本文分享自华为云社区《GaussDB(DWS)性能调优:典型不下推语句整改案例》,作者: 譡里个檔 。
根因:递归语句的某个分支中没有FROM字句(只有 VALUES 或者类似 SELECT 1 这样的语句)
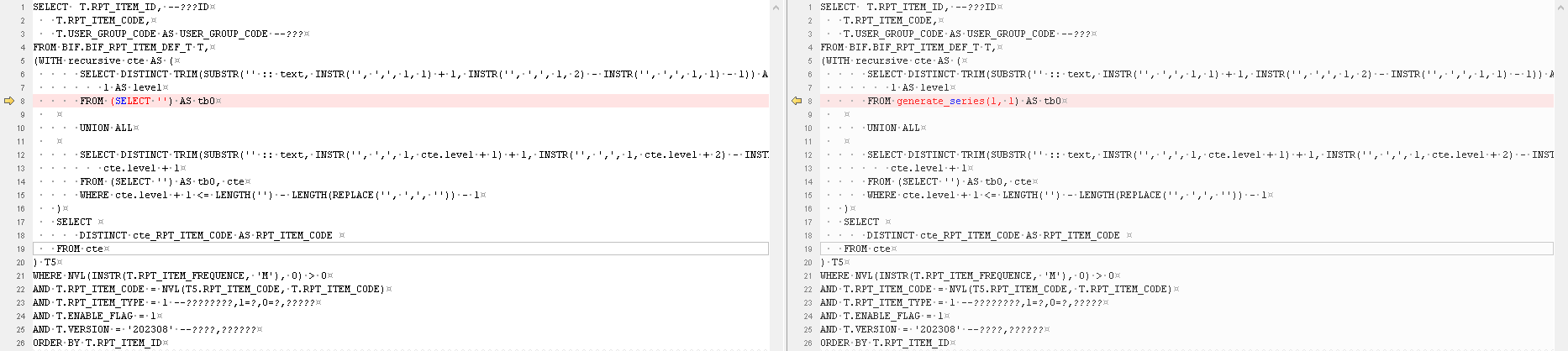
原始语句
SELECT T.RPT_ITEM_ID, --报表项ID T.RPT_ITEM_CODE, T.USER_GROUP_CODE AS USER_GROUP_CODE --用户组 FROM BIF.BIF_RPT_ITEM_DEF_T T, (WITH recursive cte AS ( SELECT DISTINCT TRIM(SUBSTR('' :: text, INSTR('', ',', 1, 1) + 1, INSTR('', ',', 1, 2) - INSTR('', ',', 1, 1) - 1)) AS cte_RPT_ITEM_CODE, 1 AS level FROM (SELECT '') AS tb0 UNION ALL SELECT DISTINCT TRIM(SUBSTR('' :: text, INSTR('', ',', 1, cte.level + 1) + 1, INSTR('', ',', 1, cte.level + 2) - INSTR('', ',', 1, cte.level + 1) - 1)), cte.level + 1 FROM (SELECT '') AS tb0, cte WHERE cte.level + 1 <= LENGTH('') - LENGTH(REPLACE('', ',', '')) - 1 ) SELECT DISTINCT cte_RPT_ITEM_CODE AS RPT_ITEM_CODE FROM cte ) T5 WHERE NVL(INSTR(T.RPT_ITEM_FREQUENCE, 'M'), 0) > 0 AND T.RPT_ITEM_CODE = NVL(T5.RPT_ITEM_CODE, T.RPT_ITEM_CODE) AND T.RPT_ITEM_TYPE = 1 --是否是叶子报表项,1=是,0=否,基本报表项 AND T.ENABLE_FLAG = 1 AND T.VERSION = '202308' --使用快照,增加条件限制 ORDER BY T.RPT_ITEM_ID复制
改写语句
SELECT T.RPT_ITEM_ID, --报表项ID T.RPT_ITEM_CODE, T.USER_GROUP_CODE AS USER_GROUP_CODE --用户组 FROM BIF.BIF_RPT_ITEM_DEF_T T, (WITH recursive cte AS ( SELECT DISTINCT TRIM(SUBSTR('' :: text, INSTR('', ',', 1, 1) + 1, INSTR('', ',', 1, 2) - INSTR('', ',', 1, 1) - 1)) AS cte_RPT_ITEM_CODE, 1 AS level FROM (SELECT '') AS tb0 UNION ALL SELECT DISTINCT TRIM(SUBSTR('' :: text, INSTR('', ',', 1, cte.level + 1) + 1, INSTR('', ',', 1, cte.level + 2) - INSTR('', ',', 1, cte.level + 1) - 1)), cte.level + 1 FROM (SELECT '') AS tb0, cte WHERE cte.level + 1 <= LENGTH('') - LENGTH(REPLACE('', ',', '')) - 1 ) SELECT DISTINCT cte_RPT_ITEM_CODE AS RPT_ITEM_CODE FROM cte ) T5 WHERE NVL(INSTR(T.RPT_ITEM_FREQUENCE, 'M'), 0) > 0 AND T.RPT_ITEM_CODE = NVL(T5.RPT_ITEM_CODE, T.RPT_ITEM_CODE) AND T.RPT_ITEM_TYPE = 1 --是否是叶子报表项,1=是,0=否,基本报表项 AND T.ENABLE_FLAG = 1 AND T.VERSION = '202308' --使用快照,增加条件限制 ORDER BY T.RPT_ITEM_ID复制
修改点比对
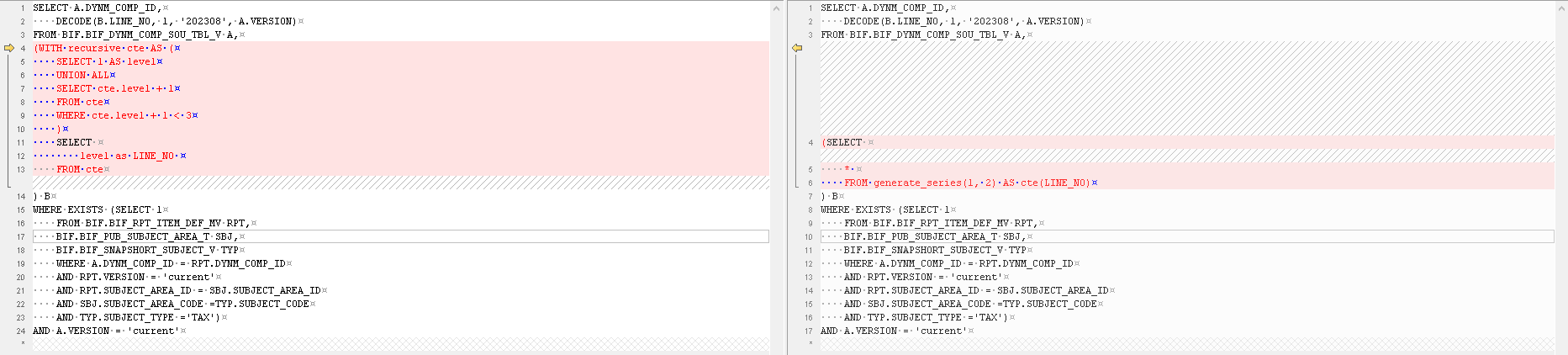
原始语句
SELECT A.DYNM_COMP_ID, DECODE(B.LINE_NO, 1, '202308', A.VERSION) FROM BIF.BIF_DYNM_COMP_SOU_TBL_V A, (WITH recursive cte AS ( SELECT 1 AS level UNION ALL SELECT cte.level + 1 FROM cte WHERE cte.level + 1 < 3 ) SELECT level as LINE_NO FROM cte ) B WHERE EXISTS (SELECT 1 FROM BIF.BIF_RPT_ITEM_DEF_MV RPT, BIF.BIF_PUB_SUBJECT_AREA_T SBJ, BIF.BIF_SNAPSHORT_SUBJECT_V TYP WHERE A.DYNM_COMP_ID = RPT.DYNM_COMP_ID AND RPT.VERSION = 'current' AND RPT.SUBJECT_AREA_ID = SBJ.SUBJECT_AREA_ID AND SBJ.SUBJECT_AREA_CODE =TYP.SUBJECT_CODE AND TYP.SUBJECT_TYPE ='TAX') AND A.VERSION = 'current'复制
改写语句
SELECT A.DYNM_COMP_ID, DECODE(B.LINE_NO, 1, '202308', A.VERSION) FROM BIF.BIF_DYNM_COMP_SOU_TBL_V A, (SELECT * FROM generate_series(1, 2) AS cte(LINE_NO) ) B WHERE EXISTS (SELECT 1 FROM BIF.BIF_RPT_ITEM_DEF_MV RPT, BIF.BIF_PUB_SUBJECT_AREA_T SBJ, BIF.BIF_SNAPSHORT_SUBJECT_V TYP WHERE A.DYNM_COMP_ID = RPT.DYNM_COMP_ID AND RPT.VERSION = 'current' AND RPT.SUBJECT_AREA_ID = SBJ.SUBJECT_AREA_ID AND SBJ.SUBJECT_AREA_CODE =TYP.SUBJECT_CODE AND TYP.SUBJECT_TYPE ='TAX') AND A.VERSION = 'current'复制
修改点比对
原始语句
WITH RECURSIVE t(n) AS ( VALUES (1) UNION ALL SELECT n+1 FROM t WHERE n < (SELECT MAX(LENGTH(COMP_CODE)-LENGTH(REPLACE(COMP_CODE,',','')))+1 MAX_TOKENS FROM (SELECT DEPT_CODE, to_char(APPLICABLE_GEO_PC_CODE) COMP_CODE FROM SDIHR.MDM_CDM_DEPT_ACT_INFO_T_3600) ) ) SELECT n AS LVL FROM t复制
改写语句
WITH RECURSIVE t(n) AS ( SELECT * FROM generate_series(1, 1) UNION ALL SELECT n+1 FROM t WHERE n < (SELECT MAX(LENGTH(COMP_CODE)-LENGTH(REPLACE(COMP_CODE,',','')))+1 MAX_TOKENS FROM (SELECT DEPT_CODE, to_char(APPLICABLE_GEO_PC_CODE) COMP_CODE FROM SDIHR.MDM_CDM_DEPT_ACT_INFO_T_3600) ) ) SELECT n AS LVL FROM t复制
修改点比对

原始语句
WITH RECURSIVE t(n) AS ( VALUES (1) UNION ALL SELECT n+1 FROM t WHERE n < (SELECT MAX(LENGTH(COMP_CODE)-LENGTH(REPLACE(COMP_CODE,',','')))+1 MAX_TOKENS FROM (SELECT DEPT_CODE, to_char(APPLICABLE_GEO_PC_CODE) COMP_CODE FROM SDIHR.MDM_CDM_DEPT_ACT_INFO_T_3600)) ) SELECT n AS LVL FROM t复制
改写语句
SELECT * FROM generate_series(1, (SELECT MAX(LENGTH(COMP_CODE)-LENGTH(REPLACE(COMP_CODE,',','')))+1 MAX_TOKENS FROM (SELECT DEPT_CODE, to_char(APPLICABLE_GEO_PC_CODE) COMP_CODE FROM SDIHR.MDM_CDM_DEPT_ACT_INFO_T_3600)) ) AS t(lvl)复制
修改点比对

根因:递归语句的某个分支中没有FROM字句中只用系统表或者系统视图(DUAL也被视为系统视图)
原始语句
WITH recursive cte AS ( SELECT TO_DATE(201701, 'YYYYMM') as level ,TO_DATE(20170131, 'YYYYMMDD') LASTDAY FROM dual UNION ALL SELECT ADD_MONTHS(cte.LEVEL, 1) AS PERIOD, LAST_DAY(ADD_MONTHS(cte.LEVEL, 1)) AS LASTDAY FROM cte WHERE cte.LEVEL <=SYSDATE ) SELECT TO_CHAR(cte.level,'YYYYMMDD') AS PERIOD , cte.LASTDAY FROM cte WHERE TO_CHAR(cte.level,'YYYYMMDD')<= TO_CHAR(SYSDATE,'YYYYMMDD')复制
改写语句
WITH recursive cte AS ( SELECT TO_DATE(201701, 'YYYYMM') as level ,TO_DATE(20170131, 'YYYYMMDD') LASTDAY FROM dual UNION ALL SELECT ADD_MONTHS(cte.LEVEL, 1) AS PERIOD, LAST_DAY(ADD_MONTHS(cte.LEVEL, 1)) AS LASTDAY FROM cte WHERE cte.LEVEL <=SYSDATE ) SELECT TO_CHAR(cte.level,'YYYYMMDD') AS PERIOD , cte.LASTDAY FROM cte WHERE TO_CHAR(cte.level,'YYYYMMDD')<= TO_CHAR(SYSDATE,'YYYYMMDD')复制
修改点对比

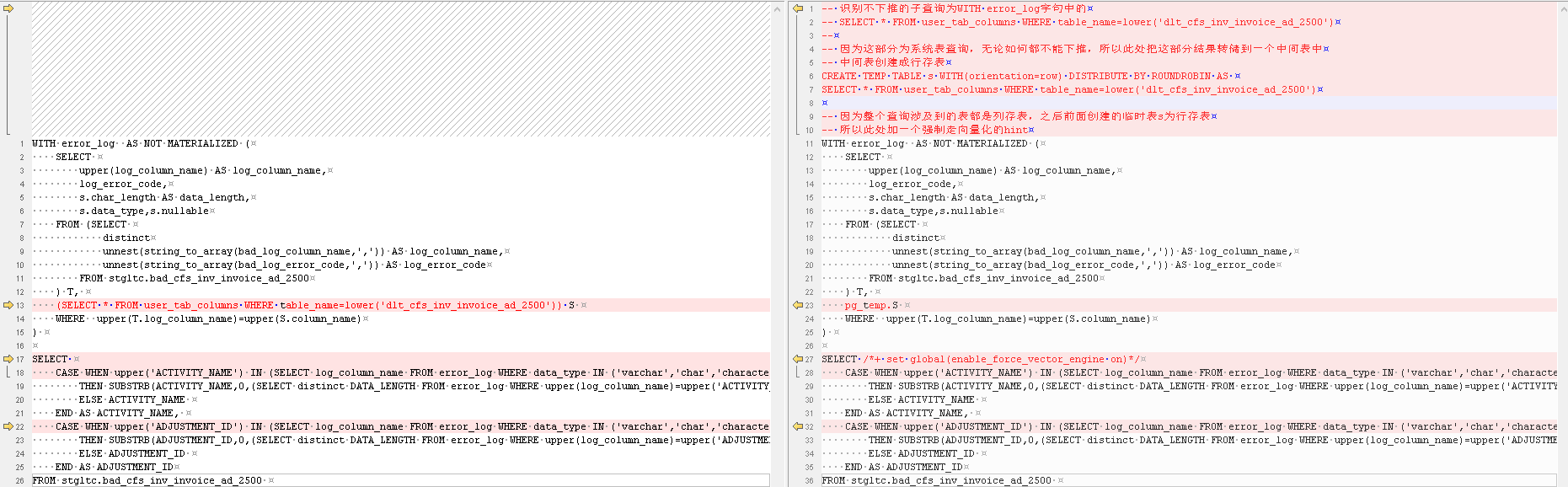
根因:某个子查询语句只能在CN上执行,通常是这个子查询有不下推因素,比如有系统表、系统视图调用,或者存在不下推函数等
原始语句
WITH error_log AS NOT MATERIALIZED ( SELECT upper(log_column_name) AS log_column_name, log_error_code, s.char_length AS data_length, s.data_type,s.nullable FROM (SELECT distinct unnest(string_to_array(bad_log_column_name,',')) AS log_column_name, unnest(string_to_array(bad_log_error_code,',')) AS log_error_code FROM stgltc.BAD_cfs_inv_invoice_ad_2500 ) T, (SELECT * FROM user_tab_columns WHERE table_name=lower('dlt_cfs_inv_invoice_ad_2500')) S WHERE upper(T.log_column_name)=upper(S.column_name) ) SELECT CASE WHEN upper('ACTIVITY_NAME') IN (SELECT log_column_name FROM error_log WHERE data_type IN ('varchar','char','character','nchar','character varying','varchar2','nvarchar2','clob','text') AND log_error_code='22001'/*字符超长*/) THEN SUBSTRB(ACTIVITY_NAME,0,(SELECT distinct DATA_LENGTH FROM error_log WHERE upper(log_column_name)=upper('ACTIVITY_NAME'))) ELSE ACTIVITY_NAME END AS ACTIVITY_NAME, CASE WHEN upper('ADJUSTMENT_ID') IN (SELECT log_column_name FROM error_log WHERE data_type IN ('varchar','char','character','nchar','character varying','varchar2','nvarchar2','clob','text') AND log_error_code='22001'/*字符超长*/) THEN SUBSTRB(ADJUSTMENT_ID,0,(SELECT distinct DATA_LENGTH FROM error_log WHERE upper(log_column_name)=upper('ADJUSTMENT_ID'))) ELSE ADJUSTMENT_ID END AS ADJUSTMENT_ID FROM stgltc.BAD_cfs_inv_invoice_ad_2500复制
改写语句
-- 识别不下推的子查询为WITH error_log字句中的 -- SELECT * FROM user_tab_columns WHERE table_name=lower('dlt_cfs_inv_invoice_ad_2500') -- -- 因为这部分为系统表查询,无论如何都不能下推,所以此处把这部分结果转储到一个中间表中 -- 中间表创建成行存表 CREATE TEMP TABLE s WITH(orientation=row) DISTRIBUTE BY ROUNDROBIN AS SELECT * FROM user_tab_columns WHERE table_name=lower('dlt_cfs_inv_invoice_ad_2500') -- 因为整个查询涉及到的表都是列存表,之后前面创建的临时表s为行存表 -- 所以此处加一个强制走向量化的hint WITH error_log AS NOT MATERIALIZED ( SELECT upper(log_column_name) AS log_column_name, log_error_code, s.char_length AS data_length, s.data_type,s.nullable FROM (SELECT distinct unnest(string_to_array(bad_log_column_name,',')) AS log_column_name, unnest(string_to_array(bad_log_error_code,',')) AS log_error_code FROM stgltc.bad_cfs_inv_invoice_ad_2500 ) T, pg_temp.S WHERE upper(T.log_column_name)=upper(S.column_name) ) SELECT /*+ set global(enable_force_vector_engine on)*/ CASE WHEN upper('ACTIVITY_NAME') IN (SELECT log_column_name FROM error_log WHERE data_type IN ('varchar','char','character','nchar','character varying','varchar2','nvarchar2','clob','text') AND log_error_code='22001'/*字符超长*/) THEN SUBSTRB(ACTIVITY_NAME,0,(SELECT distinct DATA_LENGTH FROM error_log WHERE upper(log_column_name)=upper('ACTIVITY_NAME'))) ELSE ACTIVITY_NAME END AS ACTIVITY_NAME, CASE WHEN upper('ADJUSTMENT_ID') IN (SELECT log_column_name FROM error_log WHERE data_type IN ('varchar','char','character','nchar','character varying','varchar2','nvarchar2','clob','text') AND log_error_code='22001'/*字符超长*/) THEN SUBSTRB(ADJUSTMENT_ID,0,(SELECT distinct DATA_LENGTH FROM error_log WHERE upper(log_column_name)=upper('ADJUSTMENT_ID'))) ELSE ADJUSTMENT_ID END AS ADJUSTMENT_ID FROM stgltc.bad_cfs_inv_invoice_ad_2500复制
修改点对比
根因:输出列中存在record类型,这种类型的不下推一般是不会体现在最外层的输出列上,一般这类报错有两个场景
1.SQL书写逻辑错误,导致输出列上出现了(...)形式的输出列
2.SQL业务逻辑正确, 这种场景需要了解业务含义,把record字段强转为text类型,然后再使用record字段的地方做特殊适配
原始语句
SELECT d.id, coalesce(d.period, 'snull') AS period, (d.plan_unit_code, 'snull') AS plan_unit_code, coalesce(d.product_type_model, 'snull') AS product_type_model, coalesce(d.revision, 'snull') AS revision, d.start_date FROM (SELECT * FROM cdcscm.cdc_mp_d_forecast_t_6120 t WHERE t.cdc_timestamp > to_date('2023-07-06 00:00:00', 'yyyy-mm-dd hh24:mi:ss') - 7 AND t.cdc_timestamp < to_date('2023-08-08 00:00:00', 'yyyy-mm-dd hh24:mi:ss') ) t1, sdiscm.mp_d_forecast_t_6120 d WHERE (t1.audit_op_type = 'delete' AND t1.audit_op_option = 'before') AND d.id = t1.id复制
改写语句
SELECT d.id, coalesce(d.period, 'snull') AS period, coalesce(d.plan_unit_code, 'snull') AS plan_unit_code, coalesce(d.product_type_model, 'snull') AS product_type_model, coalesce(d.revision, 'snull') AS revision, d.start_date FROM (SELECT * FROM cdcscm.cdc_mp_d_forecast_t_6120 t WHERE t.cdc_timestamp > to_date('2023-07-06 00:00:00', 'yyyy-mm-dd hh24:mi:ss') - 7 AND t.cdc_timestamp < to_date('2023-08-08 00:00:00', 'yyyy-mm-dd hh24:mi:ss') ) t1, sdiscm.mp_d_forecast_t_6120 d WHERE (t1.audit_op_type = 'delete' AND t1.audit_op_option = 'before') AND d.id = t1.id复制
修改点对比

备注:改写前后语句不等价,不等价的原因是因为原始SQL书写有问题,正确的写法是就是coalesce(d.plan_unit_code, 'snull') AS plan_unit_code。