本文分享自华为云社区《【手把手带你玩转HetuEngine】(三)HetuEngine资源规划》,作者: HetuEngine九级代言 。
HetuEngine支持在服务层角色实例和计算实例两个维度进行资源规划,并且支持在高并发场景下通过启动多个计算实例进行负载分担和均衡,从而满足各种业务场景下的资源规划需求。
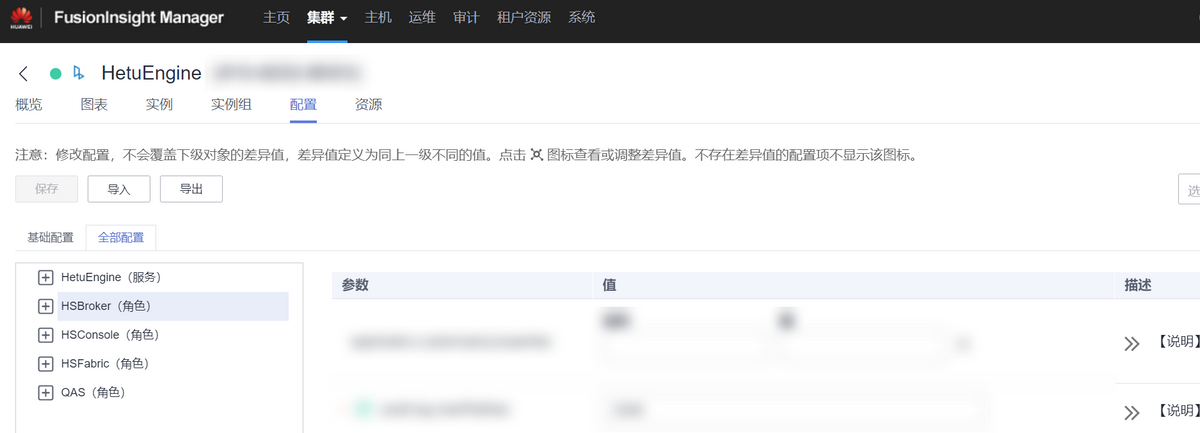
HetuEngine能够通过服务层对计算实例进行服务化管理,服务层的角色实例包括HSBroker、HSConsole、HSFabric、QAS。
可以通过HetuEngine服务层配置对实例参数进行调整,如下图所示。
HetuEngine的计算实例是一个运行在Yarn容器内的基于内存的计算引擎,它一般包含1~2个Coordinator和N个worker,其中Coordinator是管理节点,提供SQL接收、SQL解析、生成执行计划、执行计划优化、分派任务和资源调度等能力,如果需要计算实例支持高可用,必须部署两个Coordinator。Worker是工作节点,提供数据源数据并行拉取,分布式SQL计算等能力。从8.2.1版本开始,HetuEngine支持单租户多计算实例的形态。
Yarn的租户队列、HetuEngine计算实例、计算实例的Coordinator 和 Worker 之间的关系如下图所示:
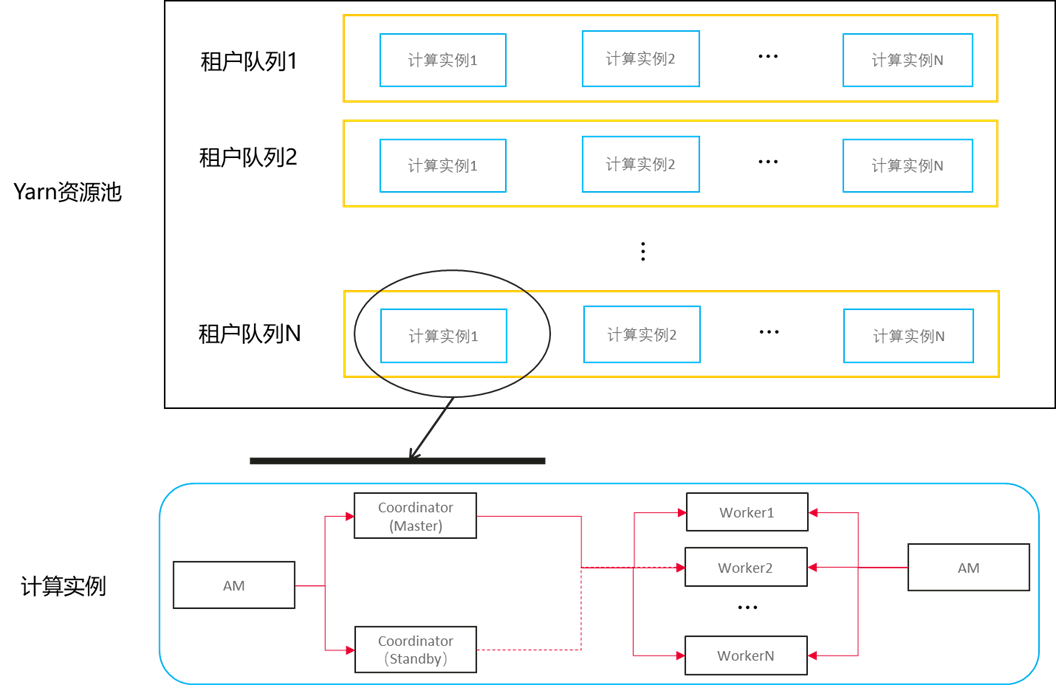
Yarn资源池分配示意图(AM为Yarn的应用管理器)
HetuEngine支持在HSConsole界面对计算实例进行管理,并且能够对每个计算实例进行差异化配置,如下图所示

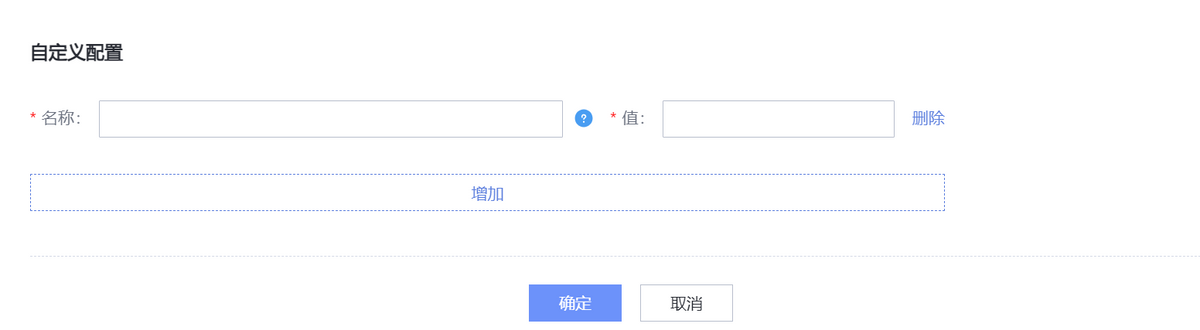
并且支持在创建计算实例的时候添加计算实例级别的自定义参数配置:

HetuEngine的计算实例作为SQL查询引擎,是一个纯内存的计算引擎。因此,从性能的角度考虑,需要给计算实例尽可能多的内存资源。
由于HetuEngine的计算实例是onYarn模式,Coordinator和Worker都是运行在Yarn的NodeManager节点上的。
Coordinator建议部署的节点为2个,Worker按实际资源情况部署。
• Coordaintor和Worker的内存值配置要求为:
1. 要求yarn.scheduler.maximum-allocation-mb > coordaintor/worker容器内存 > JVM内存。
2. 建议yarn.scheduler.maximum-allocation-mb内存为节点物理内存的90%,coordaintor/worker容器内存比yarn.scheduler.maximum-allocation-mb,JVM内存 为coordaintor/worker容器内存比大小的80%。
3. 建议一个节点启动一个conatiner的形式部署,避免产生内存碎片从未造成资源浪费。
4. coordaintor和worker+AM所用到的内存资源不能超出该租户的可使用最大内存资源。
• Coordaintor和Worker的CPU值配置要求为:
1. yarn.scheduler.maximum-allocation-vcores 大于coordaintor和worker的vcore。
2. 建议coordaintor和worker的vcore的值比yarn.scheduler.maximum-allocation-vcores的值少2~10个。
3. coordaintor和worker+AM所用到的core资源不能超出该租户的可使用最大core资源。
根据业务数据量大致估算计算实例worker的大小和数量
Yarn参数调整
调整yarn上container最大核数和最大内存相关参数以满足计算实例估算规模大小要求,在yarn服务级别进行修改
计算实例内存调整
HetuEngine的配置(建议CN和Worker配置保持一致):具体修改点如下图所示,在HSConsole页面,选择计算实例,点击"配置",即可在弹出窗口按下图修改:
单HetuEngine计算实例的并发建议低于50,高并发场景下建议启动多个计算实例进行负载分担避免性能明显下降。HetuEngine支持两种方式启动多计算实例,一是单租户单实例的模式,二是单租户多实例的模式。
方式1: 单租户单实例的部署模式。
可将资源分成多个资源池,每个租户独占一个资源池,每个租户启动一个计算实例的方式进行部署。例如将资源分成default、online、offline 3个资源池,分别给default、online、offline三个租户使用,每个租户启动一个计算实例,不同的业务将提交到不同的资源队列:
方式2:单租户多实例的部署模式。
320版本后,HetuEngine支持通过配置在单个租户内启动多个计算实例,如下图所示,不同的业务都提交到同一租户中的队列,HetuEngine能够自动实现单租户内的各个计算实例均衡负载。
HetuEngine能够支持跨源(多种数据源,如Hive,HBase,GaussDB(DWS),Elasticsearch,ClickHouse等),跨域(多个地域或数据中心)的快速联合查询,尤其适用于Hadoop集群(FusionInsight MRS)的Hive、Hudi数据的交互式快速查询场景。本章将对HetuEngine的数据源对接能力与操作实践进行介绍。
当前HetuEngine数据源对接支持以下几种能力:
1.支持对接Hive、HBase、GaussDB(DWS),Elasticsearch,ClickHouse、Hudi、IoTDB等多种数据源,并支持对接跨域HetuEngine
2.支持多种数据源的快速联合查询并提供可视化的数据源配置、管理页面,用户可通过HSConsole界面快速添加数据源,并进行差异化配置
3.数据源动态生效,无需重启计算实例
4.支持数据源下推
当前版本HetuEngine支持对接的数据源如表1所示
HetuEngine能够支持多种数据源的快速联合查询并提供可视化的数据源配置、管理页面,用户可通过HSConsole界面快速添加数据源,并进行差异化配置。操作示例如下图所示
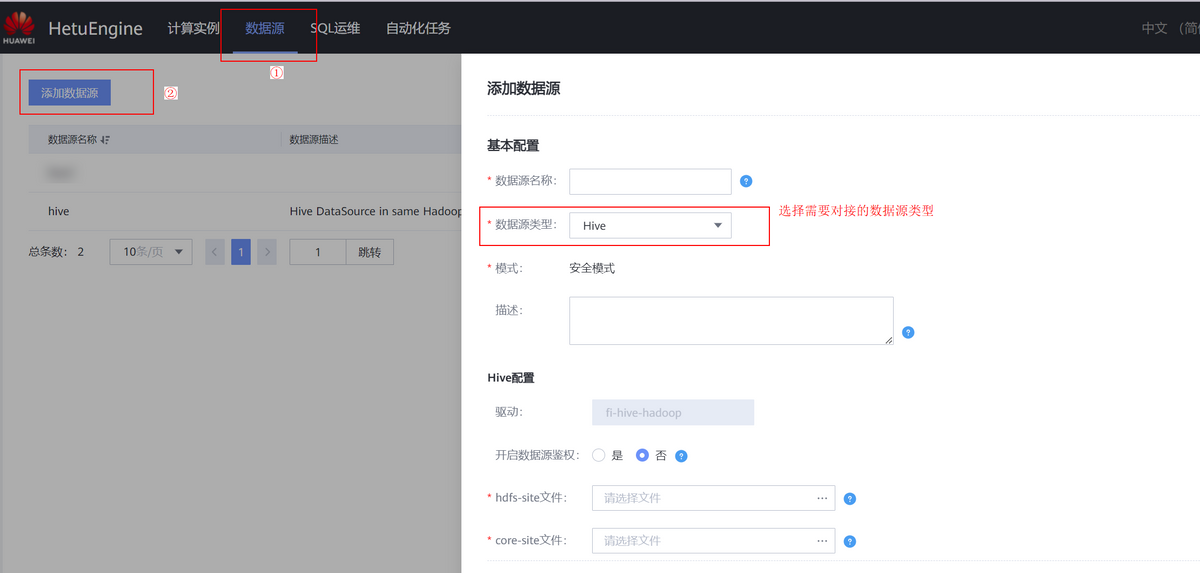
可以通过最下方“自定义配置”添加相应数据源的自定义配置
在HSConsole界面或者使用HSConsole Rest API对数据源的添加、配置、删除等操作支持动态生效,无须重启计算实例。
数据源动态生效时间默认为60秒。如需修改动态生效时间,在计算实例自定义配置添加如下参数,例如:
catalog.scanner-interval =120s
HetuEngine支持查询下推(pushdown),它能把查询,或者部分查询,下推到连接的数据源。这意味着特殊的谓词,聚合函数或者其它一些操作,可以被传递到底层数据库或者文件系统进行处理。查询下推能带来以下好处:
提升整体的查询性能。
减少HetuEngine和数据源之间的网络流量。
减少远端数据源的负载。
HetuEngine对查询下推的具体支持情况,依赖于具体的Connector,以及Connector相关的底层数据源或存储系统。