本文已收录到 AndroidFamily,技术和职场问题,请关注公众号 [彭旭锐] 提问。
大家好,我是小彭。
Gson 是 Google 推出的 Java Json 解析库,具有接入成本低、使用便捷、功能扩展性良好等优点,想必大家都很熟悉了。在这篇文章里,我们将讨论 Gson 的基本用法和以及主要流程的源码分析。
小彭的 Android 交流群 02 群已经建立啦,扫描文末二维码进入~
学习路线图:
Gradle 依赖
dependencies { implementation 'com.google.code.gson:gson:2.10' }复制
Gson 类是整个库的核心 API,在进行任何序列化或反序列化之前,我们都需要获得一个 Gson 对象。可以直接 new 创建默认配置的 Gson 对象,也可以使用 GsonBuilder 构造者配置 Gson 对象。
事实上,一个 Gson 对象代表一个 Gson 工作环境,不同 Gson 对象之间的配置和缓存都不会复用。 因此,在项目中有必要在 common 层提供一个全局的 Gson 对象,既有利于统一序列化配置,也是 Gson 性能优化的基本保障。
GsonBuilder 使用示例
Gson gson = new GsonBuilder() // 设置自定义解析(不支持协变) .registerTypeAdapter(Id.class, new IdTypeAdapter()) // 设置自定义解析(支持协变) registerTypeHierarchyAdapter(List.class, new MyListTypeAdapter()) // 设置自定义解析(以工厂方式) .registerTypeAdapterFactory(new IdTypeAdapterFactory()) // 设置日期格式 .setDateFormat("yyyy-MM-dd HH:mm:ss:SSS") // 设置自动切换命名风格规则(默认不切换命名风格) .setFieldNamingPolicy(FieldNamingPolicy.UPPER_CAMEL_CASE) // 设置过滤指定字段标识符(默认只过滤 transient 和 static 字段) .excludeFieldsWithModifiers(Modifier.TRANSIENT | Modifier.STATIC) // 设置类或字段过滤规则 .setExclusionStrategies(new MyExclusionStrategy1()) // 设置过滤规则(只适用于序列化) .addSerializationExclusionStrategy(new MyExclusionStrategy2()) // 设置过滤规则(只适用于反序列化) .addDeserializationExclusionStrategy(new MyExclusionStrategy3()) // 设置序列化版本号 .setVersion(1.0) // 启用非基础类型 Map Key .enableComplexMapKeySerialization() // 启用不过滤空值(默认会过滤空值) .serializeNulls() // 启用 Json 格式化 .setPrettyPrinting() .create();复制
Gson 没有编译时处理,所以注解均是运行时注解。
value 变量在序列化和反序列化时都有效,而 alternate 变量只是在反序列化时做兼容而已;serialize 变量或 deserialize 变量可以声明字段只参与序列化或反序列化,默认都参与。JsonSerializer 和 JsonDeserializer 是 Gson 1.x 版本提供的自定义解析 API,是基于树型结构的解析 API。在解析数据时,它们会将 Json 数据一次性解析为 JsonElement 树型结构。 JsonElement 代表 Json 树上的一个节点,有 4 种具体类型:
| JsonElement | 描述 |
|---|---|
| JsonObject | {} 对象 |
| JsonArray | [] 数组 |
| JsonPrimitive | 基本类型 |
| JsonNull | null 值 |
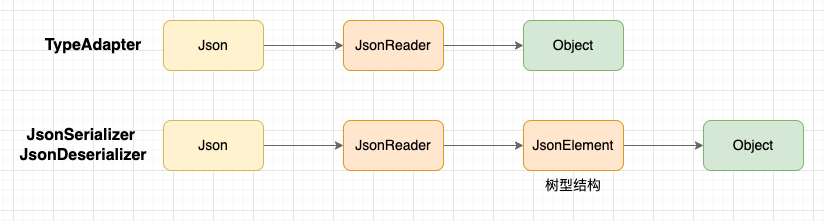
TypeAdapter 是 Gson 2.0 新增的自定义解析 API,是基于流式结构的 API。事实上, JsonSerializer 和 JsonDeserializer 最终也会被构造为 TreeTypeAdapter;
相较之下,JsonSerializer & JsonDeserializer 相对方便,但更费内存。而 TypeAdapter 更节省内存,但不方便。不过,如果需要用到完整数据结构(例如根据 type 字段按照不同类型解析 data),也可以手动解析为树型结构。因此 TypeAdapter 这个 API 的优先级更高。
| TypeAdapter | JsonSerializer、JsonDeserializer | |
|---|---|---|
| 引入版本 | 2.0 | 1.x |
| Stream API | 支持 | 不支持 |
| Tree API | 支持,可以手动转换 | 支持 |
| 内存占用 | 小 | 比 TypeAdapter 大 |
| 效率 | 高 | 比 TypeAdapter 低 |
| 作用范围 | 序列化 + 反序列化 | 序列化 / 反序列化 |
<List.class,TypeAdapter> ,则只会影响 List 类型的字段,但不会影响 ArrayList 类型的字段;<List.class,TypeAdapter>,则只会影响 List、ArrayList 类型的字段;| registerTypeAdapter | registerTypeHierarchyAdapter | |
|---|---|---|
| 支持泛型 | 是 | 否 |
| 支持继承 | 否 | 是 |
这一节,我们来分析 Gson 核心流程的工作原理和源码。
“TypeAdapter” 是 Gson 解析的重要角色,Gson 每次解析一种对象类型,首先需要创建一个 TypeAdapter 对象,之后所有的解析工作都会交给其中的 TypeAdapter#write 和 TypeAdapter#read 方法;
Java Bean 类型的 TypeAdapter 对象是交给 “ReflectiveTypeAdapterFactory” 创建的。每创建一种类型的 TypeAdapter,都需要递归地使用 “反射” 遍历所有字段,并解析字段上的注解,生成一个 <serializeName - BoundFiled> 的映射表。
BoundFiled 序列化;BoundField 反序列为字段类型的值,再通过反射为字段赋值。由于字段值的写入和读取是通过 Field 元数据反射操作的,所以 private 字段也可以操作。
在构造 Gson 对象时,已经初始化了一系列 TypeAdapter 创建工厂,开发者可以注册自定义的 TypeAdapter:
Gson.java
Gson(final Excluder excluder, ...) {
List<TypeAdapterFactory> factories = new ArrayList<TypeAdapterFactory>();
// built-in type adapters that cannot be overridden
factories.add(TypeAdapters.JSON_ELEMENT_FACTORY);
factories.add(ObjectTypeAdapter.FACTORY);
// 过滤规则
factories.add(excluder);
// 自定义 TypeAdapter
factories.addAll(factoriesToBeAdded);
// 1. 基础类型
factories.add(TypeAdapters.STRING_FACTORY);
factories.add(TypeAdapters.INTEGER_FACTORY);
...
// 2. 复合类型
// 2.1 列表类型
factories.add(new CollectionTypeAdapterFactory(constructorConstructor));
// 2.2 集合类型
factories.add(new MapTypeAdapterFactory(constructorConstructor, complexMapKeySerialization));
this.jsonAdapterFactory = new JsonAdapterAnnotationTypeAdapterFactory(constructorConstructor);
factories.add(jsonAdapterFactory);
// 2.3 枚举类型
factories.add(TypeAdapters.ENUM_FACTORY);
// 2.4 Java Bean 类型
factories.add(new ReflectiveTypeAdapterFactory(constructorConstructor, fieldNamingStrategy, excluder, jsonAdapterFactory));
}
复制通过 Gson#getAdapter 查找匹配 TypeAdapter 的方法:
Gson.java
// TypeAdapter 缓存映射表 <Type - TypeAdapter>
private final Map<TypeToken<?>, TypeAdapter<?>> typeTokenCache = new ConcurrentHashMap<TypeToken<?>, TypeAdapter<?>>();
public <T> TypeAdapter<T> getAdapter(TypeToken<T> type) {
// 先从映射表缓存中查找
TypeAdapter<?> cached = typeTokenCache.get(type);
if (cached != null) {
return (TypeAdapter<T>) cached;
}
// 再通过 TypeAdapter 创建工厂创建,并加入映射表缓存中
for (TypeAdapterFactory factory : factories) {
// 从前到后线性扫描创建工厂,找到合适的 TypeAdapter
TypeAdapter<T> candidate = factory.create(this, type);
if (candidate != null) {
// 加入缓存中
typeTokenCache.put(type, candidate);
return candidate;
}
}
}
复制使用 ReflectiveTypeAdapterFactory 工厂为每种类型创建 TypeAdapter 对象:
ReflectiveTypeAdapterFactory.java
// 1. 创建 TypeAdapter 对象
@Override
public <T> TypeAdapter<T> create(Gson gson, final TypeToken<T> type) {
Class<? super T> raw = type.getRawType();
// 检查是否为 Object 类型
if (!Object.class.isAssignableFrom(raw)) {
return null; // it's a primitive!
}
// 1.1 获取对象构造器(下文分析)
ObjectConstructor<T> constructor = constructorConstructor.get(type);
// 1.2 getBoundFields:解析每个字段的适配器
// 1.3 FieldReflectionAdapter:TypeAdapter 对象(Adapter 类型)
return new FieldReflectionAdapter<T>(constructor, getBoundFields(gson, type, raw));
}
public static abstract class Adapter<T, A> extends TypeAdapter<T> {
final Map<String, BoundField> boundFields;
// 2. 反序列化过程
@Override
public T read(JsonReader in) {
// 2.1 创建对象
T instance = constructor.construct();
// 2.2 消费 {
in.beginObject();
// 2.3 递归反序列化每个字段
while (in.hasNext()) {
String name = in.nextName();
BoundField field = boundFields.get(name);
if (field == null || !field.deserialized) {
in.skipValue();
} else {
// 读取流并设置到 instance 对象中
readIntoField(in, instance);
}
}
// 2.4 消费 }
in.endObject();
return instance;
}
// 3. 序列化过程
@Override
public void write(JsonWriter out, T value) {
// 3.1 写入 {
out.beginObject();
// 3.2 递归序列化每个字段
for (BoundField boundField : boundFields.values()) {
// 将对象的每个字段写入流中
boundField.write(out, value);
}
// 3.3 写入 }
out.endObject();
}
}
// -> 1.2 getBoundFields:解析每个字段的适配器
private Map<String, BoundField> getBoundFields(Gson context, TypeToken<?> type, Class<?> raw, boolean blockInaccessible, boolean isRecord) {
// 1.2.1 映射表
Map<String, BoundField> result = new LinkedHashMap<>();
if (raw.isInterface()) {
return result;
}
...
// 1.2.2 遍历所有 Field
Field[] fields = raw.getDeclaredFields();
for (Field field : fields) {
// 1.2.2.1 字段过滤
boolean serialize = includeField(field, true);
boolean deserialize = includeField(field, false);
if (!serialize && !deserialize) {
continue;
}
// 1.2.2.2 获取字段的所有别名,第 0 位是主名称
List<String> fieldNames = getFieldNames(field);
// 1.2.2.3 为所有字段别名创建 BoundField 对象
for (int i = 0, size = fieldNames.size(); i < size; ++i) {
String name = fieldNames.get(i);
// serialize = false 这一行说明:序列化时是采用字段的主名称
if (i != 0) serialize = false;
BoundField boundField = createBoundField(context, field, accessor, name, TypeToken.get(fieldType), serialize, deserialize, blockInaccessible);
BoundField replaced = result.put(name, boundField);
if (previous == null) previous = replaced;
}
// 1.2.2.4 存在两个的字段使用相同 serializeName 的冲突
if (previous != null) {
throw new IllegalArgumentException(declaredType + " declares multiple JSON fields named " + previous.name);
}
}
// 1.2.3 返回映射表
return result;
}
// -> 1.2.2.3 为所有字段别名创建 BoundField 对象
private ReflectiveTypeAdapterFactory.BoundField createBoundField(
final Gson context, final Field field, final String name,
final TypeToken<?> fieldType, boolean serialize, boolean deserialize) {
// 基本类型
final boolean isPrimitive = Primitives.isPrimitive(fieldType.getRawType());
// @JsonAdapter 注解
JsonAdapter annotation = field.getAnnotation(JsonAdapter.class);
TypeAdapter<?> mapped = null;
if (annotation != null) {
mapped = jsonAdapterFactory.getTypeAdapter(constructorConstructor, context, fieldType, annotation);
}
final boolean jsonAdapterPresent = mapped != null;
if (mapped == null) mapped = context.getAdapter(fieldType);
final TypeAdapter<?> typeAdapter = mapped;
return new ReflectiveTypeAdapterFactory.BoundField(name, serialize, deserialize) {
@Override
void write(JsonWriter writer, Object value) {
if (!serialized) return;
// 通过反射读取字段值
Object fieldValue = field.get(value);
TypeAdapter t = jsonAdapterPresent ? typeAdapter : new TypeAdapterRuntimeTypeWrapper(context, typeAdapter, fieldType.getType());
// 写出到流
t.write(writer, fieldValue);
}
@Override
void readIntoField(JsonReader reader, Object target) {
// 从流读取
Object fieldValue = typeAdapter.read(reader);
// 通过反射写入字段值
field.set(target, fieldValue);
}
};
}
复制RawType 获取容器构造器,再根据泛型实参 elementType 获取元素类型的 TypeAdapter;CollectionTypeAdapterFactory.java
// 1. 创建 TypeAdapter
public <T> TypeAdapter<T> create(Gson gson, TypeToken<T> typeToken) {
Type type = typeToken.getType();
// 检查是否为列表类型
Class<? super T> rawType = typeToken.getRawType();
if (!Collection.class.isAssignableFrom(rawType)) {
return null;
}
// 1.1 解析元素类型
Type elementType = $Gson$Types.getCollectionElementType(type, rawType);
// 1.2 查找元素类型映射的 TypeAdapter
TypeAdapter<?> elementTypeAdapter = gson.getAdapter(TypeToken.get(elementType));
// 1.3 解析容器对象的构造器
ObjectConstructor<T> constructor = constructorConstructor.get(typeToken);
// 1.4 包装新的 TypeAdapter
TypeAdapter<T> result = new Adapter(gson, elementType, elementTypeAdapter, constructor);
}
private static final class Adapter<E> extends TypeAdapter<Collection<E>> {
// 2. 反序列化过程
@Override
public Collection<E> read(JsonReader in) {
// 2.1 创建容器对象
Collection<E> collection = constructor.construct();
// 2.2 消费 [
in.beginArray();
// 2.3 使用 1.2 步骤的 TypeAdapter 反序列化每个元素
while (in.hasNext()) {
E instance = elementTypeAdapter.read(in);
collection.add(instance);
}
// 2.4 消费 ]
in.endArray();
return collection;
}
// 3. 序列化过程
@Override
public void write(JsonWriter out, Collection<E> collection) {
// 3.1 写入 [
out.beginArray();
// 3.2 使用 1.2 步骤的 TypeAdapter 序列化每个元素
for (E element : collection) {
elementTypeAdapter.write(out, element);
}
// 3.3 写入 ]
out.endArray();
}
}
复制TypeAdapters.java
private static final class EnumTypeAdapter<T extends Enum<T>> extends TypeAdapter<T> {
// <name - 枚举> 映射表
private final Map<String, T> nameToConstant = new HashMap<String, T>();
// <枚举 - name> 映射表
private final Map<T, String> constantToName = new HashMap<T, String>();
public EnumTypeAdapter(Class<T> classOfT) {
for (T constant : classOfT.getEnumConstants()) {
String name = constant.name()
nameToConstant.put(name, constant);
constantToName.put(constant, name);
}
}
@Override
public T read(JsonReader in) {
return nameToConstant.get(in.nextString());
}
@Override
public void write(JsonWriter out, T value) {
out.value(constantToName.get(value));
}
}
复制ReflectiveTypeAdapterFactory 在创建对象的 TypeAdapter 适配器时,需要递归的创建每个字段的 TypeAdapter。如果字段的类型正好与类的类型相同,那么又会触发创建一个相同的 TypeAdapter,造成无限递归。例如:
无限递归的例子
public class Article {
public Article linkedArticle;
}
复制分析发现,无限递归只发生在第一次创建某个 Java Bean 类型的 TypeAdapter 时,而下一次会从缓存获取,不会发生无限递归。因此,Gson 的做法是:
FutureTypeAdapter 代理对象。在创建真实的 TypeAdapter 后,将其注入到代理对象中。这样在递归获取字段的 TypeAdapter 时,就会拿到代理对象,而不是重新创建 TypeAdapter,因此解决递归问题;ThreadLocal 隔离各个线程的临时映射表。Gson.java
// 线程隔离的映射表
private final ThreadLocal<Map<TypeToken<?>, FutureTypeAdapter<?>>> calls = new ThreadLocal<Map<TypeToken<?>, FutureTypeAdapter<?>>>();
// 线程共享的映射表(基于 ConrurrentHashMap)
private final Map<TypeToken<?>, TypeAdapter<?>> typeTokenCache = new ConcurrentHashMap<TypeToken<?>, TypeAdapter<?>>();
public <T> TypeAdapter<T> getAdapter(TypeToken<T> type) {
// 1. 尝试从缓存获取
TypeAdapter<?> cached = typeTokenCache.get(type);
if (cached != null) {
return (TypeAdapter<T>) cached;
}
// 2. 初始化当前线程的临时映射表
Map<TypeToken<?>, FutureTypeAdapter<?>> threadCalls = calls.get();
boolean requiresThreadLocalCleanup = false;
if (threadCalls == null) {
threadCalls = new HashMap<TypeToken<?>, FutureTypeAdapter<?>>();
calls.set(threadCalls);
requiresThreadLocalCleanup = true;
}
// 3. 尝试从临时映射表获取(递归调用时,会从这里获取到代理 TypeAdapter,而不会走到下面的 factory.create
FutureTypeAdapter<T> ongoingCall = (FutureTypeAdapter<T>) threadCalls.get(type);
if (ongoingCall != null) {
return ongoingCall;
}
try {
// 4.1 创建代理 TypeAdapter
FutureTypeAdapter<T> call = new FutureTypeAdapter<T>();
threadCalls.put(type, call);
for (TypeAdapterFactory factory : factories) {
// 4.2 创建 TypeAdapter
TypeAdapter<T> candidate = factory.create(this, type);
// 4.3 将真实的 TypeAdapter 注入到代理 TypeAdapter 中
if (candidate != null) {
call.setDelegate(candidate);
// 4.4 将 TypeAdapter 写入缓存
typeTokenCache.put(type, candidate);
return candidate;
}
}
} finally {
// 5. 清除临时映射表
threadCalls.remove(type);
if (requiresThreadLocalCleanup) {
calls.remove();
}
}
}
复制InstanceCreator,则优先通过自定义工厂创建;ConstructorConstructor.java
public <T> ObjectConstructor<T> get(TypeToken<T> typeToken) {
final Type type = typeToken.getType();
final Class<? super T> rawType = typeToken.getRawType();
// InstanceCreator API
final InstanceCreator<T> typeCreator = (InstanceCreator<T>) instanceCreators.get(type);
if (typeCreator != null) {
return new ObjectConstructor<T>() {
@Override
public T construct() {
return typeCreator.createInstance(type);
}
};
}
final InstanceCreator<T> rawTypeCreator = (InstanceCreator<T>) instanceCreators.get(rawType);
if (rawTypeCreator != null) {
return new ObjectConstructor<T>() {
@Override
public T construct() {
return rawTypeCreator.createInstance(type);
}
};
}
// 无参构造函数
ObjectConstructor<T> defaultConstructor = newDefaultConstructor(rawType);
if (defaultConstructor != null) {
return defaultConstructor;
}
// 容器类型
ObjectConstructor<T> defaultImplementation = newDefaultImplementationConstructor(type, rawType);
if (defaultImplementation != null) {
return defaultImplementation;
}
// Unsafe API
return newUnsafeAllocator(type, rawType);
}
复制当 Class 未提供默认的无参构造函数时,Gson 会使用 Unsafe API 兜底来创建对象。Unsafe API 主要提供一些用于执行低级别、不安全操作的方法,也提供了一个非常规实例化对象的 allocateInstance 方法。
这个 API 不会调用构造函数
由于 Java 有泛型擦除,无法直接在 .class 语法上声明泛型信息,Gson 的方法是要求程序员创建匿名内部类,由 Gson 在运行时通过反射获取类声明上的泛型信息。
示例代码
// 非法:
Response<User> obj = Gson().fromJson<Response<User>>(jsonStr, Response<User>.class)
// 合法;
TypeToken token = object : TypeToken<Response<User>>() {}
Response<User> obj = Gson().fromJson<Response<User>>(jsonStr, token.type)
复制为什么反序列化泛型类要使用匿名内部类呢?
原理是 Class 文件中的 Signature 属性会保持类签名信息,而 TypeToken 只是一个工具类,内部通过反射获取类签名中泛型信息并返回 Type 类型。
TypeToken.java
protected TypeToken() {
this.type = getSuperclassTypeParameter(getClass());
this.rawType = (Class<? super T>) $Gson$Types.getRawType(type);
this.hashCode = type.hashCode();
}
// 返回 Response<User>
static Type getSuperclassTypeParameter(Class<?> subclass) {
Type superclass = subclass.getGenericSuperclass();
if (superclass instanceof Class) {
throw new RuntimeException("Missing type parameter.");
}
ParameterizedType parameterized = (ParameterizedType) superclass;
return $Gson$Types.canonicalize(parameterized.getActualTypeArguments()[0]);
}
public final Type getType() {
return type;
}
复制既然 TypeToken 只是一个获取 Type 类型的工具类,我们也可以跳过它直接提供 Type,方法是定义 ParameterizedType 参数化类型的子类:
ParameterizedTypeAdapter.java
private static class ParameterizedTypeAdapter implements ParameterizedType {
private final Class<?> rawType;
private final Type[] types;
private ParameterizedTypeAdapter(Class<?> rawType, Type... types) {
this.rawType = rawType;
this.types = types;
}
@Override
public Type[] getActualTypeArguments() {
return types;
}
@Override
public Type getRawType() {
return rawType;
}
@Override
public Type getOwnerType() {
return null;
}
}
复制示例代码
Response<User> obj = new Gson().fromJson<Response<User>>(jsonStr, ParameterizedTypeAdapter(Response.class, User.class))
复制在 Kotlin 中,还可以使用 reified 实化类型参数简化:
Utils.kt
inline fun <reified T> toList(jsonStr: String): List<T> =
Gson().fromJson(content, ParameterizedTypeAdapter(List::class.java, T::class.java))
inline fun <reified T> toObject(jsonStr: String): List<T> =
Gson().fromJson(content, T::class.java))
复制示例代码
List<User> obj = toList<User>(jsonStr)复制
今天,我们讨论了 Gson 的基本用法和以及主要流程的源码分析。
在 Gson 的反序列化中,首次反序列化一个类型的对象时,Gson 需要使用大量反射调用解析一个 TypeAdapter 适配器对象。随着 Model 的复杂程度增加,首次解析的耗时会不断膨胀。
这个问题在抖音的技术博客中提到一个解决方案,这个问题我们在下篇文章讨论,请关注。
