本文为生成对抗网络GAN的研究者和实践者提供全面、深入和实用的指导。通过本文的理论解释和实际操作指南,读者能够掌握GAN的核心概念,理解其工作原理,学会设计和训练自己的GAN模型,并能够对结果进行有效的分析和评估。
作者 TechLead,拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人

生成对抗网络(GAN)是深度学习的一种创新架构,由Ian Goodfellow等人于2014年首次提出。其基本思想是通过两个神经网络,即生成器(Generator)和判别器(Discriminator),相互竞争来学习数据分布。
两者之间的竞争推动了模型的不断进化,使得生成的数据逐渐接近真实数据分布。
GANs在许多领域都有广泛的应用,从艺术和娱乐到更复杂的科学研究。以下是一些主要的应用领域:



GAN的提出不仅在学术界引起了广泛关注,也在工业界取得了实际应用。其重要性主要体现在以下几个方面:
生成对抗网络(GAN)由两个核心部分组成:生成器(Generator)和判别器(Discriminator),它们共同工作以达到特定的目标。
生成器负责从一定的随机分布(如正态分布)中抽取随机噪声,并通过一系列的神经网络层将其映射到数据空间。其目标是生成与真实数据分布非常相似的样本,从而迷惑判别器。
def generator(z):
# 输入:随机噪声z
# 输出:生成的样本
# 使用多层神经网络结构生成样本
# 示例代码,输出生成的样本
return generated_sample
复制判别器则尝试区分由生成器生成的样本和真实的样本。判别器是一个二元分类器,其输入可以是真实数据样本或生成器生成的样本,输出是一个标量,表示样本是真实的概率。
def discriminator(x):
# 输入:样本x(可以是真实的或生成的)
# 输出:样本为真实样本的概率
# 使用多层神经网络结构判断样本真伪
# 示例代码,输出样本为真实样本的概率
return probability_real
复制生成对抗网络的训练过程是一场两个网络之间的博弈,具体分为以下几个步骤:
# 训练判别器和生成器
# 示例代码,同时注释后增加指令的输出
复制GAN的训练通常需要仔细平衡生成器和判别器的能力,以确保它们同时进步。此外,GAN的训练收敛性也是一个复杂的问题,涉及许多技术和战略。
生成对抗网络的理解和实现需要涉及多个数学概念,其中主要包括概率论、最优化理论、信息论等。
损失函数是GAN训练的核心,用于衡量生成器和判别器的表现。
生成器的目标是最大化判别器对其生成样本的错误分类概率。损失函数通常表示为:
L_G = -\mathbb{E}[\log D(G(z))]复制
其中,(G(z)) 表示生成器从随机噪声 (z) 生成的样本,(D(x)) 是判别器对样本 (x) 为真实的概率估计。
判别器的目标是正确区分真实数据和生成数据。损失函数通常表示为:
L_D = -\mathbb{E}[\log D(x)] - \mathbb{E}[\log (1 - D(G(z)))]复制
其中,(x) 是真实样本。
GAN的训练涉及复杂的非凸优化问题,常用的优化算法包括:
# 使用PyTorch的Adam优化器
from torch.optim import Adam
optimizer_G = Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
复制这些数学背景为理解生成对抗网络的工作原理提供了坚实基础,并揭示了训练过程中的复杂性和挑战性。通过深入探讨这些概念,读者可以更好地理解GAN的内部运作,从而进行更高效和有效的实现。
生成对抗网络自从提出以来,研究者们已经提出了许多不同的架构和变体,以解决原始GAN存在的一些问题,或者更好地适用于特定应用。
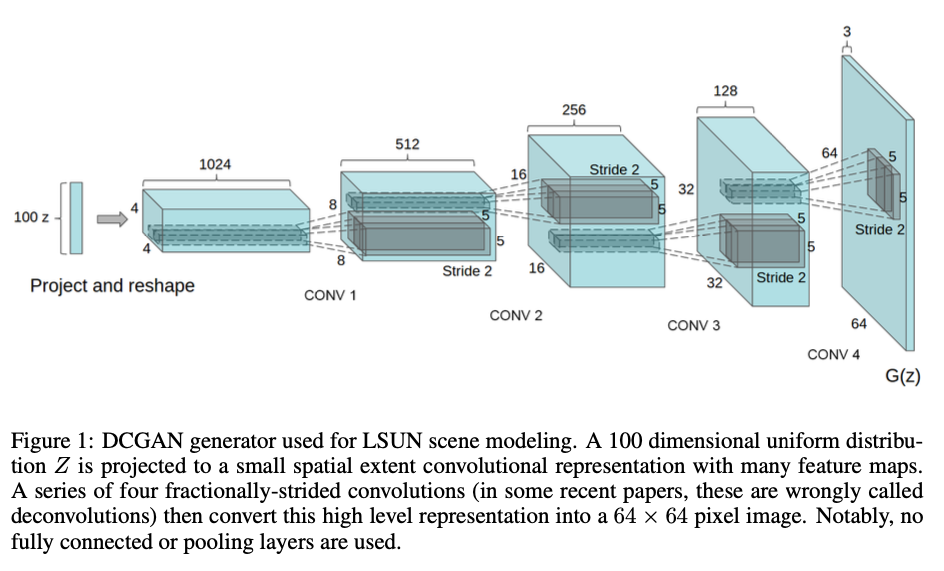
DCGAN是使用卷积层的GAN变体,特别适用于图像生成任务。
# DCGAN生成器的PyTorch实现
import torch.nn as nn
class DCGAN_Generator(nn.Module):
def __init__(self):
super(DCGAN_Generator, self).__init__()
# 定义卷积层等
复制WGAN通过使用Wasserstein距离来改进GAN的训练稳定性。
CycleGAN用于进行图像到图像的转换,例如将马的图像转换为斑马的图像。
InfoGAN通过最大化潜在代码和生成样本之间的互信息,使得潜在空间具有更好的解释性。
此外还有许多其他的GAN变体,例如:
生成对抗网络的这些常见架构和变体展示了GAN在不同场景下的灵活性和强大能力。理解这些不同的架构可以帮助读者选择适当的模型来解决具体问题,也揭示了生成对抗网络研究的多样性和丰富性。

在进入GAN的实际编码和训练之前,我们首先需要准备适当的开发环境和数据集。这里的内容会涵盖所需库的安装、硬件要求、以及如何选择和处理适用于GAN训练的数据集。
构建和训练GAN需要一些特定的软件库和硬件支持。
# 安装PyTorch
pip install torch torchvision
复制GAN可以用于多种类型的数据,例如图像、文本或声音。以下是数据集选择和预处理的一般指南:
# 使用PyTorch加载CIFAR-10数据集
from torchvision import datasets, transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
复制环境准备和数据集的选择与预处理是实施GAN项目的关键初始步骤。选择适当的软件、硬件和数据集,并对其进行适当的预处理,将为整个项目的成功奠定基础。读者应充分考虑这些方面,以确保项目从一开始就在可行和有效的基础上进行。
生成器是生成对抗网络中的核心部分,负责从潜在空间的随机噪声中生成与真实数据相似的样本。以下是更深入的探讨:
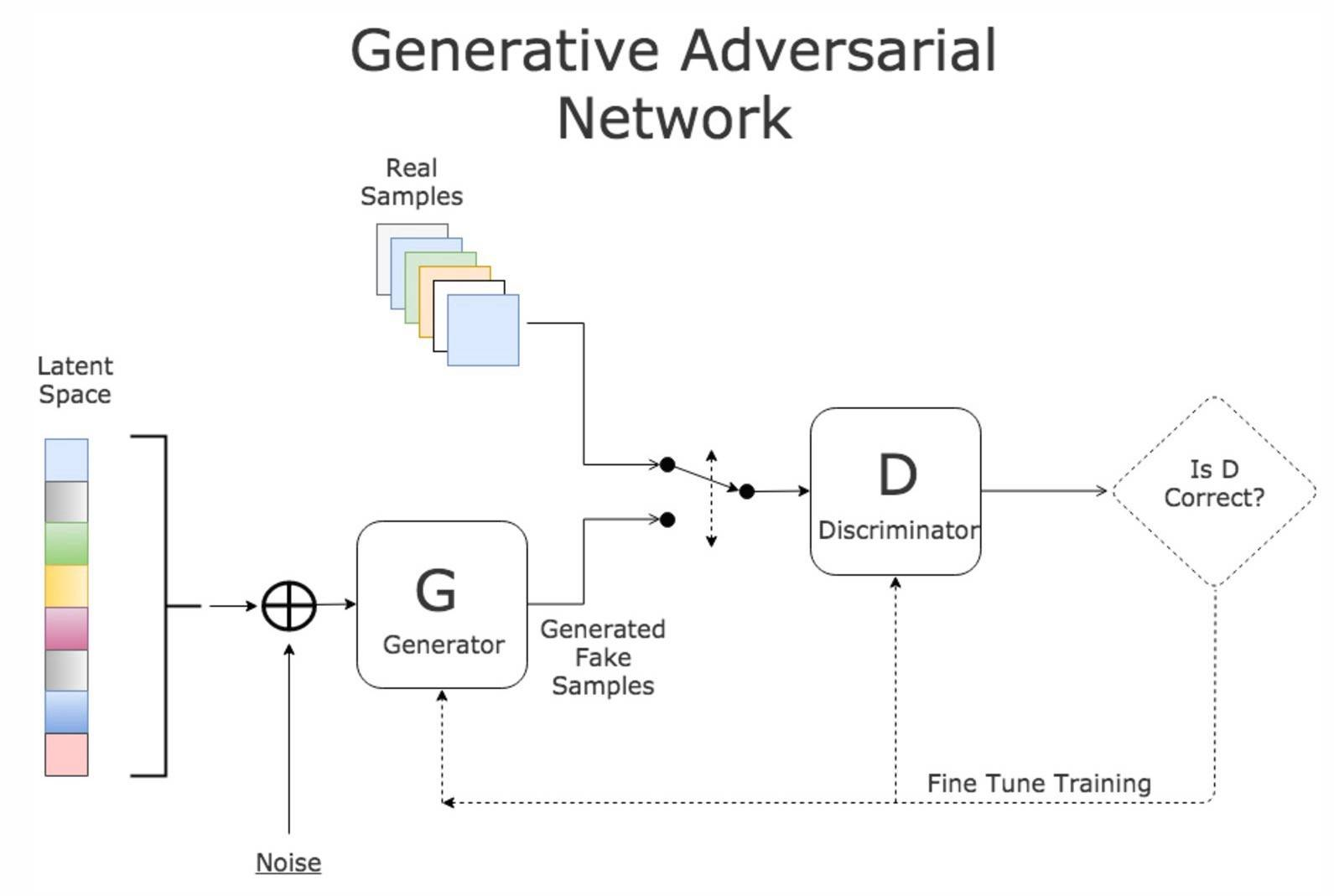
生成器的设计需要深思熟虑,因为它决定了生成数据的质量和多样性。
适用于较简单的数据集,如MNIST。
class SimpleGenerator(nn.Module):
def __init__(self):
super(SimpleGenerator, self).__init__()
self.main = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 784),
nn.Tanh()
)
def forward(self, input):
return self.main(input)
复制适用于更复杂的图像数据生成,如DCGAN。
class ConvGenerator(nn.Module):
def __init__(self):
super(ConvGenerator, self).__init__()
self.main = nn.Sequential(
# 逆卷积层
nn.ConvTranspose2d(100, 512, 4),
nn.BatchNorm2d(512),
nn.ReLU(),
# ...
)
def forward(self, input):
return self.main(input)
复制生成器构建是一个复杂和细致的过程。通过深入了解生成器的各个组成部分和它们是如何协同工作的,我们可以设计出适应各种任务需求的高效生成器。不同类型的激活函数、归一化、潜在空间设计以及与判别器的协同工作等方面的选择和优化是提高生成器性能的关键。
生成对抗网络(GAN)的判别器是一个二分类模型,用于区分生成的数据和真实数据。以下是判别器构建的详细内容:
class ConvDiscriminator(nn.Module):
def __init__(self):
super(ConvDiscriminator, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(3, 64, 4, stride=2, padding=1),
nn.LeakyReLU(0.2),
# ...
nn.Sigmoid() # 二分类输出
)
def forward(self, input):
return self.main(input)
复制判别器的设计和实现是复杂的多步过程。通过深入了解判别器的各个组件以及它们是如何协同工作的,我们可以设计出适应各种任务需求的强大判别器。判别器的架构选择、激活函数、损失设计、正则化方法,以及如何与生成器协同工作等方面的选择和优化,是提高判别器性能的关键因素。
损失函数和优化器是训练生成对抗网络(GAN)的关键组件,它们共同决定了GAN的训练速度和稳定性。
损失函数量化了GAN的生成器和判别器之间的竞争程度。
# 判别器损失
real_loss = F.binary_cross_entropy(D_real, ones_labels)
fake_loss = F.binary_cross_entropy(D_fake, zeros_labels)
discriminator_loss = real_loss + fake_loss
# 生成器损失
generator_loss = F.binary_cross_entropy(D_fake, ones_labels)
复制优化器负责根据损失函数的梯度更新模型的参数。
# 示例
optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
复制损失函数和优化器在GAN的训练中起着核心作用。损失函数界定了生成器和判别器之间的竞争关系,而优化器则决定了如何根据损失函数的梯度来更新这些模型的参数。在设计损失函数和选择优化器时需要考虑许多因素,包括训练的稳定性、速度、鲁棒性等。理解各种损失函数和优化器的工作原理,可以帮助我们为特定任务选择合适的方法,更好地训练GAN。
在生成对抗网络(GAN)的实现中,模型训练是最关键的阶段之一。本节详细探讨模型训练的各个方面,包括训练循环、收敛监控、调试技巧等。
训练循环是GAN训练的心脏,其中包括了前向传播、损失计算、反向传播和参数更新。
for epoch in range(epochs):
for real_data, _ in dataloader:
# 更新判别器
optimizer_D.zero_grad()
real_loss = ...
fake_loss = ...
discriminator_loss = real_loss + fake_loss
discriminator_loss.backward()
optimizer_D.step()
# 更新生成器
optimizer_G.zero_grad()
generator_loss = ...
generator_loss.backward()
optimizer_G.step()
复制GAN训练可能非常不稳定,下面是一些常用的稳定化技术:
GAN没有明确的损失函数来评估生成器的性能,因此通常需要使用一些启发式的评估方法:
GAN的训练是一项复杂和微妙的任务,涉及许多不同的组件和阶段。通过深入了解训练循环的工作原理,学会使用各种稳定化技术,和掌握模型评估和超参数调优的方法,我们可以更有效地训练GAN模型。
生成对抗网络(GAN)的训练结果分析和可视化是评估模型性能、解释模型行为以及调整模型参数的关键环节。本节详细讨论如何分析和可视化GAN模型的生成结果。
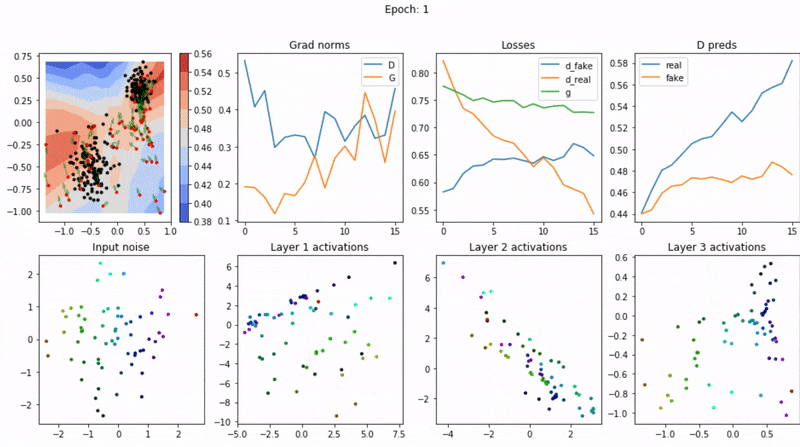
可视化是理解GAN的生成能力的直观方法。常见的可视化方法包括:
虽然可视化直观,但量化评估提供了更准确的性能度量。常用的量化方法包括:
理解GAN如何工作以及每个部分的作用可以帮助改进模型:
结果分析和可视化不仅是GAN工作流程的最后一步,还是一个持续的、反馈驱动的过程,有助于改善和优化整个系统。可视化和量化分析工具提供了深入了解GAN性能的方法,从直观的生成样本检查到复杂的量化度量。通过这些工具,我们可以评估模型的优点和缺点,并做出有针对性的调整。
生成对抗网络(GAN)作为一种强大的生成模型,在许多领域都有广泛的应用。本文全面深入地探讨了GAN的不同方面,涵盖了理论基础、常见架构、实际实现和结果分析。以下是主要的总结点:

GAN的研究和应用仍然是一个快速发展的领域。随着技术的不断进步和更多的实际应用,我们期望未来能够看到更多高质量的生成样本,更稳定的训练方法,以及更广泛的跨领域应用。GAN的理论和实践的深入融合将为人工智能和机器学习领域开辟新的可能性。
作者 TechLead,拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人
如有帮助,请多关注
个人微信公众号:【TechLead】分享AI与云服务研发的全维度知识,谈谈我作为TechLead对技术的独特洞察。
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。