本文已收录到 GitHub · AndroidFamily,有 Android 进阶知识体系,欢迎 Star。技术和职场问题,请关注公众号 [彭旭锐] 私信我提问。
大家好,我是小彭。
今天分享到的是一种相对冷门的数据结构 —— 并查集。虽然冷门,但是它背后体现的算法思想却非常精妙,在处理特定问题上能做到出奇制胜。那么,并查集是用来解决什么问题的呢?
学习路线图:
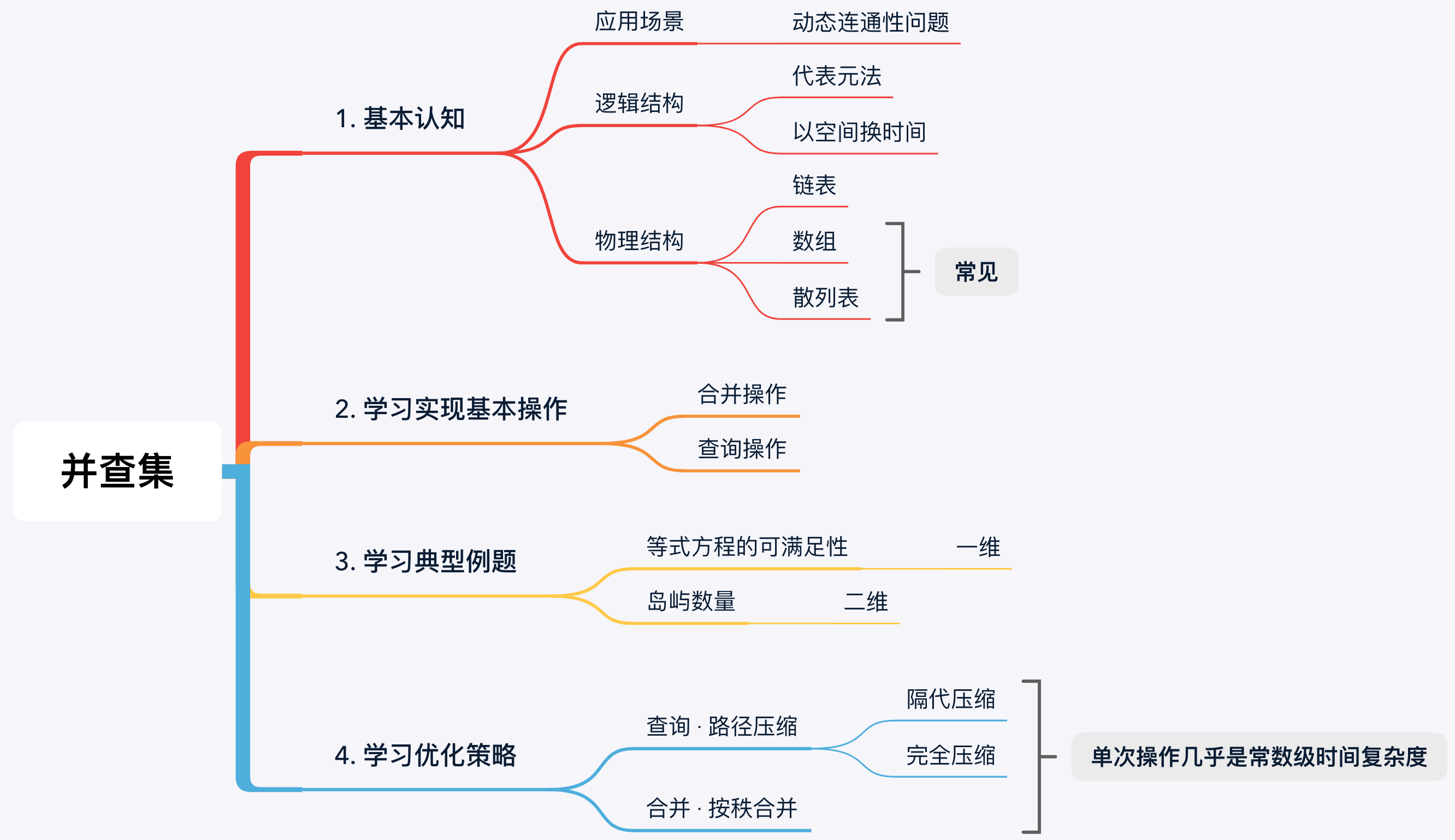
除了并查集之外,不相交集合(Disjoint Sets)、合并-查找集合(Merge-find Set)、联合-查询数据结构(Union-find Data Structure)、联合-查询算法(Union-find algorithm),均表示相同的数据结构或思想。
并查集是一种用来高效地判断 “动态连通性 ” 的数据结构: 即给定一个无向图,要求判断某两个元素之间是否存在相连的路径(连通),这就是连通问题,也叫 “朋友圈” 问题。听起来有点懵,你先别着急哈,咱来一点一点地把这个知识体系建立起来。
先举个例子,给定一系列航班信息,问是否存在 “北京” 到 “广州” 的路径,这就是连通性问题。而如果是问 “北京” 到 “广州” 的最短路径,这就是路径问题。并查集是专注于解决连通性问题的数据结构,而不关心元素之间的路径与距离,所以最短路径等问题就超出了并查集的能够处理的范围,不是它考虑的问题。
连通问题与路径问题示意图
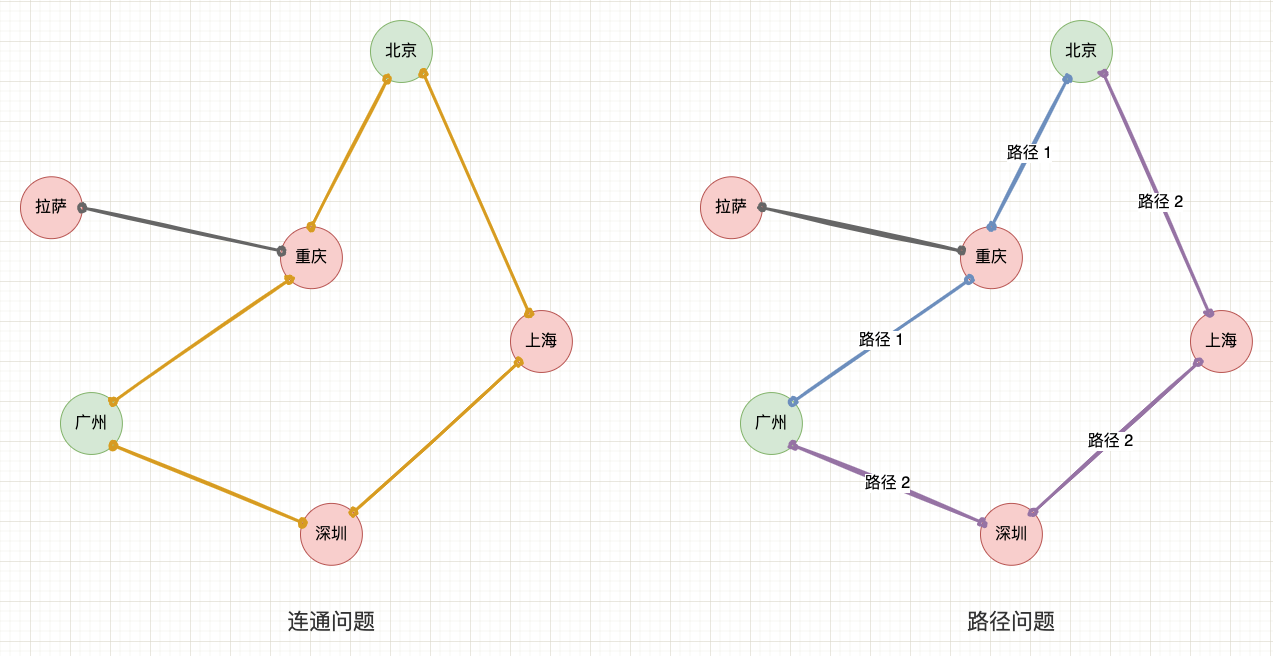
另一个关键点是,并查集也非常适合处理动态数据的连通性问题。 因为在完成旧数据的处理后,旧数据的连通关系是记录在并查集中的。即使后续动态增加新的数据,也不需要重新检索整个数据集,只需要将新数据提供的信息补充到并查集中,这带有空间换时间的思想。
动态连通问题

理解了并查集的应用场景后,下面讨论并查集是如何解决连通性的问题。
既然要解决连通性问题,那么在并查集的逻辑结构里,就必须用某种方式体现出两个元素或者一堆元素之间的连接关系。那它是怎么体现的呢 —— 代表元法。
并查集使用 “代表元法” 来表示元素之间的连接关系:将相互连通的元素组成一个子集,并从中选取一个元素作为代表元。而判断两个元素之间是否连通,就是判断它们的代表元是否相同,代表元相同则说明处于相同子集,代表元不同则说明处于不同的子集。
例如,我们将航班信息构建为并查集的数据结构后,就有 “重庆” 和 “北京” 两个子集。此时,问是否存在 “北京” 到 “广州” 的路径,就是看 “北京” 和 “广州” 的代表元是否相同。可见它们的代表元是相同的,因此它们是连通的。
并查集的逻辑结构和物理结构

理解了并查集的逻辑结构后,下面讨论如何用代码实现并查集。
并查集的物理结构可以是数组,亦可以是链表,只要能够体现节点之间连接关系即可。
数组实现相对于链表实现更加常见,另外,在数组的基础上还衍生出散列表的实现,关键看元素个数是否固定。例如:
提示: 我们这里将父节点指向节点本身定义为根节点,也有题解将父节点指向
null或者-1的节点定义为根节点。两种方法都可以,只要能够区分出普通节点和根节点。但是指向节点本身的写法更简洁,不需要担心Union(x, x)出现死循环。
以下为基于数组和基于散列表的代码模板:
基于数组的并查集
// 数组实现适合元素个数固定的场景
class UnionFind(n: Int) {
// 创建一个长度为 n 的数组,每个位置上的值初始化数组下标,表示初始化时有 n 个子集
private val parent = IntArray(n) { it }
...
}
复制基于散列表的并查集
// 散列表实现适合元素个数不固定的场景
class UnionFind() {
// 创建一个空散列表,
private val parent = HashMap<Int, Int>()
// 查询操作
fun find(x: Int): Int {
// 1. parent[x] 为 null 表示首次查询,先加入散列表中并指向自身
if (null == parent[x]) {
parent[x] = x
return x
}
// 下文说明查询操作细节...
}
}
复制“并查集,并查集”,顾名思义并查集就是由 “并” 和 “查” 这两个最基本的操作组成的:
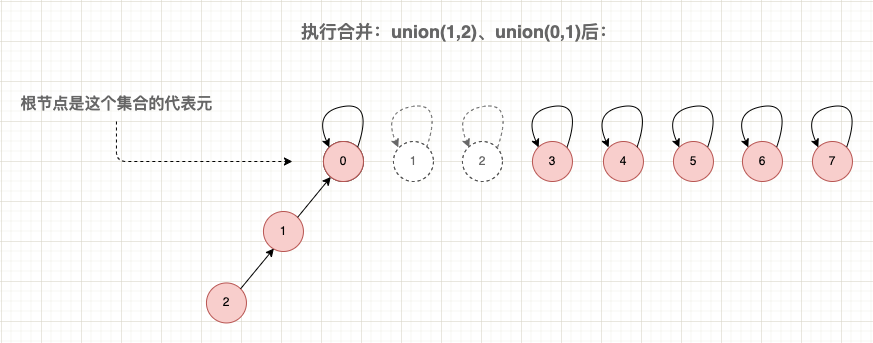
例如,以下是一个基于数组的并查集实现,其中使用 Find(x) 查询元素的根节点使用 Union(x, y) 合并两个元素的根节点:
基于数组的并查集
class UnionFind(n: Int) {
// 创建一个长度为 n 的数组,每个位置上的值初始化数组下标,表示初始化时有 n 个子集
val parent = IntArray(n) { it }
// 查询操作(遍历写法)
fun find(x: Int): Int {
var key = x
while (key != parent[key]) {
key = parent[key]
}
return key
}
// 合并操作
fun union(x: Int, y: Int) {
// 1. 分别找出两个元素的根节点
val rootX = find(x)
val rootY = find(y)
// 2. 任意选择其中一个根节点成为另一个根节点的子树
parent[rootY] = rootX
}
// 判断连通性
fun isConnected(x: Int, y: Int): Boolean {
// 判断根节点是否相同
return find(x) == find(y)
}
// 查询操作(递归写法)
fun find(x: Int): Int {
var key = x
if (key != parent[key]) {
return find(parent[key])
}
return key
}
}
复制合并与查询示意图
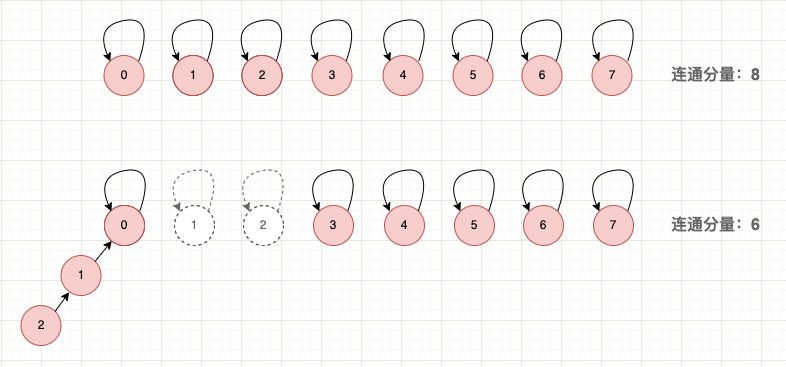
并查集的连通分量,表示的是整个并查集中独立的子集个数,也就是森林中树的个数。要计算并查集的连通分量,其实就是在合并操作中维护连通分量的计数,在合并子集后将计数减一。
class UnionFind(n: Int) {
private val parent = IntArray(n) { it }
// 连通分量计数,初始值为元素个数 n
var count = n
// 合并操作
fun union(x: Int, y: Int) {
val rootX = find(x)
val rootY = find(y)
if(rootX == rootY){
// 未发生合并,则不需要减一
return
}
// 合并后,连通分量减一
parent[rootY] = rootX
count --
}
...
}
复制连通分量示意图
理解以上概念后,就已经具备解决连通问题的必要知识了。我们看一道 LeetCode 上的典型例题: LeetCode · 990.
LeetCode 例题
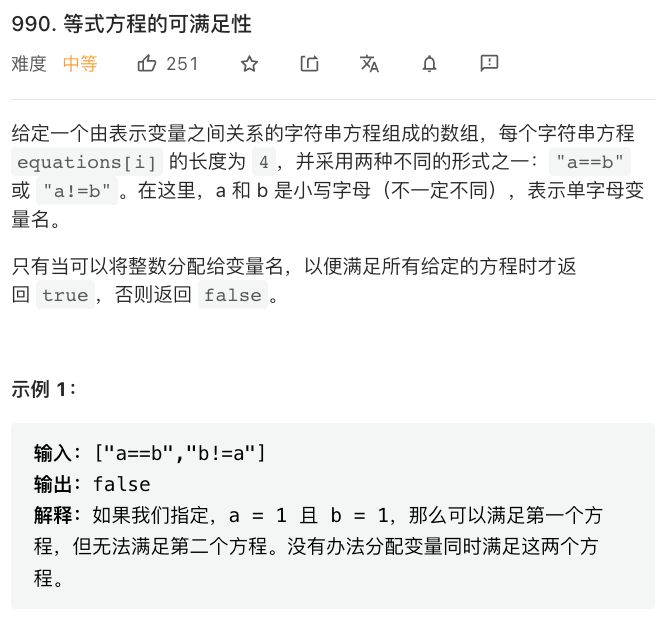
我们可以把每个变量看作一个节点,而等式表示两个节点相连,不等式则表示两个节点不相连。那么,我们可以分 2 步:
—— 图片引用自 LeetCode 官方题解
题解示例如下:
题解
// 未优化版本
class Solution {
fun equationsPossible(equations: Array<String>): Boolean {
// 26 个小写字母的并查集
val unionFind = UnionFind(26)
// 合并所有等式
for (equation in equations.filter { it[1] == '=' }) {
unionFind.union(equation.first(), equation.second())
}
// 检查不等式是否与连通性冲突
for (equation in equations.filter { it[1] == '!' }) {
if (unionFind.isConnected(equation.first(), equation.second())) {
return false
}
}
return true
}
private fun String.first(): Int {
return this[0].toInt() - 97
}
private fun String.second(): Int {
return this[3].toInt() - 97
}
private class UnionFind() {
// 代码略
}
}
复制前面说到并查集逻辑上是一种基于森林的数据结构。既然与树有关,我们自然能想到它的复杂度就与树的高度有关。在极端条件下(按照特殊的合并顺序),有可能出现树的高度恰好等于元素个数 n 的情况,此时,单次 Find 查询操作的时间复杂度就退化到 $O(n)$。
那有没有优化的办法呢?
在介绍具体的优化方法前,我先提出来一个问题:在已经选定集合的代表元后,一个元素的父节点是谁还重要吗?答案是不重要。
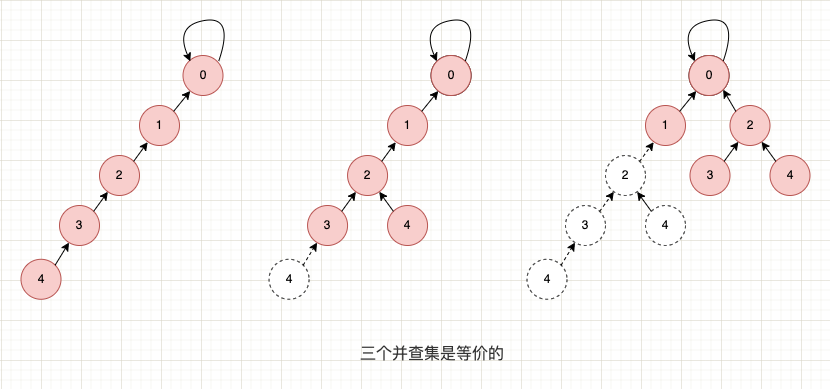
因为无论父节点是谁,最终都是去找根节点的。至于中间是经过哪些节点到达根节点的,这个并不重要。举个例子,以下 3 个并查集是完全等价的,但明显第 3 个并查集中树的高度更低,查询的时间复杂度更好。
父节点并不重要
理解了这个点之后,再理解并查集的优化策略就容易了。在并查集里,有 2 种防止链表化的优化策略 —— 路径压缩 & 按秩合并。
路径压缩指在查询的过程中,逐渐调整父节点的指向,使其指向更高层的节点,使得很多深层的阶段逐渐放到更靠近根节点的位置。 根据调整的激进程度又分为 2 种:
路径压缩示意图
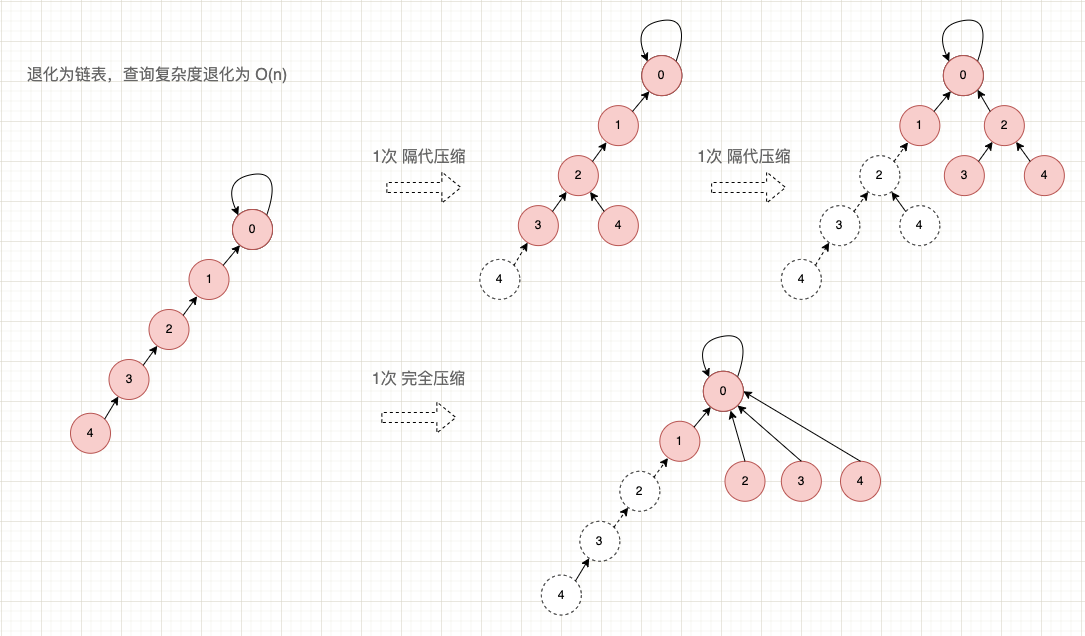
路径压缩示例程序
// 遍历写法
fun find(x: Int): Int {
var key = x
while (key != parent[key]) {
parent[key] = parent[parent[key]]
key = parent[key]
}
return key
}
// 递归写法
fun find(x: Int): Int {
var key = x
if (key != parent[key]) {
parent[key] = find(parent[key])
return parent[key]
}
return key
}
复制在 第 2.1 节 提到合并操作时,我们采取的合并操作是相对随意的。我们在合并时会任意选择其中一个根节点成为另一个根节点的子树,这就有可能让一棵较大子树成为较小子树的子树,使得树的高度增加。
而按秩合并就是要打破这种随意性,在合并的过程中让较小的子树成为较大子树的子树,避免合并以后树的高度增加。 为了表示树的高度,需要维护使用 rank 数组,记录根节点对应的高度。
按秩合并示意图

按秩合并示例程序
private class UnionFind(n: Int) {
// 父节点
private val parent = IntArray(n) { it }
// 节点的高度
private val rank = IntArray(n) { 1 }
// 连通分量
var count = n
private set
// 查询(路径压缩)
fun find(x: Int): Int {
var key = x
while (key != parent[key]) {
parent[key] = parent[parent[key]]
key = parent[key]
}
return key
}
// 合并(按秩合并)
fun union(key1: Int, key2: Int) {
val root1 = find(key1)
val root2 = find(key2)
if (root1 == root2) {
return
}
if (rank[root1] > rank[root2]) {
// root1 的高度更大,让 root2 成为子树,树的高度不变
parent[root2] = root1
} else if (rank[root2] > rank[root1]) {
// root2 的高度更大,让 root1 成为子树,树的高度不变
parent[root1] = root2
} else {
// 高度相同,谁当子树都一样
parent[root1] = root2
// root2 的高度加一
rank[root2]++
// 或
// parent[root2] = root1
// rank[root1] ++
}
count--
}
}
复制在同时使用路径压缩和按秩合并两种优化策略时,单次合并操作或查询操作的时间复杂度几乎是常量,整体的时间复杂度几乎是线性的。
以对 N 个元素进行 N - 1 次合并和 M 次查询的操作序列为例,单次操作的时间复杂度是 $O(a(N))$,而整体的时间复杂度是 $O(M·a(N))$。其中 $a(x)$ 是逆阿克曼函数,是一个增长非常非常慢的函数,只有使用那些非常大的 “天文数字” 作为变量 $x$,否则 $a(x)$ 的取值都不会超过 4,基本上可以当作常数。
然而,逆阿克曼函数毕竟不是常数,因此我们不能说并查集的时间复杂度是线性的,但也几乎是线性的。关于并查集时间复杂度的论证过程,具体可以看参考资料中的两本算法书籍,我是看不懂的。
前面我们讲的是一维的连通性问题,那么在二维世界里的连通性问题,并查集还依旧好用吗?我们看 LeetCode 上的另一道典型例题: LeetCode · 200.
LeetCode 例题

这个问题直接上 DFS 广度搜索自然是可以的:遍历二维数组,每找到 1 后使用 DFS 遍历将所有相连的 1 消除为 0,直到整块相连的岛屿都消除掉,记录岛屿数 +1。最后,输出岛屿数。
用并查集的来解的话,关键技巧就是建立长度为 M * N 的并查集:遍历二维数组,每找到 1 后,将它与右边和下边的 1 合并起来,最终输出并查集中连通分量的个数,就是岛屿树。
并查集解法
class Solution {
fun numIslands(grid: Array<CharArray>): Int {
// 位置
fun position(row: Int, column: Int) = row * grid[0].size + column
// 并查集
val unionFind = UnionFind(grid)
// 偏移量数组(向右和向下)
val directions = arrayOf(intArrayOf(0, 1), intArrayOf(1, 0))
// 边界检查
fun checkBound(row: Int, column: Int): Boolean {
return (row in grid.indices) and (column in grid[0].indices)
}
for (row in grid.indices) {
for (column in grid[0].indices) {
if ('1' == grid[row][column]) {
// 消费(避免后续的遍历中重复搜索)
grid[row][column] = '0'
for (direction in directions) {
val newRow = row + direction[0]
val newColumn = column + direction[1]
if (checkBound(newRow, newColumn) && '1' == grid[newRow][newColumn]) {
unionFind.union(position(newRow, newColumn), position(row, column))
}
}
}
}
}
return unionFind.count
}
private class UnionFind(grid: Array<CharArray>) {
// 父节点
private val parent = IntArray(grid.size * grid[0].size) { it }
// 节点高度
private val rank = IntArray(grid.size * grid[0].size) { 1 }
// 连通分量(取格子 1 的总数)
var count = grid.let {
var countOf1 = 0
for (row in grid.indices) {
for (column in grid[0].indices) {
if ('1' == grid[row][column]) countOf1++
}
}
countOf1
}
private set
// 合并(按秩合并)
fun union(key1: Int, key2: Int) {
val root1 = find(key1)
val root2 = find(key2)
if (root1 == root2) {
// 未发生合并,则不需要减一
return
}
if (rank[root1] > rank[root2]) {
parent[root2] = root1
} else if (rank[root2] > rank[root1]) {
parent[root1] = root2
} else {
parent[root1] = root2
rank[root2]++
}
// 合并后,连通分量减一
count--
}
// 查询(使用路径压缩)
fun find(x: Int): Int {
var key = x
while (key != parent[key]) {
parent[key] = parent[parent[key]]
key = parent[key]
}
return key
}
}
}
复制到这里,并查集的内容就讲完了。文章开头也提到了,并查集并不算面试中的高频题目,但是它的设计思想确实非常妙。不知道你有没有这种经历,在看到一种非常美妙的解题 / 设计思想后,会不自觉地拍案叫绝,直呼内行,并查集就是这种。
更多同类型题目:
| 并查集 | 题解 |
|---|---|
| 990. 等式方程的可满足性 | 【题解】 |
| 200. 岛屿数量 | 【题解】 |
| 547. 省份数量 | 【题解】 |
| 684. 冗余连接 | 【题解】 |
| 685. 冗余连接 II | |
| 1319. 连通网络的操作次数 | 【题解】 |
| 399. 除法求值 | |
| 952. 按公因数计算最大组件大小 | |
| 130. 被围绕的区域 | |
| 128. 最长连续序列 | |
| 721. 账户合并 | |
| 765. 情侣牵手 |