博客地址:https://www.cnblogs.com/zylyehuo/
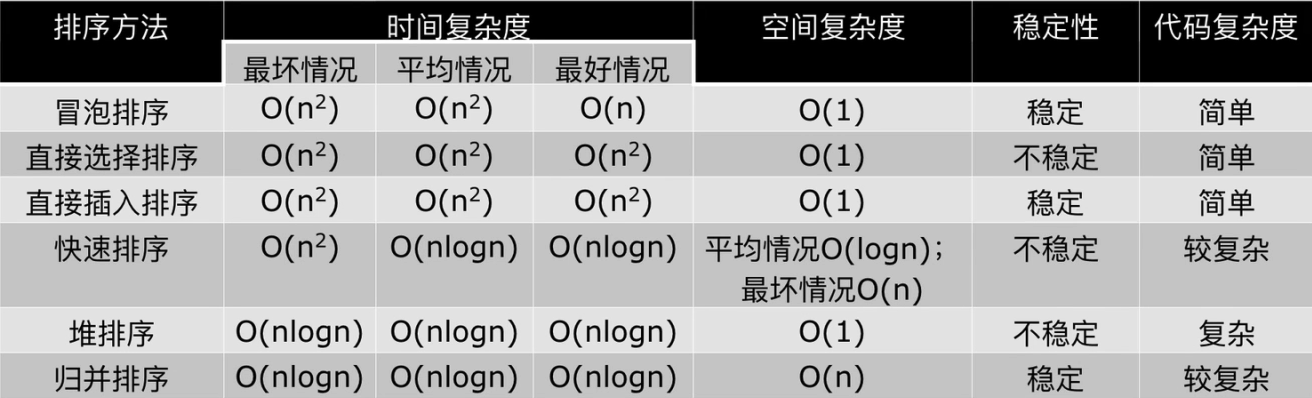
希尔排序:时间复杂度与选取的gap序列有关 计数排序: 时间复杂度:O(n) 桶排序: 时间复杂度:O(n+k) 最坏时间复杂度:O(n²k) 空间复杂度:O(nk) 基数排序: 时间复杂度:O(kn) 空间复杂度:O(k+n) 复制
希尔排序:时间复杂度与选取的gap序列有关 计数排序: 时间复杂度:O(n) 桶排序: 时间复杂度:O(n+k) 最坏时间复杂度:O(n²k) 空间复杂度:O(nk) 基数排序: 时间复杂度:O(kn) 空间复杂度:O(k+n)
博客地址:https://www.cnblogs.com/zylyehuo/ 希尔排序:时间复杂度与选取的gap序列有关 计数排序: 时间复杂度:O(n) 桶排序: 时间复杂度:O(n+k) 最坏时间复杂度:O(n²k) 空间复杂度:O(nk) 基数排序: 时间复杂度:O(kn) 空间复杂度:O(k
前言 归并排序是一种常见的排序算法,它采用分治法的思想,在排序过程中不断将待排序序列分割成更小的子序列,直到每个子序列中只剩下一个元素,然后将这些子序列两两合并并排序,最终得到一个有序的序列。 归并排序实现原理 将待排序序列分割成两个子序列,直到每个子序列中只有一个元素。 将相邻的两个子序列合并,并
摘要:归并排序和快速排序是两种稍微复杂的排序算法,它们用的都是分治的思想,代码都通过递归来实现,过程非常相似。理解归并排序的重点是理解递推公式和 merge() 合并函数。 本文分享自华为云社区《深入浅出八种排序算法》,作者:嵌入式视觉 。 归并排序和快速排序是两种稍微复杂的排序算法,它们用的都是分
快速排序实现原理 快速排序(Quick Sort)是一种常用的排序算法,它基于分治的思想,通过将一个无序的序列分割成两个子序列,并递归地对子序列进行排序,最终完成整个序列的排序。 其基本思路如下: 选择数组中的一个元素作为基准(pivot)。 将数组中小于等于基准的元素放在基准的左边,将大于基准的元
大家好,我是蓝胖子,我一直相信编程是一门实践性的技术,其中算法也不例外,初学者可能往往对它可望而不可及,觉得很难,学了又忘,忘其实是由于没有真正搞懂算法的应用场景,所以我准备出一个系列,囊括我们在日常开发中常用的算法,并结合实际的应用场景,真正的感受算法的魅力。 代码已经上传github https
C++ STL(Standard Template Library)是C++标准库中的一个重要组成部分,提供了丰富的模板函数和容器,用于处理各种数据结构和算法。在STL中,排序、算数和集合算法是常用的功能,可以帮助我们对数据进行排序、统计、查找以及集合操作等。STL提供的这些算法,能够满足各种数据处理和分析的需求。通过灵活使用这些算法,我们可以高效地对数据进行排序、查找和聚合操作,提高代码的性能和
AI学习过程中,常见的名词解析 ### 中位数 将数据从小到大排序,奇数列,取中间值,偶数列,中间两个值的平均,可做为销售指标 ### 众数 一组数据中,数值出现最多的那个。反映哪款产品,销量最好 ### 平均数 比赛中,去掉最高、最低分,然后以平均数做为选手的最终得分 ### 损失函数(loss
theme: channing-cyan 本文正在参与 “走过Linux 三十年”话题征文活动 在Linux系统上,最常见的操作莫过于处理文本。常见文件操作陈列、查找、排序、格式转换、数据流处理等等。这篇文章着眼于文件查找,分析locate和find命令的使用方法,和运用原理以及缺陷不足。 一、导读
https://tidb.net/blog/0c5b6025 1.1. 字符集与编码规则 字符集(character set)即为众多字符的集合。字符集为每个字符分配一个唯一的 ID,称为 “Code Point(码点)”。编码规则是将 Code Point 转换为 0、 1 二进制序列的规则。通俗
在RabbitMQ 3.7.9版本中,Create Channel超时的常见原因及排查方法如下: 常见原因 网络问题: 网络延迟或不稳定可能导致通信超时。 网络分区(network partition)可能导致部分节点无法访问。 资源限制: RabbitMQ服务器上的文件描述符或句柄数量限制。 服务