本文分享自华为云社区《云原生批量计算引擎 Volcano社区v1.8.0版本正式发布》,作者: 云容器大未来。
北京时间2023年8月17日,Volcano 社区 v1.8.0 版本正式发布,此次版本增加了以下新特性:
支持vGPU调度及隔离
支持vGPU和用户自定义资源的抢占能力
新增JobFlow工作流编排引擎
节点负载感知调度与重调度支持多样化的监控系统
优化Volcano对通用服务调度的能力
优化Volcano charts包的发布与归档

Volcano是业界首个云原生批量计算项目,于2019年6月在上海 KubeCon 正式开源,并在2020年4月成为 CNCF 官方项目。2022年4月,Volcano 正式晋级为CNCF 孵化项目。Volcano 社区开源以来,受到众多开发者、合作伙伴和用户的认可和支持。截至目前,累计有590+全球开发者参与社区贡献。
自 ChatGPT 爆火之后,AI大模型的研发层出不穷,不同种类的AI大模型也相继推出,由于其庞大的训练任务需要大量算力,以 GPU 为核心的算力供给已成为大模型产业发展的关键基础设施。在实际使用场景中,用户对于 GPU 资源的使用存在资源利用率低,资源分配不灵活等痛点问题,必须采购大量冗余的异构算力才能满足业务需求,而异构算力本身成本高昂,为企业的发展带来了很大的负担。
从 1.8版本开始,Volcano 为可共享设备(GPU、NPU、FPGA...)提供一个抽象的通用框架,开发者可以基于该框架自定义多种类型的共享设备;当前,Volcano 已基于该框架实现 GPU 虚拟化特性,支持 GPU 设备复用、资源隔离等能力,详情如下:
GPU共享:每个任务可以申请使用一个 GPU 卡的部分资源,GPU 卡可以在多个任务之间共享。
设备显存控制:GPU 可以按照设备显存分配(比如:3000M)或者按比例分配(比如:50%),实现 GPU 虚拟化资源隔离能力。
关于 vGPU 的更多信息,请参考:
如何使用 vGPU 功能:https://github.com/volcano-sh/volcano/blob/master/docs/user-guide/how_to_use_vgpu.md
如何增加新的异构算力共享策略:https://github.com/volcano-sh/volcano/blob/master/docs/design/device-sharing.md
当前 Volcano 支持 CPU、Memory 等基础资源抢占功能,对于 GPU 资源和用户基于 Volcano 框架二次开发调度插件,并自主管理的资源(如:NPU、网络资源等)尚不能很好的支持抢占能力。
在1.8版本中,Volcano 对节点过滤相关处理( PredicateFn 回调函数)进行重构,返回结果中增加 Status 类型,用于标识在调度、抢占等场景下,当前节点是否满足作业下发条件。GPU 抢占功能已基于优化后的框架实现发布,用户基于Volcano 进行二次开发的调度插件可以结合业务场景适配升级。
关于支持扩展资源抢占的更多信息,请参考:https://github.com/volcano-sh/volcano/pull/2916
工作流编排引擎广泛应用于高性能计算、AI 生物医药、图片处理、美颜、游戏AGI、科学计算等场景,帮助用户简化多个任务并行与依赖关系的管理,大幅度提升整体计算效率。
JobFlow 是一种轻量化的任务流编排引擎,专注于 Volcano 的作业编排,为Volcano 提供作业探针、作业完成依赖,作业失败率容忍等多样化作业依赖类型,并支持复杂的流程控制原语,具体能力如下:
支持大规模作业管理以及复杂任务流编排
支持实时查询到所有关联作业的运行情况以及任务进度
支持作业自动运行、定时启动释放人力成本
支持不同任务可以设置多种动作策略,当任务满足特定条件时即可触发对应动作,如超时重试、节点故障漂移等
JobFlow 任务运行演示如下:
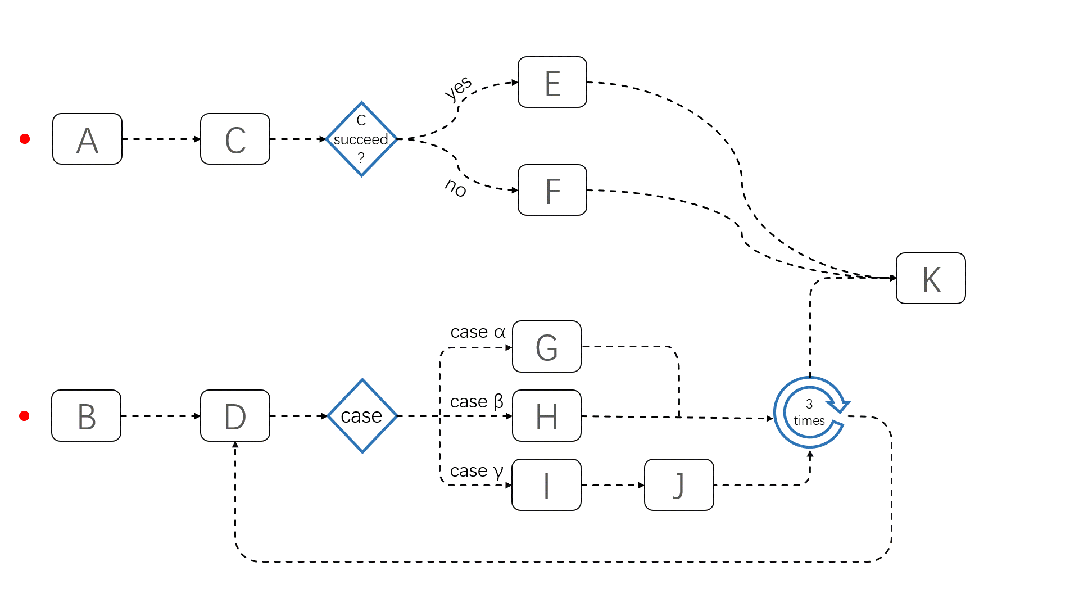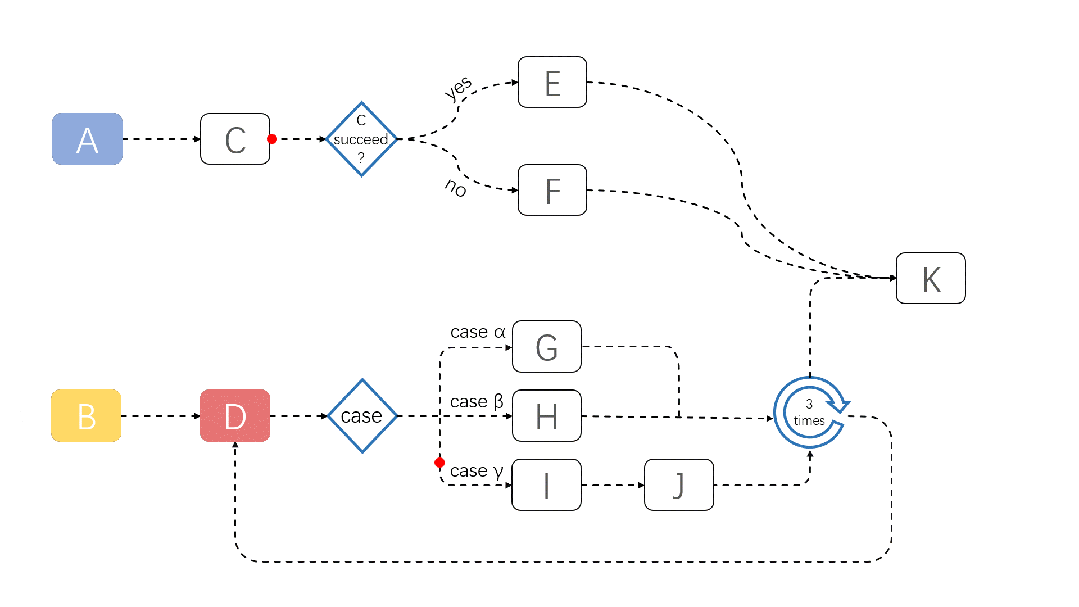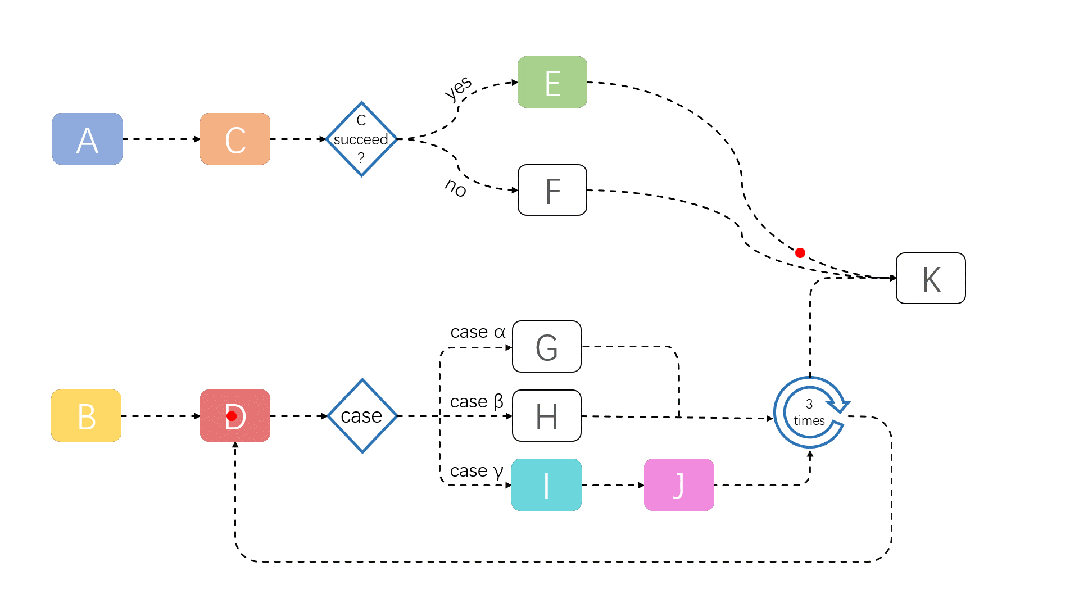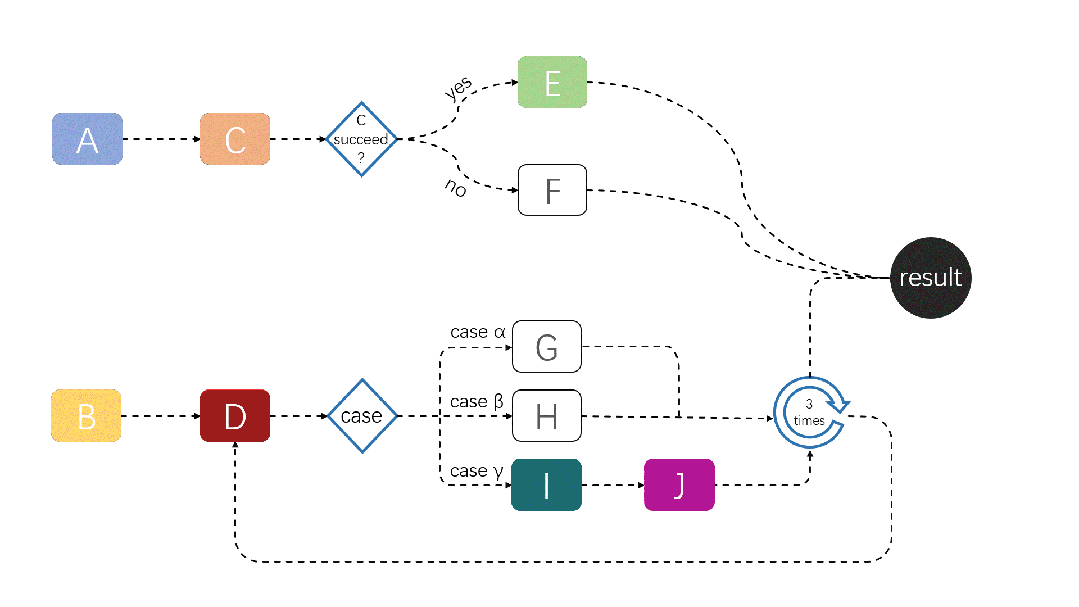
关于 JobFlow 的更多信息,请参考:https://github.com/volcano-sh/volcano/blob/master/docs/design/jobflow/README.md
Kubernetes 集群状态随着任务的创建和结束实时变化,在某些场景(如:增加、删除节点,Pod、Node 的亲和性改变,作业生命周期动态变化等),出现集群节点间资源利用率不均衡,节点性能瓶颈掉线等问题,此时基于真实负载的调度与重调度可以帮助我们解决上述问题。
Volcano 1.8版本之前,真实负载调度与重调度的指标获取仅支持 Prometheus,从1.8版本开始,Volcano 优化监控指标获取框架,新增 ElasticSearch 监控系统支持,并支持以较小适配工作量平滑对接更多类型监控系统。
关于支持多种监控系统的更多信息,请参考:
基于节点负载感知调度:https://github.com/volcano-sh/volcano/blob/master/docs/design/usage-based-scheduling.md
重调度:https://github.com/volcano-sh/volcano/blob/master/docs/design/rescheduling.md
Volcano 是一个统一的融合调度系统,不仅支持 AI、BigData 等计算类作业,也支持微服务工作负载,兼容 Kubernetes 默认调度器的 PodTopologySpread、VolumeZone、VolumeLimits、NodeAffinity、PodAffinity等调度插件,Kubernetes 默认调度插件能力在 Volcano 中默认开启。
自 Volcano 1.8 版本开始,Kubernetes 默认调度插件可以通过配置文件的方式自由选择打开和关闭,默认全部打开,如果选择关闭部分插件,比如:关闭PodTopologySpread 和 VolumeZone插件,可以在 predicate 插件中将对应的值设置为 false,配置如下:
actions: "allocate, backfill, preempt"tiers:- plugins: - name: priority - name: gang - name: conformance- plugins: - name: drf - name: predicates arguments: predicate.VolumeZoneEnable: false predicate.PodTopologySpreadEnable: false - name: proportion - name: nodeorder
更多信息,请参考:https://github.com/volcano-sh/volcano/issues/2748
在 Kubernetes 平台中,Volcano 除了作为批量计算业务的调度器之外,也被越来越多的用作通用服务的调度器。Node 水平伸缩(ClusterAutoscaler)是Kubernetes 的核心功能之一,在面对用户业务量激增和节省运行成本方面发挥重要作用。Volcano 优化作业调度等相关逻辑,增强与 ClusterAutoscaler 的兼容互动能力,主要为以下两个方面:
调度阶段进入 pipeline 状态的 pod 及时触发扩容
候选节点分梯度打分,减少集群 terminating pod 对调度负载的影响,避免pod 进入无效 pipeline 状态,从而导致集群误扩容
更多信息,请参考:https://github.com/volcano-sh/volcano/issues/3000
https://github.com/volcano-sh/volcano/issues/2782
当节点中由于某种原因比如 device-plugin 上报信息异常,出现节点的某种资源总量小于已分配资源量时,Volcano 认为该节点数据不一致,会隔离节点,停止向该节点调度任何新的工作负载。在1.8版本中,对于节点资源进行精细化管理,比如:当节点的 GPU 总资源容量小于已分配资源量时,申请 GPU 资源的 pod 禁止再调度至该节点,申请非 GPU 资源的作业,将仍然允许正常向该节点调度。
更多信息,请参考:https://github.com/volcano-sh/volcano/issues/2999
随着 Volcano 在用户越来越多的生产环境和云环境中使用,简洁标准的安装动作至关重要。自1.8版本开始,Volcano 优化 charts 包发布归档动作,标准化安装使用流程,并完成历史版本(v1.6、v1.7)向新 helm 仓库的迁移,使用方式如下:
● 添加 Volcano charts 仓地址
helm repo add volcano-sh https://volcano-sh.github.io/helm-chart
● 查询所有可安装的 Volcano 版本
helm search repo volcano -l
● 安装最新版 Volcano
helm install volcano volcano-sh/volcano -n volcano-system --create-namespace
● 安装指定版本 Volcano,比如:1.7.0
helm install volcano volcano-sh/volcano -n volcano-system --create-namespace --version 1.7.0
关于 Volcano charts 包的更多信息,请参考:https://github.com/volcano-sh/helm-charts
Volcano 1.8.0 版本包含了来自 31 位贡献者的数百次代码提交,在此对各位贡献者表示由衷的感谢:
贡献者GitHub ID
Release note: v1.8.0:https://github.com/volcano-sh/volcano/releases/tag/v1.8.0
Branch:release-1.8:https://github.com/volcano-sh/volcano/tree/release-1.8
Volcano 云原生批量计算项目主要用于 AI、大数据、基因、渲染等诸多高性能计算场景,对主流通用计算框架均有很好的支持。社区已吸引5.8万+全球开发者,并获得3.2k Star 和730+ Fork,参与贡献企业包括华为、AWS、百度、腾讯、京东、小红书、博云、第四范式等。目前,Volcano在人工智能、大数据、基因测序等海量数据计算和分析场景已得到快速应用,已完成对 Spark、Flink、Tensorflow、PyTorch、Argo、MindSpore、Paddlepaddle 、Kubeflow、MPI、Horovod、mxnet、KubeGene、Ray 等众多主流计算框架的支持,并构建起完善的上下游生态。
Volcano官网:https://volcano.sh
GitHub: https://github.com/volcano-sh/volcano
每周例会: https://zoom.us/j/91804791393

华为将于2023年9月20-22日,在上海世博展览馆和上海世博中心举办第八届华为全联接大会(HUAWEICONNECT 2023)。本次大会以“加速行业智能化”为主题,邀请思想领袖、商业精英、技术专家、合作伙伴、开发者等业界同仁,从商业、产业、生态等方面探讨如何加速行业智能化。
我们诚邀您莅临现场,分享智能化的机遇和挑战,共商智能化的关键举措,体验智能化技术的创新和应用。您可以:
感谢您一如既往的支持和信赖,我们热忱期待与您在上海见面。
大会官网:https://www.huawei.com/cn/events/huaweiconnect
欢迎关注“华为云开发者联盟”公众号,获取大会议程、精彩活动和前沿干货。