本文分享自华为云社区《MRS大企业ERP流程实时数据湖加工最佳实践》,作者:晋红轻 。
本文将以ERP流程实践为例介绍MRS实时数据湖方案的演进
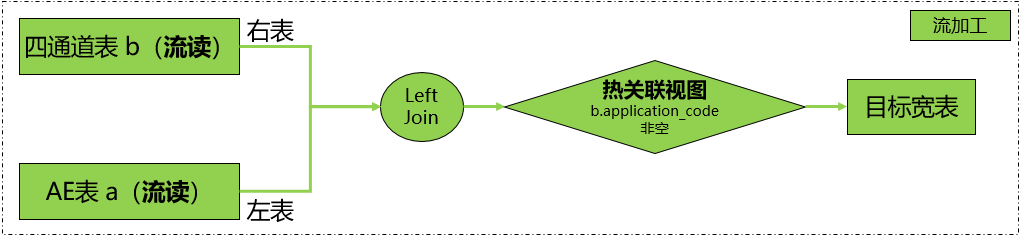
•Hudi表流读能够减少整体内存开销,提高作业稳定性。
•以其中一条流为基准(左表),去比较另一条流(右表)
•会出现关联缺失的情况,以驱动表(AE表)的视角(新增&更新)
•1)四通道流早到,并且ttl到期后数据丢失
•2)四通道流晚到,AE流ttl到期后数据丢失
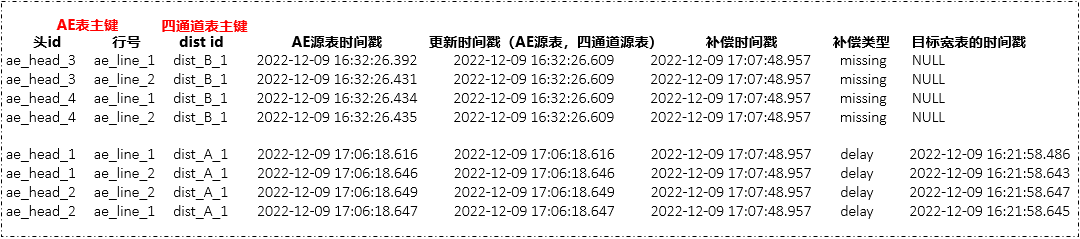
•目标宽表数据会出现不准的情况
•源端新增因为关联不出有效结果造成目标宽表缺数 -> missing
•源端更改因为关联不出有效结果造成目标宽表延时 -> delay
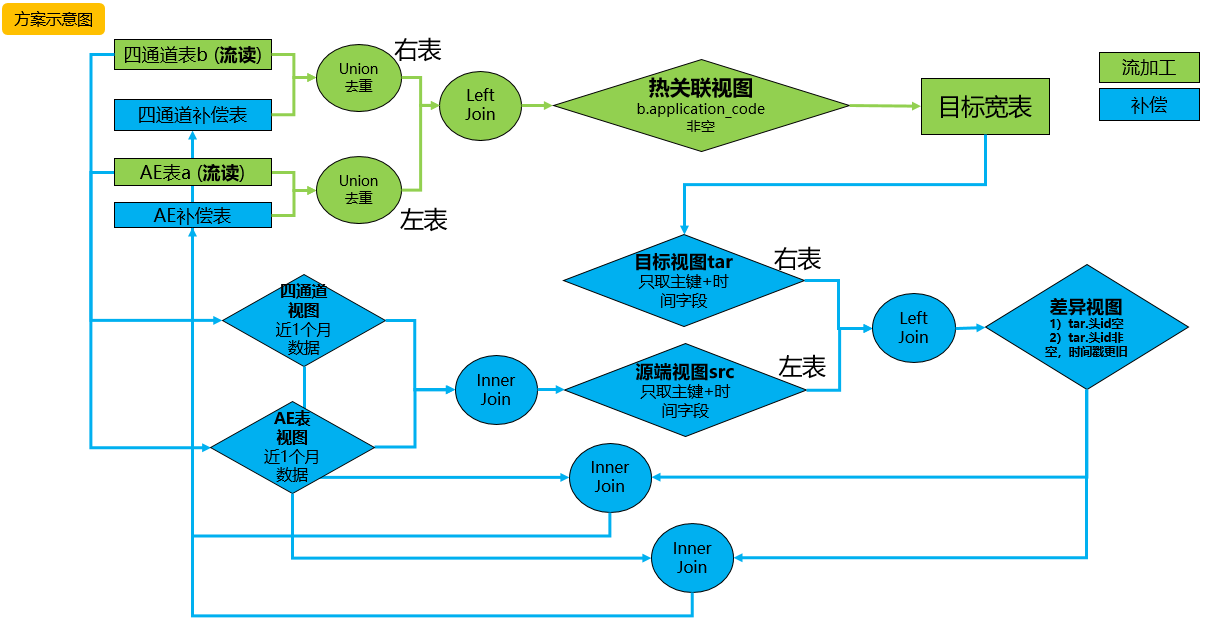
补偿目的:
补偿目的:基于业务逻辑,对比源端流表和目的端宽表数据内容,发现目标宽表缺失数据主要字段,关联源表完整内容找出缺失数据,并写回源端表补偿层。
missing&delay补偿模拟:
模型二特点:比较方案一增加补偿机制,能够对比源表(AE表,四通道表)以及目标宽表,找出缺失数据missing, delay。
模型二局限:实际情况双流之间时延可能较大、对齐较难,虽然能够使用补偿机制找回缺失数据,但是这样流加工任务主要角色会被弱化,同时会对补偿任务造成更大压力,数据时延会变大 。
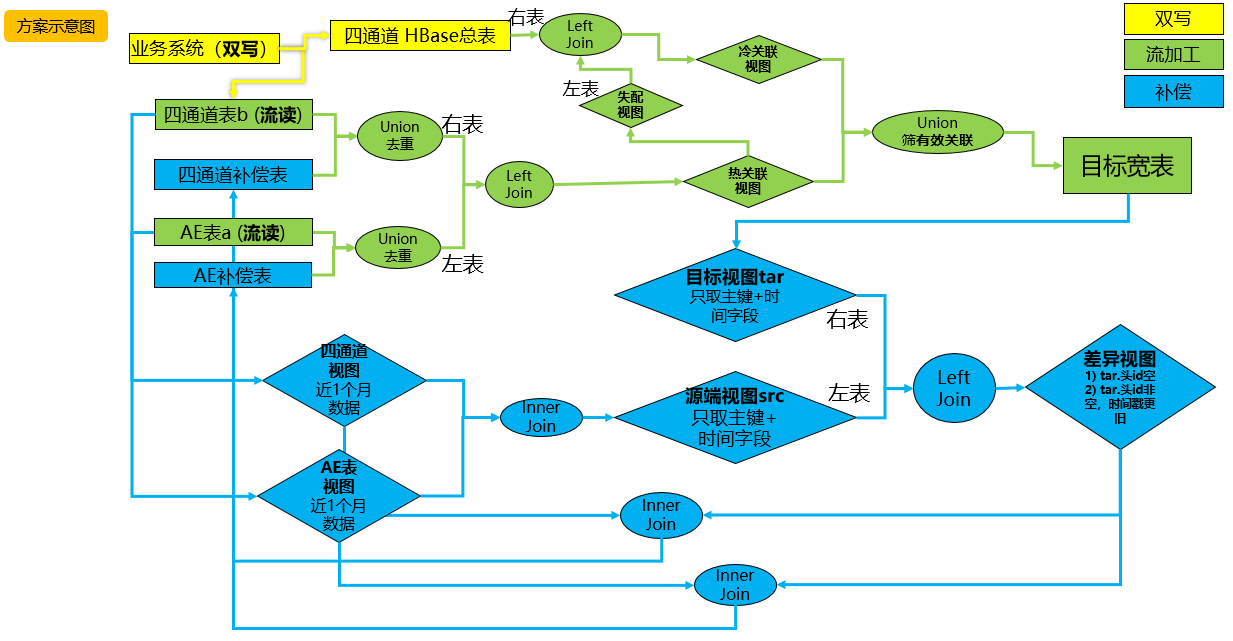
双写目的:业务系统持续向Hudi表,HBase表双写数据。Hudi表流读,提供主要热关联数据,HBase存储所有历史数据,技术上就是维度表,为热关联失败之后进行快速点查补数(lookup join)得到有效关联。提高双流关联的命中率。减少流加工整体数据时延。
维表选型:

模型总结:
