本文分享自华为云社区《GaussDB(DWS) 备份问题定位思路》,作者: yd_216390446。
在数据库系统中,故障分为事务内部故障、系统故障、介质(磁盘)故障。对于事务内部故障和系统故障,使用日志自动恢复,不需要人工参与。但对于介质故障,需事先备份数据。
那么对于DWS来说是如何进行备份的呢?以及备份的过程中容易出现哪些问题,又怎样去排查、解决呢?
本文主要讲述了DWS备份工具roach的备份的原理,以及常见的问题处理套路和相关案例。
本文主要说的备份均为物理备份,即通过物理文件拷贝的方式对数据库进行备份,通过备份的数据文件和日志等文件,数据库可以进行完全恢复。
全量备份大致分几个阶段:备份行存、创建barrier点、备份xlog、备份列存。
整体流程如下图所示
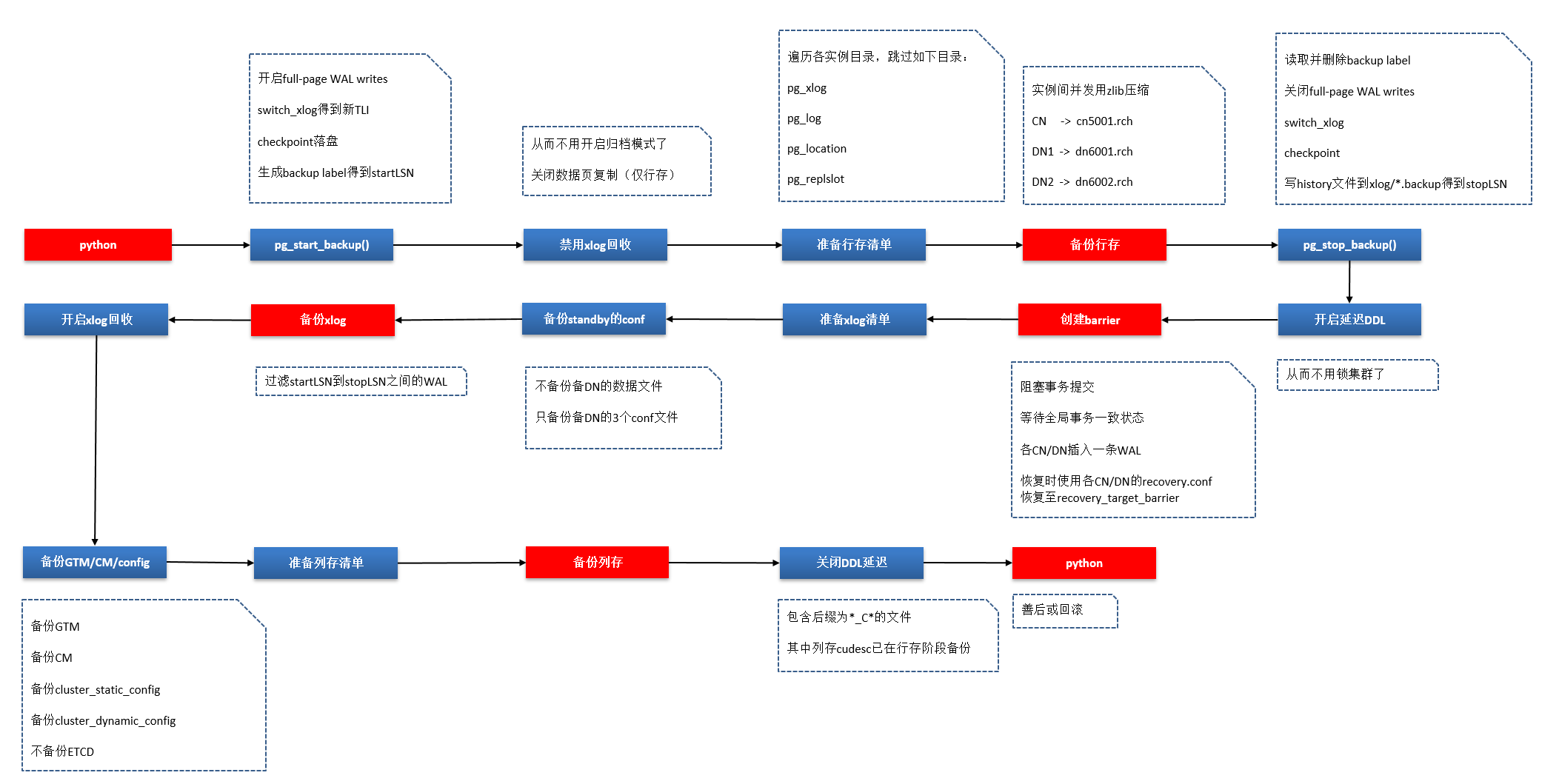
容易出现的问题:
注意的点:
为什么要有延时DDL?
DDL操作:alter/truncate/autovacuum/drop/vacuum full/insert overwrite 这些会改变relfilenode的语句,DDL操作在拿到行列存清单后,如果用户进行drop操作,为了保证文件存在,所以要开启延迟DDL
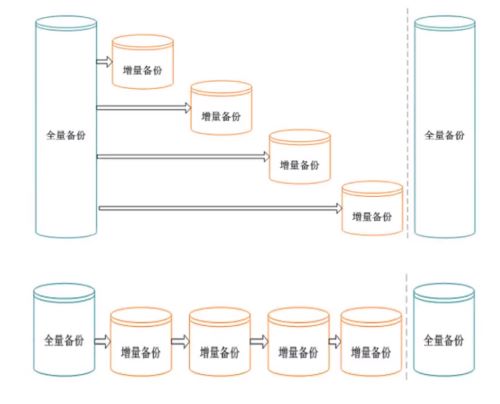
增量备份是基于某次备份进行的,在增量备份的命令中需要增加参数–prior-backup-key来表明是基于哪一次的备份。采用cbm文件识别增量页面。增量备份分为累计增量和差分增量两种
增量备份的原理:
cbm文件是什么?
changed block map,对外提供数据页面的修改情况,并提供外部接口,根据cbm信息可以直接获取两次备份之间发生对于数据文件(行存、列存)的增量修改信息,并备份

备份对于系统的影响:
DWS管控面/FI管控面-> GaussRoach.py/SyncDataToStby.py -> gs_roach内核
管控面调用roach的python脚本,python脚本进行解析参数,并调用内核侧的gs_roach命令。

查看主节点ip: grep “Master Ip” roach_agent*.log
查看备份进度:grep “Setting agent state to” roach_agent*.log
查看备份时间:grep “Time taken” roach_agent*.log | grep “MASTER”
查看备份是否成功:grep “Backup operation SUCCESSFUL. Backup key” roach_agent*.log
查看roach_client ip:grep “Success to connected Remote Media” roach_agent*.log
查看线程分配情况:grep “allotInstanceForMyProc” roach_agent*.log
查看备份命令参数:grep “command_dict” roach_controller*.log
如果文件被打包,使用“zgrep命令查看即可”
|
关键字 |
说明 |
|---|---|
|
Creating Thread Roach Agent |
开始创建agent进程 |
|
RAGENT_EXEC_PREPARING_METADATA com |
开始准备metadata清单 |
|
enter the callback of rowstore copy |
开始备份行存 |
|
performBackup enter |
真正开始执行落盘到rch |
|
start delay ddl recycle before col file copy |
开启延迟DDL |
|
Setting agent state to [AGENT_CREATING_BARRIER] |
开始创建barrier |
|
RAGENT_EXEC_BACKUP_XLOGFILES come |
agent开始备份xlog |
|
enter the callback of colstore copy |
开始备份列存 |
|
stop delay ddl recycle after having copied all col files |
关闭延迟DDL |
|
Setting Master state to [PERFORM_BOOKKEEPING_INFO] |
备份结束,master节点开始汇总结果 |
【问题描述】备份时agent报错Failed to connect to gauss(host:local , port: 25308) via libpq, ERROR: connection pointer is NULL
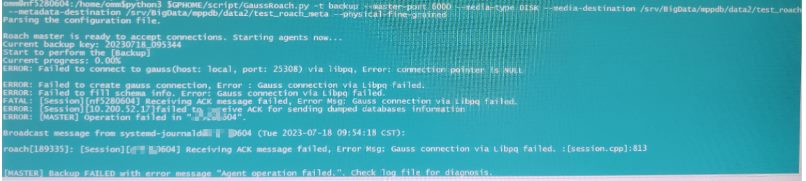

【排查方案】
【问题原因】数据库存在残留文件
【规避方法】删除该数据库下的残留文件
【问题描述】NBU 问题导致备份随机失败
【排查方案】
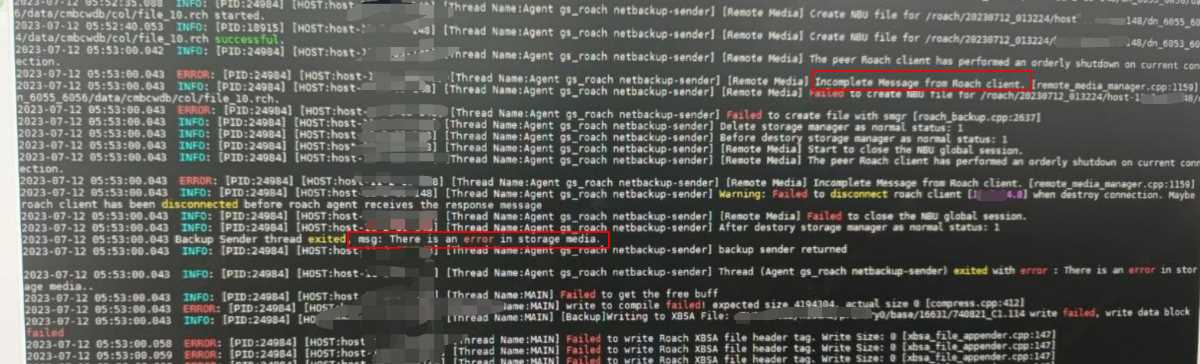

【问题原因】一般情况下,上述情况是由于roach侧并发太大,导致NBU负载大,备份报错,但具体细节还得协调NBU同时排查
【规避措施】如果是并发问题,建议调大filesplit-size参数并减小parallel-process参数,重新拉起备份
什么情况下协同NBU同事排查?
一般roach_client日志出现xbsa 、或者create file等关键字时
【问题描述】master和agent连接失败导致备份失败
【涉及版本】
【排查方案】日志报错Master和agent连接失败,Agents did not connect in 600 seconds.
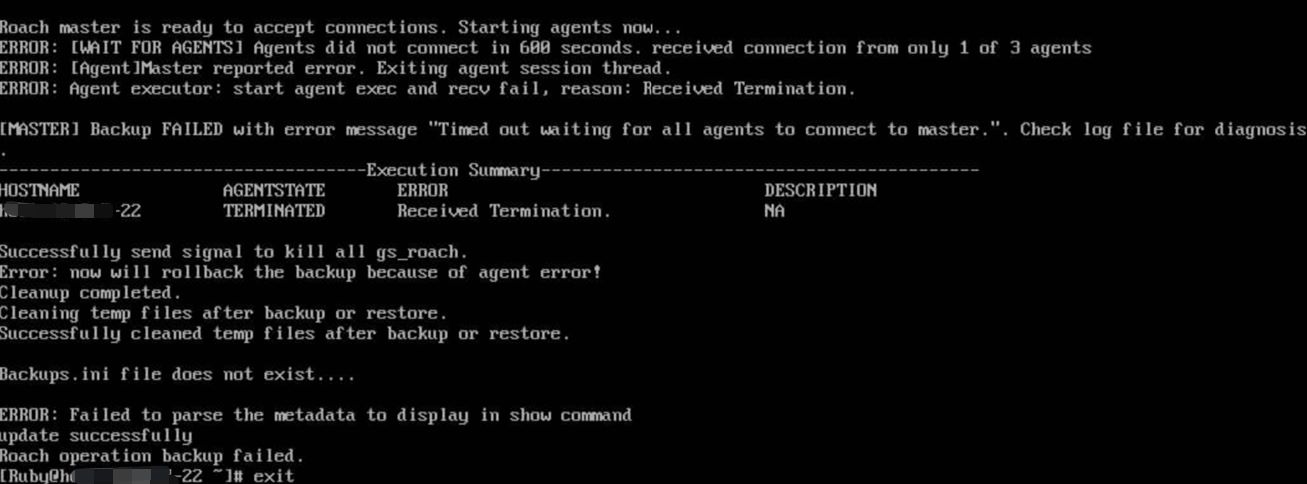
【问题原因】
HCS环境下只开放了55000和56000端口,端口未开放导致报错
【问题规避】
方案1:修改roach命令端口
方案2:开放对应端口
【问题描述】细粒度备份时报错Error:Getting file info failed.
【涉及版本】
【排查方案】查看报错节点agent日志,出现Backup main fork of relation xxx failed, Error: Getting file info failed.

【问题原因】细粒度备份期间不支持DDL操作。细粒度备份前会生成所有表的MAP文件,记录涉及的表名、以及表的相关表等信息,所有涉及到修改relfilenode的DDL操作的语句都会导致备份失败,例如alter/truncate/autovacuum/drop/vacuum full/insert overwrite等
【问题规避】
方案1:备份和涉及到DDL的业务时间错开
方案2:适当减少每次备份涉及的表,可以降低由于DDL引起的备份失败率
【问题描述】备份dump元数据阶段报错 memory is tempararily unavailable.
【排查方案】
controller报错 memory is tempararily unavailable.
【问题原因】参数cpu-cores过大,导致内存慢
【问题规避】调小cpu-cores参数
【问题描述】备份发起时,管控面显示集群状态异常,大集群下gs_roach启动时会频繁访问cms读取集群状态,导致cm_ctl查询集群状态不稳定
【涉及版本】821以下版本(不包括821版本)
【排查方案】

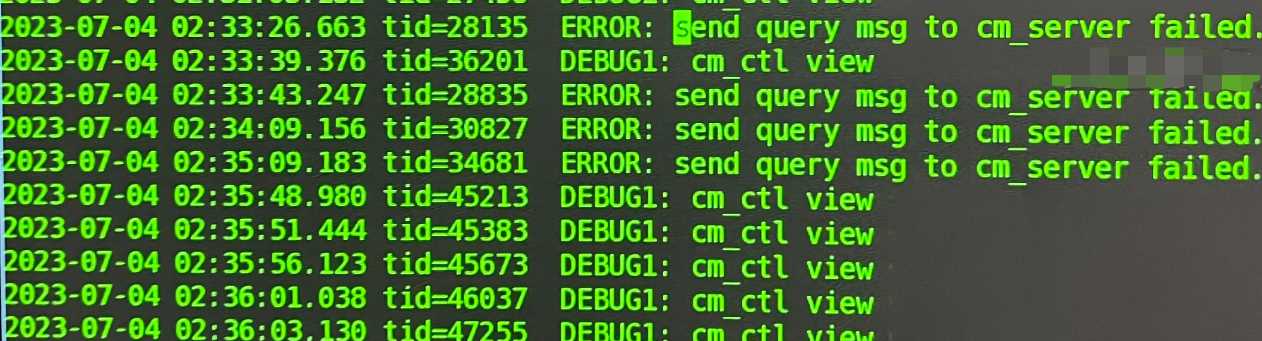
【问题原因】
在roach启动期间,频繁调用cm_ctl命令,而集群节点数多,并发数高,会导致页面集群状态监测的脚本执行cm_ctl失败
【问题规避】
升级到821版本

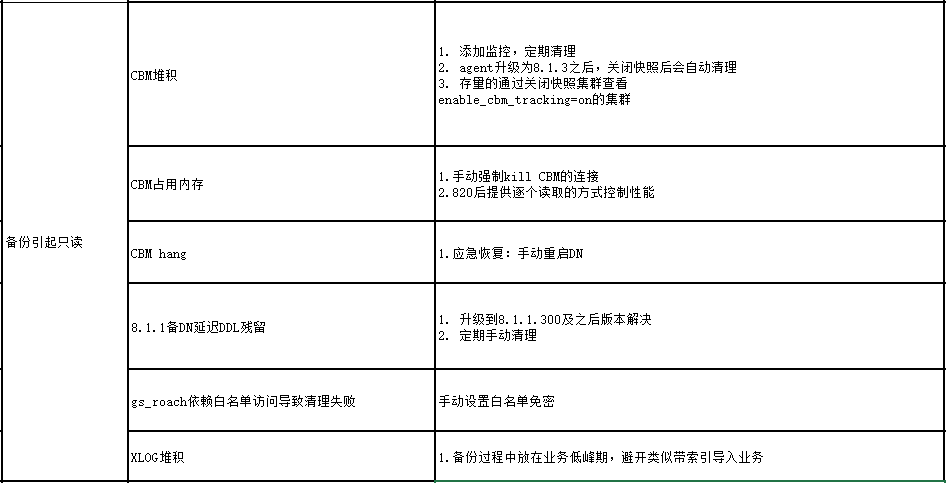
相关文档:
华为云数仓GaussDB(DWS)备份恢复的实现:https://bbs.huaweicloud.com/blogs/185928
数仓GaussDB(DWS)全量备份总结:https://bbs.huaweicloud.com/blogs/242694