在本文中,我们深入探讨了循环神经网络(RNN)及其高级变体,包括长短时记忆网络(LSTM)、门控循环单元(GRU)和双向循环神经网络(Bi-RNN)。文章详细介绍了RNN的基本概念、工作原理和应用场景,同时提供了使用PyTorch构建、训练和评估RNN模型的完整代码指南。
作者 TechLead,拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
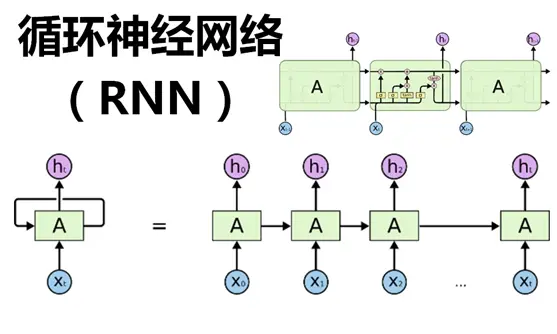
循环神经网络(Recurrent Neural Network, RNN)是一类具有内部环状连接的人工神经网络,用于处理序列数据。其最大特点是网络中存在着环,使得信息能在网络中进行循环,实现对序列信息的存储和处理。
RNN的基本结构如下:
# 一个简单的RNN结构示例
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
def forward(self, x):
out, _ = self.rnn(x)
return out
复制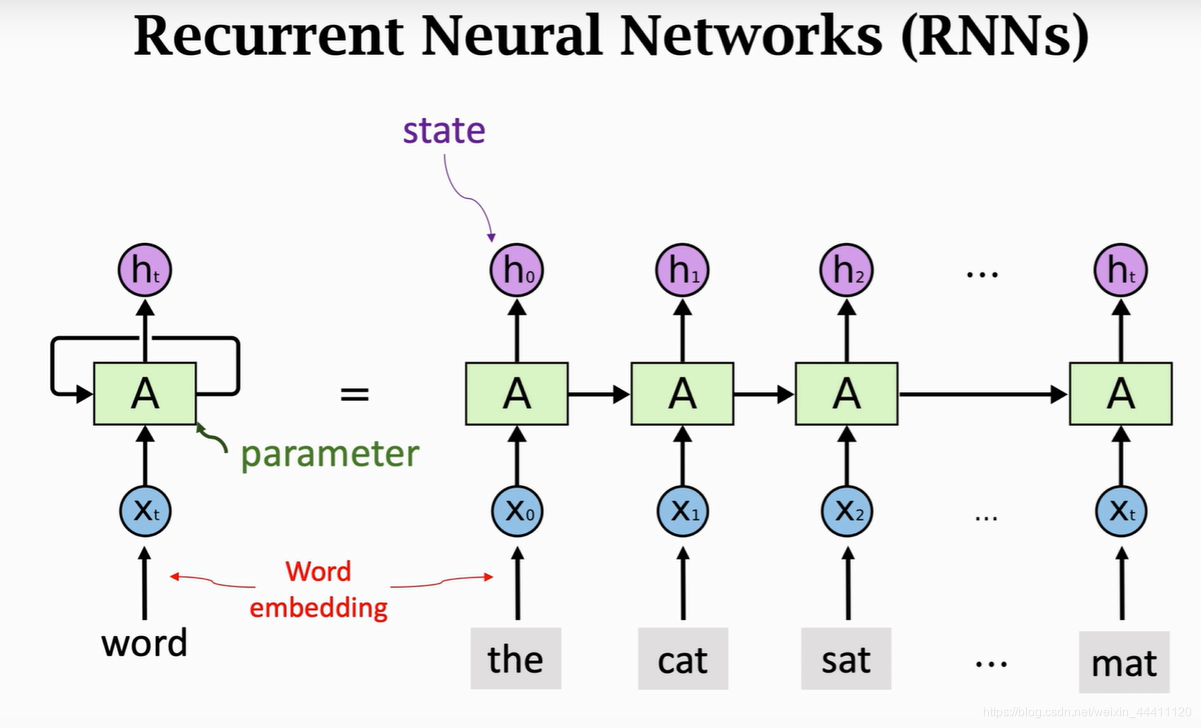
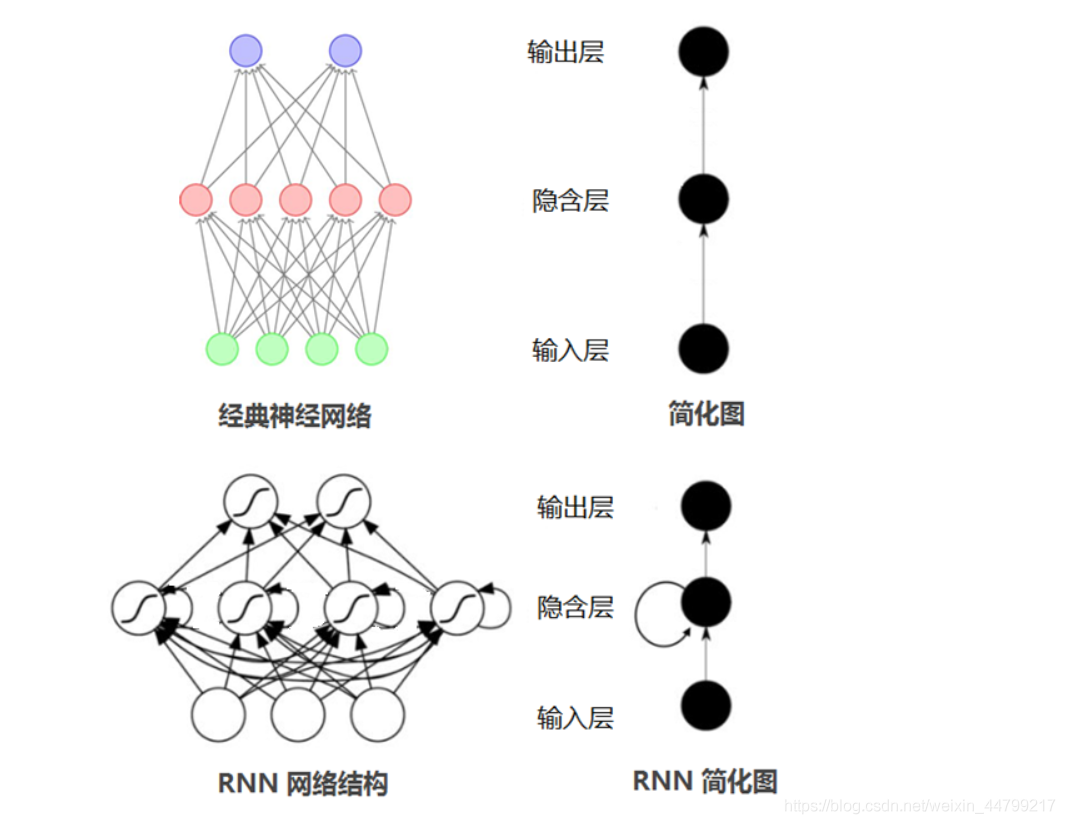
输入层:RNN能够接受一个输入序列(例如文字、股票价格、语音信号等)并将其传递到隐藏层。
隐藏层:隐藏层之间存在循环连接,使得网络能够维护一个“记忆”状态,这一状态包含了过去的信息。这使得RNN能够理解序列中的上下文信息。
输出层:RNN可以有一个或多个输出,例如在序列生成任务中,每个时间步都会有一个输出。
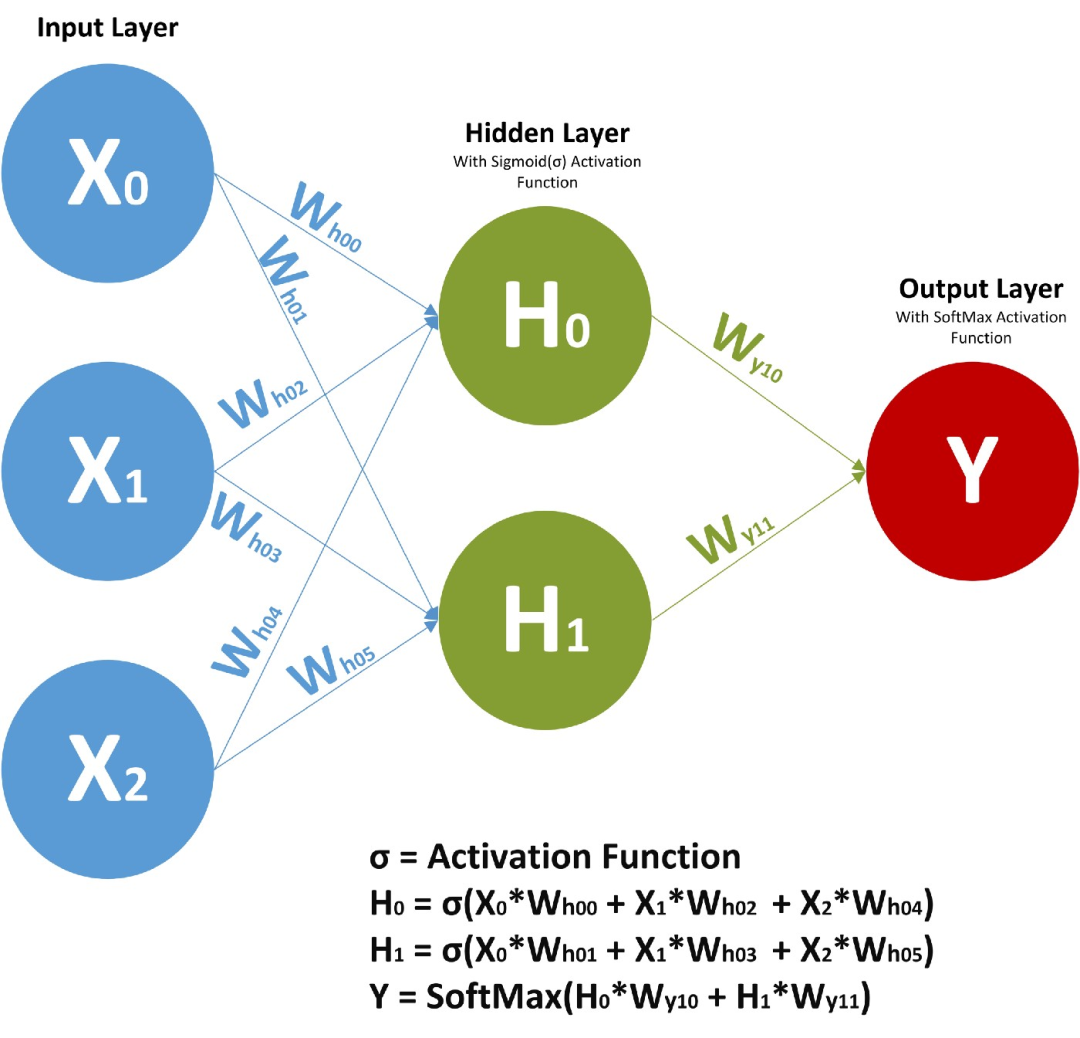
RNN的工作原理可以通过以下数学方程表示:
其中,( h_t ) 表示在时间 ( t ) 的隐藏层状态,( x_t ) 表示在时间 ( t ) 的输入,( y_t ) 表示在时间 ( t ) 的输出。
优点:
缺点:
循环神经网络是一种强大的模型,特别适合于处理具有时间依赖性的序列数据。然而,标准RNN通常难以学习长序列中的依赖关系,因此有了更多复杂的变体如LSTM和GRU,来解决这些问题。不过,RNN的基本理念和结构仍然是深度学习中序列处理的核心组成部分。
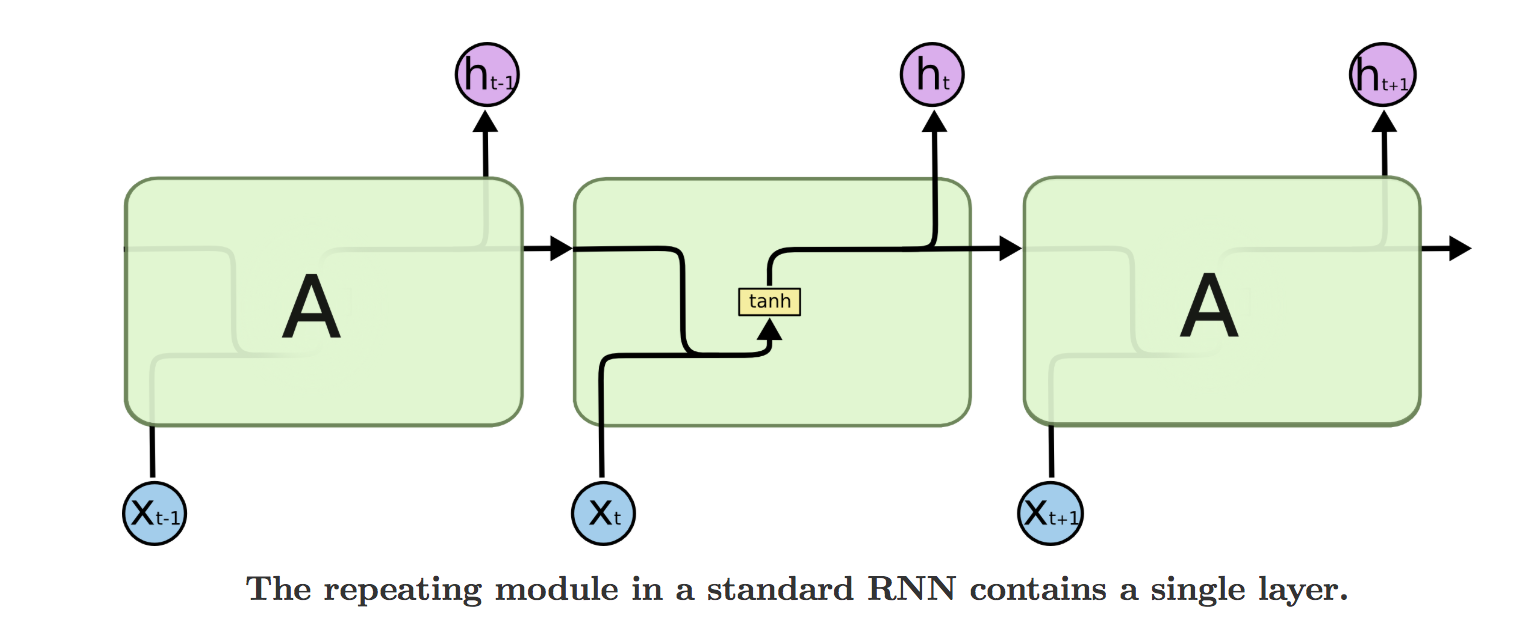
循环神经网络(RNN)的工作原理是通过网络中的环状连接捕获序列中的时间依赖关系。下面我们将详细解释其工作机制。
RNN的一个重要特点是可以通过时间展开来理解。这意味着,虽然网络结构在每个时间步看起来相同,但我们可以将其展开为一系列的网络层,每一层对应于序列中的一个特定时间步。
RNN可以通过下列数学方程描述:
其中,( \sigma ) 是一个激活函数(如tanh或ReLU),( h_t ) 是当前隐藏状态,( x_t ) 是当前输入,( y_t ) 是当前输出。权重和偏置分别由( W_{hh}, W_{ih}, W_{ho} ) 和 ( b_h, b_o ) 表示。
输入到隐藏:每个时间步,RNN从输入层接收一个新的输入,并将其与之前的隐藏状态结合起来,以生成新的隐藏状态。
隐藏到隐藏:隐藏层之间的循环连接使得信息可以在时间步之间传播,从而捕捉序列中的依赖关系。
隐藏到输出:每个时间步的隐藏状态都会传递到输出层,以生成对应的输出。
# RNN的PyTorch实现
import torch.nn as nn
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, h_0):
out, h_n = self.rnn(x, h_0) # 运用RNN层
out = self.fc(out) # 运用全连接层
return out
复制由于RNN的循环结构,在训练中可能会出现梯度消失或梯度爆炸的问题。长序列可能会导致训练过程中的梯度变得非常小(消失)或非常大(爆炸),从而影响模型的学习效率。
循环神经网络的工作原理强调了序列数据的时间依赖关系。通过时间展开和信息的连续流动,RNN能够理解和处理序列中的复杂模式。不过,RNN的训练可能受到梯度消失或爆炸的挑战,需要采用适当的技术和结构来克服。
循环神经网络(RNN)因其在捕获序列数据中的时序依赖性方面的优势,在许多应用场景中都得到了广泛的使用。以下是一些主要应用领域的概述:
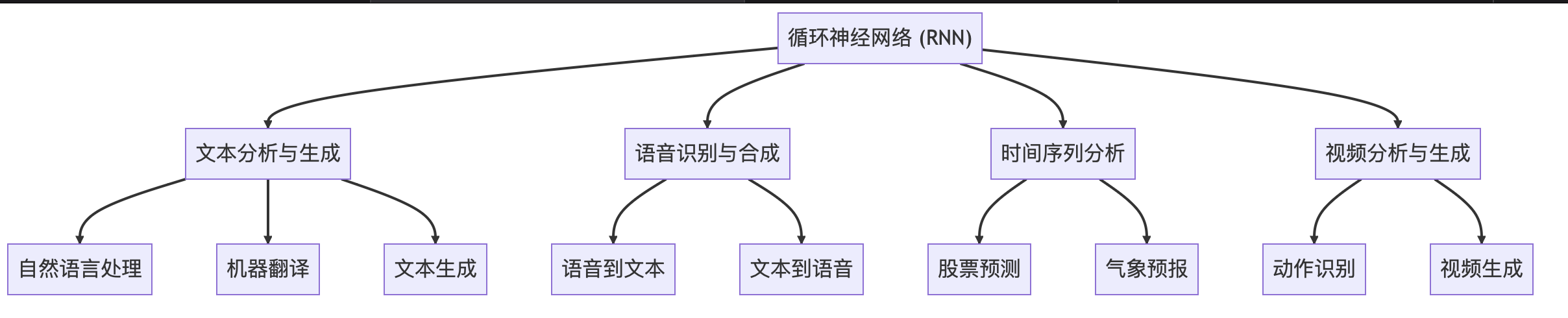
RNN可用于词性标注、命名实体识别、句子解析等任务。通过捕获文本中的上下文关系,RNN能够理解并处理语言的复杂结构。
RNN能够理解和生成不同语言的句子结构,使其在机器翻译方面特别有效。
利用RNN进行文本生成,如生成诗歌、故事等,实现了机器的创造性写作。
RNN可以用于将语音信号转换为文字,即语音识别(Speech to Text),理解声音中的时序依赖关系。
RNN也用于文本到语音(Text to Speech)的转换,生成流畅自然的语音。
通过分析历史股票价格和交易量等数据的时间序列,RNN可以用于预测未来的股票走势。
RNN通过分析气象数据的时间序列,可以预测未来的天气情况。
RNN能够分析视频中的时序信息,用于识别人物动作和行为模式等。
RNN还可以用于视频内容的生成,如生成具有连续逻辑的动画片段。
RNN的这些应用场景共同反映了其在理解和处理具有时序依赖关系的序列数据方面的强大能力。无论是自然语言处理、语音识别、时间序列分析,还是视频内容分析,RNN都已成为实现这些任务的重要工具。其在捕获长期依赖、理解复杂结构和生成连续序列方面的特性,使其成为深度学习中处理序列问题的首选方法。
长短时记忆网络(Long Short-Term Memory,LSTM)是一种特殊的RNN结构,由Hochreiter和Schmidhuber在1997年提出。LSTM旨在解决传统RNN在训练长序列时遇到的梯度消失问题。
LSTM的核心是其复杂的记忆单元结构,包括以下组件:
控制哪些信息从单元状态中被丢弃。
控制新信息的哪些部分要存储在单元状态中。
储存过去的信息,通过遗忘门和输入门的调节进行更新。
控制单元状态的哪些部分要读取和输出。
LSTM的工作过程可以通过以下方程表示:
遗忘门:
[ f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) ]
输入门:
[ i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) ]
候选单元状态:
[ \tilde{C}t = \text{tanh}(W_C \cdot [h, x_t] + b_C) ]
更新单元状态:
[ C_t = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}_t ]
输出门:
[ o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) ]
隐藏状态:
[ h_t = o_t \cdot \text{tanh}(C_t) ]
其中,( \sigma ) 表示sigmoid激活函数。
# LSTM的PyTorch实现
import torch.nn as nn
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(LSTM, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, (h_0, c_0)):
out, (h_n, c_n) = self.lstm(x, (h_0, c_0)) # 运用LSTM层
out = self.fc(out) # 运用全连接层
return out
复制LSTM通过引入复杂的门控机制解决了梯度消失的问题,使其能够捕获更长的序列依赖关系。然而,LSTM的复杂结构也使其在计算和参数方面相对昂贵。
长短时记忆网络(LSTM)是循环神经网络的重要扩展,具有捕获长序列依赖关系的能力。通过引入门控机制,LSTM可以精细控制信息的流动,既能记住长期的依赖信息,也能忘记无关的细节。这些特性使LSTM在许多序列处理任务中都得到了广泛的应用。
门控循环单元(Gated Recurrent Unit,GRU)是一种特殊的RNN结构,由Cho等人于2014年提出。GRU与LSTM相似,但其结构更简单,计算效率更高。
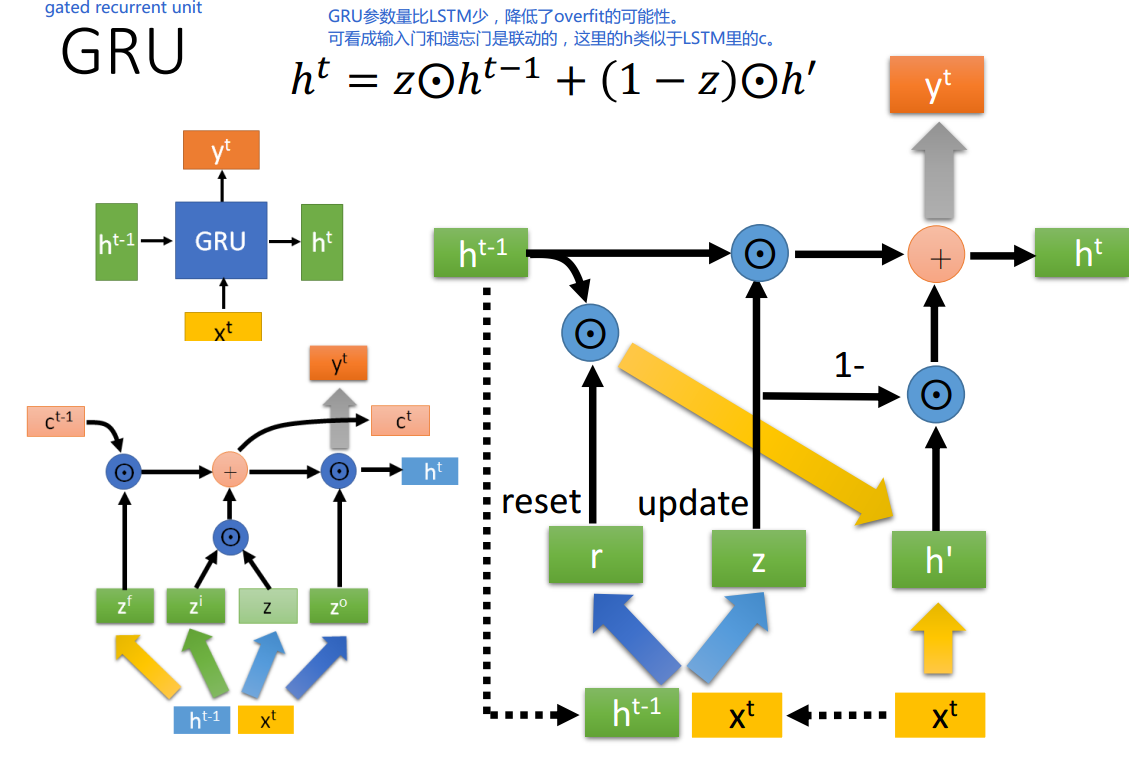
GRU通过将忘记和输入门合并,减少了LSTM的复杂性。GRU的结构主要由以下组件构成:
控制过去的隐藏状态的哪些信息应该被忽略。
控制隐藏状态的哪些部分应该被更新。
计算新的候选隐藏状态,可能会与当前隐藏状态结合。
GRU的工作过程可以通过以下方程表示:
重置门:
[ r_t = \sigma(W_r \cdot [h_{t-1}, x_t] + b_r) ]
更新门:
[ z_t = \sigma(W_z \cdot [h_{t-1}, x_t] + b_z) ]
新的记忆内容:
[ \tilde{h}t = \text{tanh}(W \cdot [r_t \odot h, x_t] + b) ]
最终隐藏状态:
[ h_t = (1 - z_t) \cdot h_{t-1} + z_t \cdot \tilde{h}_t ]
其中,( \sigma ) 表示sigmoid激活函数,( \odot ) 表示逐元素乘法。
# GRU的PyTorch实现
import torch.nn as nn
class GRU(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(GRU, self).__init__()
self.gru = nn.GRU(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, h_0):
out, h_n = self.gru(x, h_0) # 运用GRU层
out = self.fc(out) # 运用全连接层
return out
复制GRU提供了与LSTM类似的性能,但结构更简单,因此在计算和参数方面相对更有效率。然而,这种简化可能会在某些任务中牺牲一些表现力。
门控循环单元(GRU)是一种有效的RNN结构,旨在捕获序列数据中的时序依赖关系。与LSTM相比,GRU具有更高的计算效率,同时仍保持了良好的性能。其在许多序列处理任务中的应用,如自然语言处理、语音识别等,进一步证明了其作为一种重要的深度学习工具的地位。
双向循环神经网络(Bidirectional Recurrent Neural Network,Bi-RNN)是一种能够捕获序列数据前后依赖关系的RNN架构。通过结合正向和反向的信息流,Bi-RNN可以更全面地理解序列中的模式。
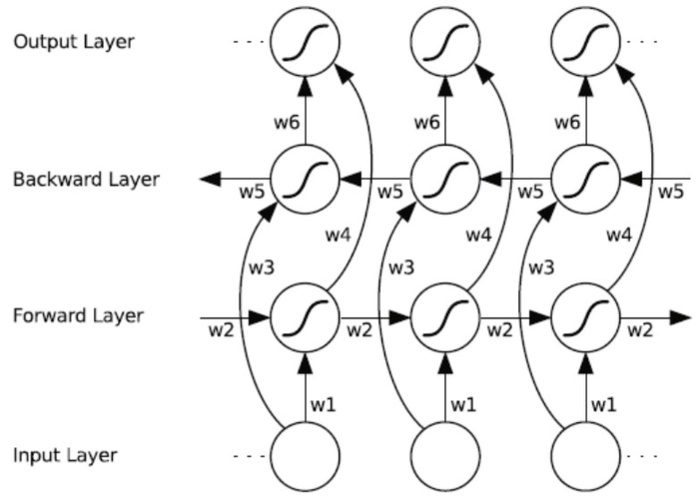
Bi-RNN由两个独立的RNN层组成,一个正向层和一个反向层。这两个层分别处理输入序列的正向和反向版本。
处理输入序列从第一个元素到最后一个元素。
处理输入序列从最后一个元素到第一个元素。
正向和反向层的隐藏状态通常通过连接或其他合并方式结合在一起,以形成最终的隐藏状态。
以下代码展示了使用PyTorch构建Bi-RNN的方法:
# Bi-RNN的PyTorch实现
import torch.nn as nn
class BiRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(BiRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True, bidirectional=True)
self.fc = nn.Linear(hidden_size * 2, output_size)
def forward(self, x):
out, _ = self.rnn(x) # 运用双向RNN层
out = self.fc(out) # 运用全连接层
return out
复制Bi-RNN在许多涉及序列分析的任务中非常有效,例如:
Bi-RNN可以与其他RNN结构(例如LSTM和GRU)相结合,进一步增强其能力。
双向循环神经网络(Bi-RNN)通过同时分析序列的前向和反向信息,实现了对序列数据更深入的理解。其在诸如自然语言处理和语音识别等复杂任务中的成功应用,显示了Bi-RNN作为一种强大的深度学习模型的潜力和灵活性。
为了成功实现循环神经网络,需要首先准备开发环境,并对数据进行适当的预处理。下面将详细介绍每个阶段的步骤。
环境准备主要包括选择合适的编程语言、深度学习框架、硬件环境等。
# 安装PyTorch
!pip install torch torchvision
复制数据预处理是机器学习项目中的关键步骤,可以显著影响模型的性能。
以下是数据预处理的示例代码:
# 用于数据预处理的PyTorch代码
from torch.utils.data import DataLoader
from torchvision import transforms
# 定义转换
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5]),
])
# 加载数据集
train_dataset = CustomDataset(transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
复制环境准备和数据预处理是循环神经网络实现过程中的基础阶段。选择合适的工具和硬件,并对数据进行适当的清洗和转换,是确保项目成功的关键。与此同时,使用合适的数据预处理技术可以显著提高模型的性能和稳定性。通过本节的介绍,读者应能够理解并实现循环神经网络所需的环境准备和数据预处理步骤。
PyTorch是一种流行的深度学习框架,广泛用于构建和训练神经网络模型。在本节中,我们将介绍如何使用PyTorch构建基本的RNN模型。
RNN模型由输入层、隐藏层和输出层组成。以下是构建RNN的代码示例:
import torch.nn as nn
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.rnn(x)
out = self.fc(out)
return out
复制这里,input_size表示输入特征的数量,hidden_size表示隐藏层神经元的数量,output_size表示输出层神经元的数量。
初始化模型涉及设置其参数和选择优化器与损失函数。
model = SimpleRNN(input_size=10, hidden_size=20, output_size=1)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.MSELoss()
复制训练模型包括以下步骤:
# 训练循环示例
for epoch in range(epochs):
for batch in train_loader:
inputs, targets = batch
outputs = model(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
复制通过在验证集或测试集上评估模型,您可以了解其泛化性能。一旦满意,可以保存模型供以后使用。
# 保存模型
torch.save(model.state_dict(), 'model.pth')
复制使用PyTorch构建RNN模型涉及多个步骤,包括定义模型结构、初始化、训练和评估。本节通过详细的代码示例和解释为读者提供了一个全面的指南,可以用来构建自己的RNN模型。在理解了基本的RNN之后,读者还可以进一步探索更复杂的变体,如LSTM、GRU和双向RNN。

训练和评估模型是深度学习工作流程的核心部分。本节将详细介绍如何使用PyTorch进行RNN模型的训练和评估。
训练循环是重复的过程,包括前向传播、损失计算、反向传播和优化权重。以下是典型的训练循环代码:
for epoch in range(epochs):
for batch in train_loader:
inputs, targets = batch
outputs = model(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {epoch + 1}/{epochs}, Loss: {loss.item()}')
复制通常使用验证集监控模型的训练进度,并使用如TensorBoard等工具可视化训练和验证损失。
在验证集上评估模型可以了解模型在未见过的数据上的性能。
model.eval()
with torch.no_grad():
for batch in val_loader:
inputs, targets = batch
outputs = model(inputs)
val_loss += criterion(outputs, targets).item()
print(f'Validation Loss: {val_loss/len(val_loader)}')
复制在测试集上的评估为您提供了模型在实际应用场景下可能的性能。
除了损失外,还可以计算其他重要指标,例如准确率、精确度、召回率等。
超参数调优涉及使用诸如Grid Search或Random Search的技术来找到最佳超参数组合。
训练和评估模型是深度学习项目的核心阶段。本节详细介绍了如何使用PyTorch进行训练循环、监控训练进度、评估模型、计算性能指标以及超参数调优。通过了解这些关键概念和技术,读者可以有效地训练和评估RNN模型,为实际应用做好准备。

在本系列博客中,我们详细探讨了循环神经网络(RNN)的各个方面。以下是重要内容的总结:
我们介绍了RNN的基本结构和工作原理,以及它如何捕捉序列数据中的时间依赖关系。然后,我们深入了解了各种RNN的应用场景,涵盖了自然语言处理、时间序列分析等领域。
通过深入了解RNN及其变体、理解它们的工作原理、掌握使用PyTorch进行实现的技巧,读者可以充分利用RNN在复杂序列数据分析方面的强大功能。这种知识不仅可用于当前的项目,还为未来的研究和开发工作奠定了坚实的基础。循环神经网络是深度学习中的一个重要分支,通过不断探索和学习,我们可以继续推动这一领域的创新和进展。
作者 TechLead,拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
如有帮助,请多关注
个人微信公众号:【TechLead】分享AI与云服务研发的全维度知识,谈谈我作为TechLead对技术的独特洞察。
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。