本文分享自华为云社区《【机器学习 | 决策树】利用数据的潜力:用决策树解锁洞察力》,作者:计算机魔术师 。
决策树是一种基于树形结构的分类模型,它通过对数据属性的逐步划分,将数据集分成多个小的决策单元。每个小的决策单元都对应着一个叶节点,在该节点上进行分类决策。决策树的核心是如何选择最优的分割属性。常见的决策树算法有ID3、C4.5和CART。
决策树的输入数据主要包括训练集和测试集。训练集是已知类别的样本集,测试集则是需要分类的未知样本集。
具体来说,构建决策树的过程可以分为如下几个步骤:
在进行分类时,对输入测试样本,按照各个属性的划分方式逐步匹配,最终到达某个叶子节点,并将该测试样本归为叶子节点所代表的类别。决策树的输出结果就是针对测试样本的分类结果,即该测试样本所属的类别。
决策树的优点在于易于理解和解释,能够处理不同类型的数据,且不需要对数据进行预处理。但是,决策树容易出现过拟合问题,因此在构建决策树时需要进行剪枝操作。常用的剪枝方法包括预剪枝和后剪枝。
假设我们要构建一个决策树来预测一个人是否会购买某个产品。我们将使用以下特征来进行预测:
我们有一个包含以下数据的训练集:
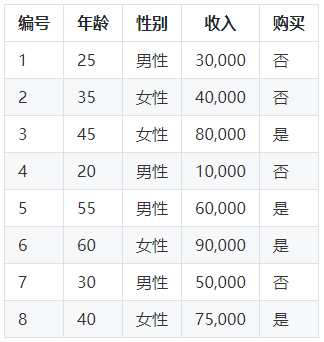
现在,我们将使用这些数据来构建一个决策树模型。
首先,我们选择一个特征来作为根节点。我们可以使用信息增益或基尼不纯度等指标来选择最佳特征。在这个例子中,我们选择使用信息增益。
基尼指数和信息增益都是用于决策树中特征选择的指标,它们各有优劣。
基尼指数是一种衡量数据集纯度或不确定性的指标,常用于决策树算法中的特征选择。它基于基尼系数的概念,用于度量从数据集中随机选择两个样本,其类别标签不一致的概率。
基尼指数的计算公式如下:
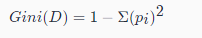
其中,Gini(D)表示数据集D的基尼指数,p_i表示数据集D中第i个类别的样本所占比例。
基尼指数的取值范围为0到1,数值越小表示数据集的纯度越高,即样本的类别越一致。当数据集D中只包含一种类别的样本时,基尼指数为0,表示数据集完全纯净。当数据集D中的样本类别均匀分布时,基尼指数最大(即值越小),为1,表示数据集的不确定性最高。
在决策树算法中,基尼指数被用于衡量选择某个特征进行划分后,数据集的纯度提升程度。通过计算每个特征的基尼指数,选择基尼指数最小的特征作为划分依据,以达到最大程度地减少数据集的不确定性。
计算每个特征的信息增益:
根据信息增益,我们选择性别作为根节点。
信息增益是一种用于选择决策树节点的指标,它衡量了在选择某个特征作为节点后,数据集的纯度提高了多少。信息增益的计算基于信息熵的概念。
信息熵是用来衡量数据集的混乱程度或不确定性的度量。对于一个二分类问题(如购买与否),信息熵的计算公式如下 (多分类也一样,每个不题类别求和):
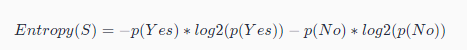
其中,S是数据集,p(Yes)和p(No)分别是购买为"是"和"否"的样本在数据集中的比例。(信息熵代表了分布越平均,样本信息含量越高,不确定性越大,信息熵越大,分布越不均匀,占比越大,信息熵会趋于0。所以以信息熵大小来确定分类,就是为了把一些小范围的集合分离出去)
信息增益的计算公式如下(不同类别信息熵相加):
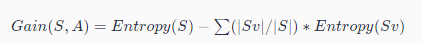
其中,S是数据集,A是要计算信息增益的特征,Sv是特征A的某个取值对应的子集,|Sv|是子集Sv的样本数量,|S|是数据集S的样本数量。 (通过这个子集数量控制其影响权重,然后确定信息增益最大的(即信息熵最小),白话就是选择一个分类中更主流的,特征更明显的)
信息增益越大,意味着使用特征A作为节点可以更好地分割数据集,提高纯度。
在我们的例子中,我们计算了每个特征的信息增益,并选择了具有最大信息增益的特征作为根节点。然后,我们根据根节点的取值将数据集分割成子集,并对每个子集计算信息增益,以选择下一个节点。这个过程一直持续到满足停止条件为止,例如子集中的样本都属于同一类别或达到了预定的树的深度。
总结以下是基尼指数和信息增益的优缺点
优点:
缺点:
综上所述,基尼指数和信息增益在不同的情况下有不同的优劣。在实际应用中,可以根据具体的问题和数据集的特点选择适合的指标。
接下来,我们根据性别的取值(男性或女性)将数据集分割成两个子集。
对于男性子集:
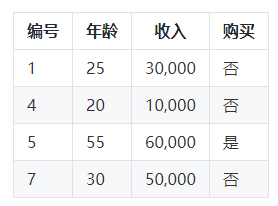
对于女性子集:
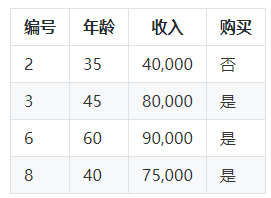
对于男性子集,我们可以看到购买的结果是"是"和"否"都有,所以我们需要进一步划分。我们选择年龄作为下一个节点。
对于年龄的取值(小于等于30岁和大于30岁):
对于小于等于30岁的子集:
|
编号 |
收入 |
购买 |
|---|---|---|
|
1 |
30,000 |
否 |
|
4 |
10,000 |
否 |
|
7 |
50,000 |
否 |
对于大于30岁的子集:
|
编号 |
收入 |
购买 |
|---|---|---|
|
1 |
30,000 |
否 |
|
4 |
10,000 |
否 |
|
7 |
50,000 |
否 |
对于小于等于30岁的子集,购买的结果都是"否",所以我们不需要再进行划分。
对于大于30岁的子集,购买的结果都是"是",所以我们不需要再进行划分。
对于女性子集,购买的结果都是"是",所以我们不需要再进行划分。
最终的决策树如下所示:
性别 = 男性: 年龄 <= 30岁: 否 年龄 > 30岁: 是 性别 = 女性: 是复制
这就是一个简单的决策树的例子。根据输入的特征,决策树可以根据特征的取值进行预测。请注意,这只是一个简单的示例,实际上,决策树可以有更多的特征和更复杂的结构。
首先,我们使用scikit-learn库来实现决策树:
from sklearn import tree import numpy as np # 数据集 X = np.array([[25, 1, 30000], [35, 0, 40000], [45, 0, 80000], [20, 1, 10000], [55, 1, 60000], [60, 0, 90000], [30, 1, 50000], [40, 0, 75000]]) Y = np.array([0, 0, 1, 0, 1, 1, 0, 1]) # 创建决策树模型 clf = tree.DecisionTreeClassifier() # 训练模型 clf = clf.fit(X, Y) # 预测 print(clf.predict([[40, 0, 75000],[10, 0, 75000]])) # 输出:[1, 0]复制
然后,我们不使用任何机器学习库来实现决策树:
import numpy as np class Node: def __init__(self, predicted_class): self.predicted_class = predicted_class # 预测的类别 self.feature_index = 0 # 特征索引 self.threshold = 0 # 阈值 self.left = None # 左子树 self.right = None # 右子树 class DecisionTree: def __init__(self, max_depth=None): self.max_depth = max_depth # 决策树的最大深度 def fit(self, X, y): self.n_classes_ = len(set(y)) # 类别的数量 self.n_features_ = X.shape[1] # 特征的数量 self.tree_ = self._grow_tree(X, y) # 构建决策树 def predict(self, X): return [self._predict(inputs) for inputs in X] # 对输入数据进行预测 def _best_gini_split(self, X, y): m = y.size # 样本的数量 if m <= 1: # 如果样本数量小于等于1,无法进行分割 return None, None num_parent = [np.sum(y == c) for c in range(self.n_classes_)] # 每个类别在父节点中的样本数量 best_gini = 1.0 - sum((n / m) ** 2 for n in num_parent) # 父节点的基尼指数 best_idx, best_thr = None, None # 最佳分割特征索引和阈值 for idx in range(self.n_features_): # 遍历每个特征 thresholds, classes = zip(*sorted(zip(X[:, idx], y))) # 根据特征值对样本进行排序 num_left = [0] * self.n_classes_ # 左子节点中每个类别的样本数量 num_right = num_parent.copy() # 右子节点中每个类别的样本数量,初始值为父节点的样本数量 for i in range(1, m): # 遍历每个样本 c = classes[i - 1] # 样本的类别 num_left[c] += 1 # 更新左子节点中对应类别的样本数量 num_right[c] -= 1 # 更新右子节点中对应类别的样本数量 gini_left = 1.0 - sum( (num_left[x] / i) ** 2 for x in range(self.n_classes_) ) # 左子节点的基尼指数 gini_right = 1.0 - sum( (num_right[x] / (m - i)) ** 2 for x in range(self.n_classes_) ) # 右子节点的基尼指数 gini = (i * gini_left + (m - i) * gini_right) / m # 加权平均的基尼指数 if thresholds[i] == thresholds[i - 1]: # 如果特征值相同,则跳过(特征阈值) continue if gini < best_gini: # 如果基尼指数更小,则更新最佳分割特征索引和阈值 (循环每个特征,和每个阈值,以求解最优分类 best_gini = gini best_idx = idx best_thr = (thresholds[i] + thresholds[i - 1]) / 2 return best_idx, best_thr # 返回最佳分割特征索引和阈值 def _best_gain_split(self, X, y): m = y.size # 样本的数量 if m <= 1: # 如果样本数量小于等于1,无法进行分割 return None, None num_parent = [np.sum(y == c) for c in range(self.n_classes_)] # 计算每个类别的样本数量 best_gain = -1 # 初始化最佳信息增益 best_idx, best_thr = None, None # 初始化最佳特征索引和阈值 for idx in range(self.n_features_): # 遍历每个特征 thresholds, classes = zip(*sorted(zip(X[:, idx], y))) # 对每个特征值和类别标签进行排序 num_left = [0] * self.n_classes_ # 初始化左子树的类别数量 (左边都是0,为0时自动计算为0) num_right = num_parent.copy() # 右子树的类别数量初始化为父节点的类别数量 (右边是全部) for i in range(1, m): # 遍历每个样本 c = classes[i - 1] # 获取当前样本的类别 num_left[c] += 1 # 左子树的类别数量增加 num_right[c] -= 1 # 右子树的类别数量减少 entropy_parent = -sum((num / m) * np.log2(num / m) for num in num_parent if num != 0) # 计算父节点的熵 entropy_left = -sum((num / i) * np.log2(num / i) for num in num_left if num != 0) # 计算左子树的熵 entropy_right = -sum((num / (m - i)) * np.log2(num / (m - i)) for num in num_right if num != 0) # 计算右子树的熵 gain = entropy_parent - (i * entropy_left + (m - i) * entropy_right) / m # 计算信息增益(分类后左右的信息熵最小) if thresholds[i] == thresholds[i - 1]: # 如果当前样本的特征值和前一个样本的特征值相同,跳过(不一样才能分界) continue if gain > best_gain: # 如果当前的信息增益大于最佳信息增益 best_gain = gain # 更新最佳信息增益 best_idx = idx # 更新最佳特征索引 best_thr = (thresholds[i] + thresholds[i - 1]) / 2 # 更新最佳阈值 (循环每个样本的值,根据两份数据均值确定阈值,一直循环) return best_idx, best_thr # 返回最佳特征索引和阈值 def _grow_tree(self, X, y, depth=0): num_samples_per_class = [np.sum(y == i) for i in range(self.n_classes_)] # 计算每个类别的样本数量 predicted_class = np.argmax(num_samples_per_class) # 预测的类别为样本数量最多的类别 (即确定分到该分支样本最多的记为该类) node = Node(predicted_class=predicted_class) # 创建节点 if depth < self.max_depth: # 如果当前深度小于最大深度 idx, thr = self._best_gain_split(X, y) # 计算最佳分割 if idx is not None: # 如果存在最佳分割 indices_left = X[:, idx] < thr # 左子树的样本索引 (第 idx特征中小于thr阈值的索引) X_left, y_left = X[indices_left], y[indices_left] # 左子树的样本 X_right, y_right = X[~indices_left], y[~indices_left] # 右子树的样本 node.feature_index = idx # 设置节点的特征索引 node.threshold = thr # 设置节点的阈值 node.left = self._grow_tree(X_left, y_left, depth + 1) # 构建左子树 node.right = self._grow_tree(X_right, y_right, depth + 1) # 构建右子树 return node # 返回节点 def _predict(self, inputs): node = self.tree_ # 获取决策树的根节点 while node.left: # 如果存在左子树 if inputs[node.feature_index] < node.threshold: # 如果输入样本的特征值小于阈值 node = node.left # 到左子树 else: node = node.right # 到右子树 return node.predicted_class # 返回预测的类别 # 数据集 X = [[25, 1, 30000], [35, 0, 40000], [45, 0, 80000], [20, 1, 10000], [55, 1, 60000], [60, 0, 90000], [30, 1, 50000], [40, 0, 75000]] Y = [0, 0, 1, 0, 1, 1, 0, 1] # 创建决策树模型 clf = DecisionTree(max_depth=2) # 训练模型 clf.fit(np.array(X), np.array(Y)) # 预测 print(clf.predict([[40, 0, 75000],[10, 0, 75000]])) # 输出:[1, 0]复制
请注意,这个不使用任何机器学习库的决策树实现是一个基本的版本,它可能无法处理所有的情况,例如缺失值、分类特征等。在实际应用中,我们通常使用成熟的机器学习库,如scikit-learn,因为它们提供了更多的功能和优化。
当决策树用于回归任务时,它被称为决策树回归模型。与分类树不同,决策树回归模型的叶子节点不再表示类别标签,而是表示一段连续区间或者一个数值。它同样基于树形结构,通过对数据特征的逐步划分,将数据集分成多个小的决策单元,并在每个叶子节点上输出一个预测值。
以下是决策树回归模型的详细原理:
1.划分过程
与分类树相似,决策树回归模型也采用递归二分的方式进行划分。具体来说,从根节点开始,选择一个最优特征和该特征的最优划分点。然后将数据集按照该特征的取值分为两部分,分别构建左右子树。重复以上步骤,直到满足停止条件,比如达到最大深度、划分后样本数少于阈值等。
2.叶子节点的输出值
当到达某个叶子节点时,该叶子节点的输出值就是训练集中该叶子节点对应的所有样本的平均值(或中位数等)。
3.预测过程
对于一个测试样本,从根节点开始,按照各个特征的划分方式逐步匹配,最终到达某个叶子节点,并将该测试样本的预测值设为该叶子节点的输出值。
4.剪枝操作
与分类树一样,决策树回归模型也容易出现过拟合问题,因此需要进行剪枝操作。常用的剪枝方法包括预剪枝和后剪枝。
5.特点
决策树回归模型具有以下特点:
(1)易于解释:决策树回归模型能够直观地反映各个特征对目标变量的影响程度。
(2)非参数性:决策树回归模型不对数据分布做任何假设,适用于各种类型的数据。
(3)可处理多元特征:决策树回归模型可以同时处理多个输入特征。
(4)不需要数据正态化:决策树回归模型不需要对输入数据进行正态化等预处理。

华为将于2023年9月20-22日,在上海世博展览馆和上海世博中心举办第八届华为全联接大会(HUAWEICONNECT 2023)。本次大会以“加速行业智能化”为主题,邀请思想领袖、商业精英、技术专家、合作伙伴、开发者等业界同仁,从商业、产业、生态等方面探讨如何加速行业智能化。
我们诚邀您莅临现场,分享智能化的机遇和挑战,共商智能化的关键举措,体验智能化技术的创新和应用。您可以:
感谢您一如既往的支持和信赖,我们热忱期待与您在上海见面。
大会官网:https://www.huawei.com/cn/events/huaweiconnect
欢迎关注“华为云开发者联盟”公众号,获取大会议程、精彩活动和前沿干货。