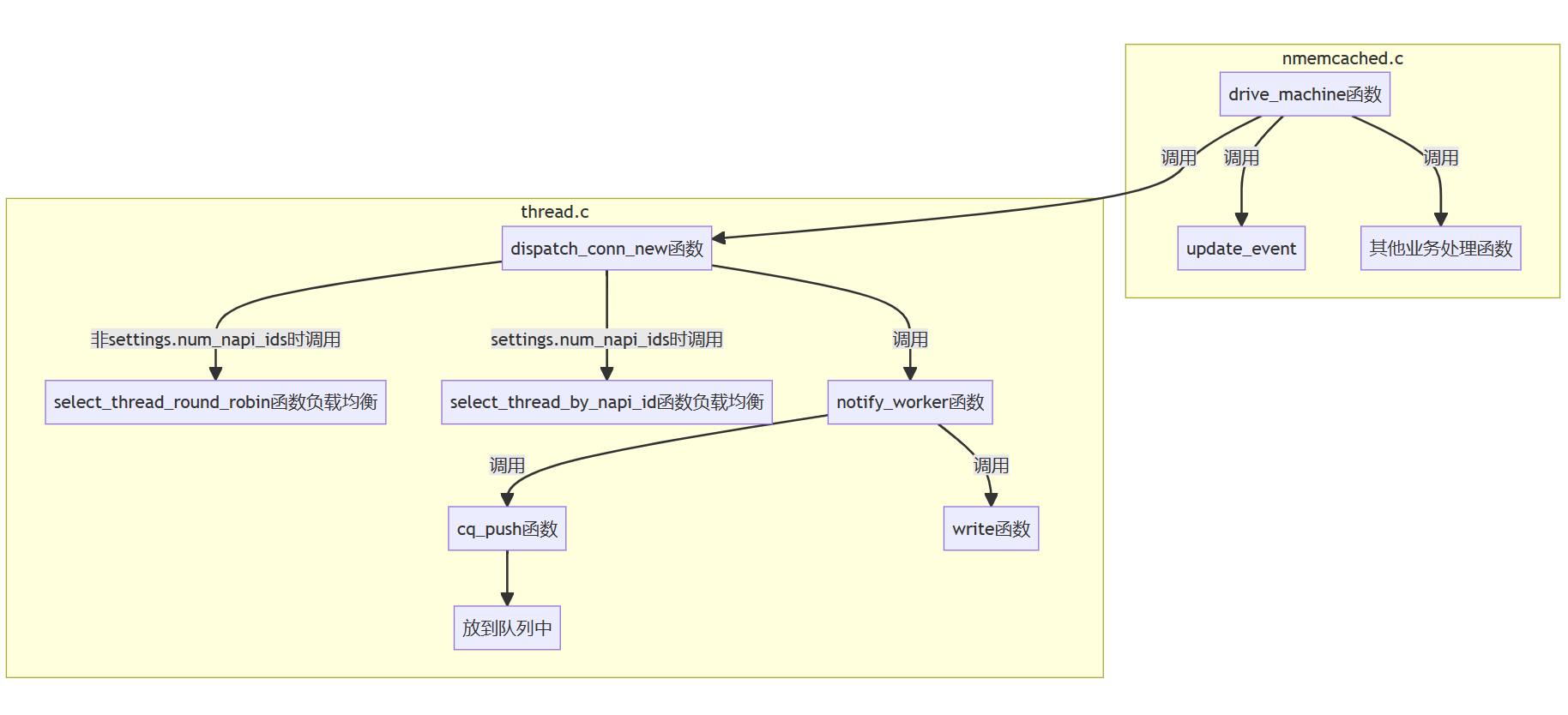
memcached是一种key-value结构、对内存进行操作的网络数据库组件。memcached的命令处理是多线程的。
memcached需要libevent,libevent就是一个事件驱动库,memcached对于网络上的使用都是基于libevent的。
memcached的key-value结构不像redis支持丰富的数据结构,它的value使用的数据结构相对简单,加锁也就相对容易。因此,可以引入多线程,提高效率。
memcached主线程会有一个reactor,主要负责接收连接;接收完连接后,经过负载均衡,通过pipe(管道)告诉子线程的reactor,将客户端的fd交由该线程的reactor管理;每个线程处理相对应的业务逻辑。
github上下载最新的memcached。
开始源码分析:
创建套接字,绑定监听:
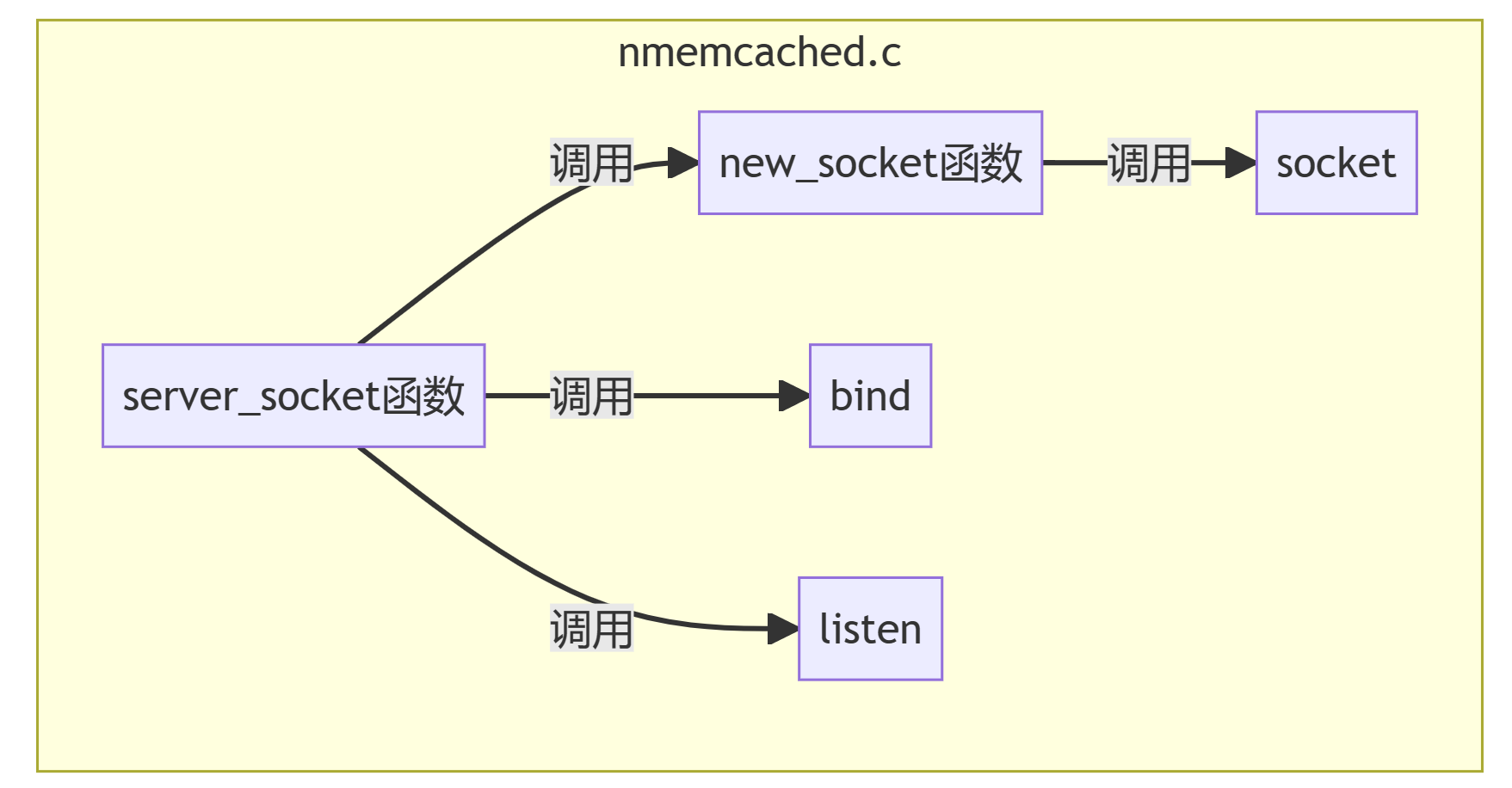
注册listenfd读事件:
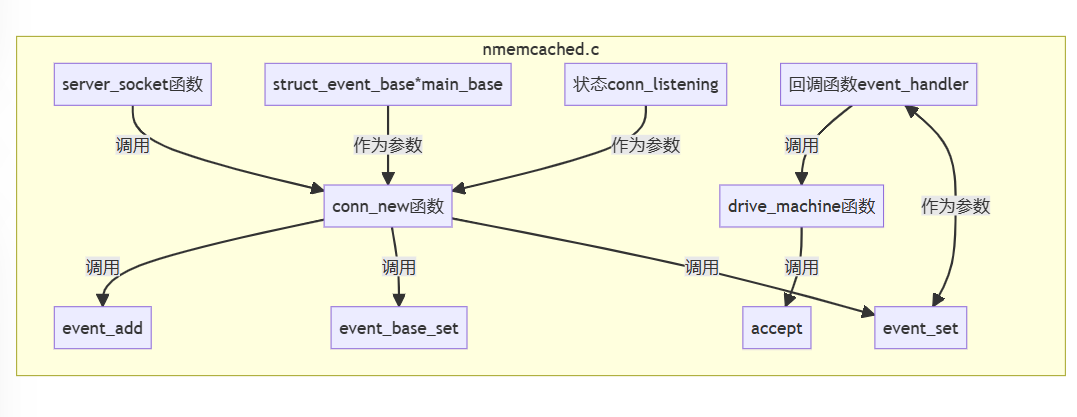
分配clientfd到具体的线程中,添加读事件:
nginx可以反向代理,利用多进程处理业务。
master会创建listenfd,并bind和listen;fork出多个进程,每个进程都有一个自己的epoll对象,listenfd交由多个epoll对象管理。这时会有惊群现象,需要处理;通过负载均衡处理事件。
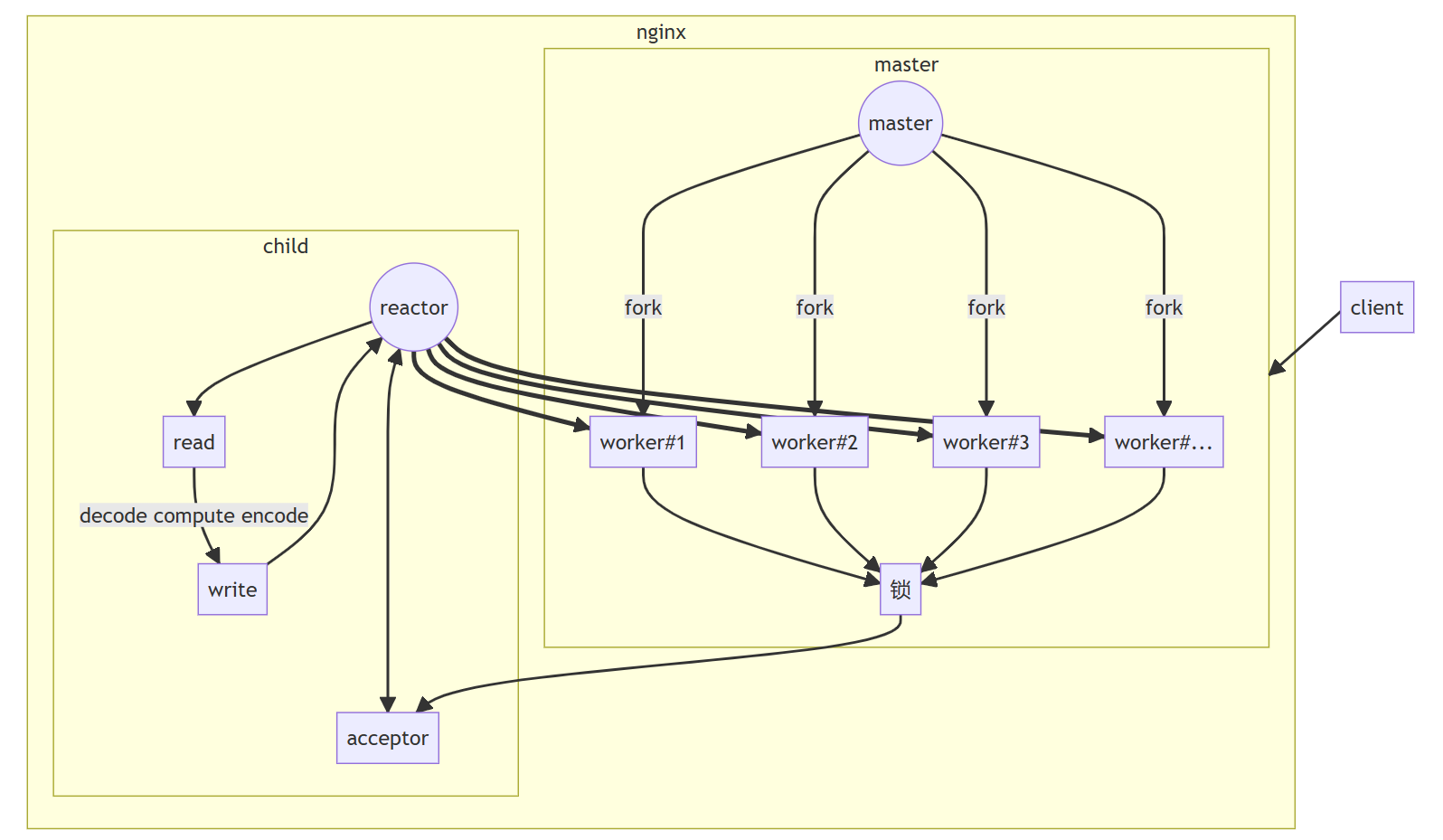
加锁方式。nginx会开辟一个共享内存,把锁放在共享内存当中,多个进程去争夺这把锁,争夺到锁的才能进行接受连接。
定义一个进程最大的连接数,当连接数量超过总连接数量的7/8时,该进程就会暂停接受连接,将机会留个其他进程。
这样不会让一个进程拥有过多的连接,而其他进程连接数量过少;从而使每个进程的连接数量相对平衡。
当所有的进程接受连接的数量都达到总连接数量的7/8时,这是nginx接受连接将变得很缓慢。
在本文中深入探讨了Linux Reactor网络模型,并着重介绍了其在实际应用中的重要性和优势。Reactors模型是一种高效的网络设计模式,它在处理并发连接时表现出色,使得我们能够构建高性能、可伸缩的网络应用程序。
首先,了解了Reactors模型的基本原理。它采用事件驱动的方式,通过一个主循环监听输入事件,一旦有事件发生,就会调用相应的处理程序。这种非阻塞的设计使得服务器能够高效地处理大量并发连接,而无需为每个连接创建一个线程。
接着,探讨了Reactors模型在Linux网络设计中的实际应用。还深入剖析了事件处理和回调机制,帮助读者理解如何优化网络应用的设计。
相比传统的多线程或多进程模型,Reactors模型能够更好地利用系统资源,减少上下文切换和线程创建的开销,从而提高应用的并发处理能力。
本文旨在帮助读者全面了解Linux Reactor网络模型,并鼓励他们在自己的网络应用中运用这一模型,以构建出更高性能、更可靠的网络应用。掌握Reactors模型的知识,将使读者能够更加自信地驾驭网络技术的未来,迎接不断变化的挑战。