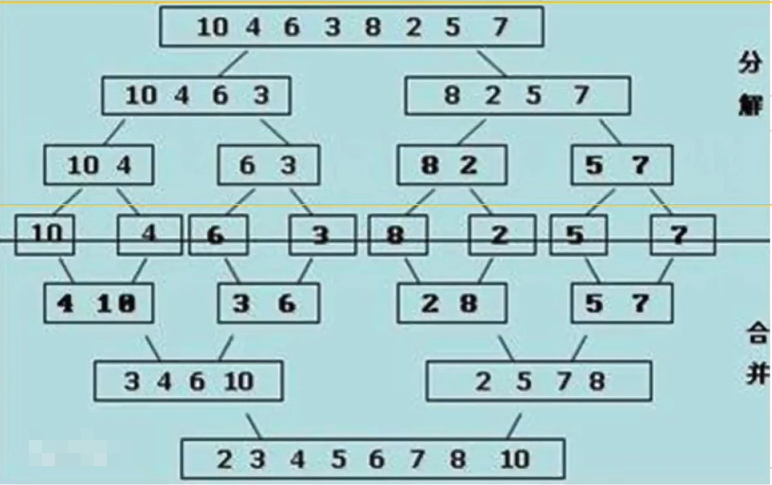
递归思路
# _*_coding:utf-8_*_
import random
def merge(li, low, mid, high):
i = low
j = mid + 1
ltmp = []
while i <= mid and j <= high: # 只要左右两边都有数
if li[i] < li[j]:
ltmp.append(li[i])
i += 1
else:
ltmp.append(li[j])
j += 1
# while执行完,肯定有一部分没数了
while i <= mid:
ltmp.append(li[i])
i += 1
while j <= high:
ltmp.append(li[j])
j += 1
li[low:high + 1] = ltmp
def merge_sort(li, low, high):
if low < high: # 至少有两个元素,递归
mid = (low + high) // 2
merge_sort(li, low, mid)
merge_sort(li, mid + 1, high)
merge(li, low, mid, high)
li = list(range(10))
random.shuffle(li)
print(li)
merge_sort(li, 0, len(li) - 1)
print(li)
复制