本文已收录到 AndroidFamily,技术和职场问题,请关注公众号 [彭旭锐] 提问。
大家好,我是小彭。
在上一篇文章里,我们聊到了 HashMap 的实现原理和源码分析,在源码分析的过程中,我们发现一些 LinkedHashMap 相关的源码,当时没有展开,现在它来了。
那么,LinkedHashMap 与 HashMap 有什么区别呢?其实,LinkedHashMap 的使用场景非常明确 —— LRU 缓存。今天,我们就来讨论 LinkedHashMap 是如何实现 LRU 缓存的。
本文源码基于 Java 8 LinkedHashMap。
小彭的 Android 交流群 02 群已经建立啦,扫描文末二维码进入~
思维导图:
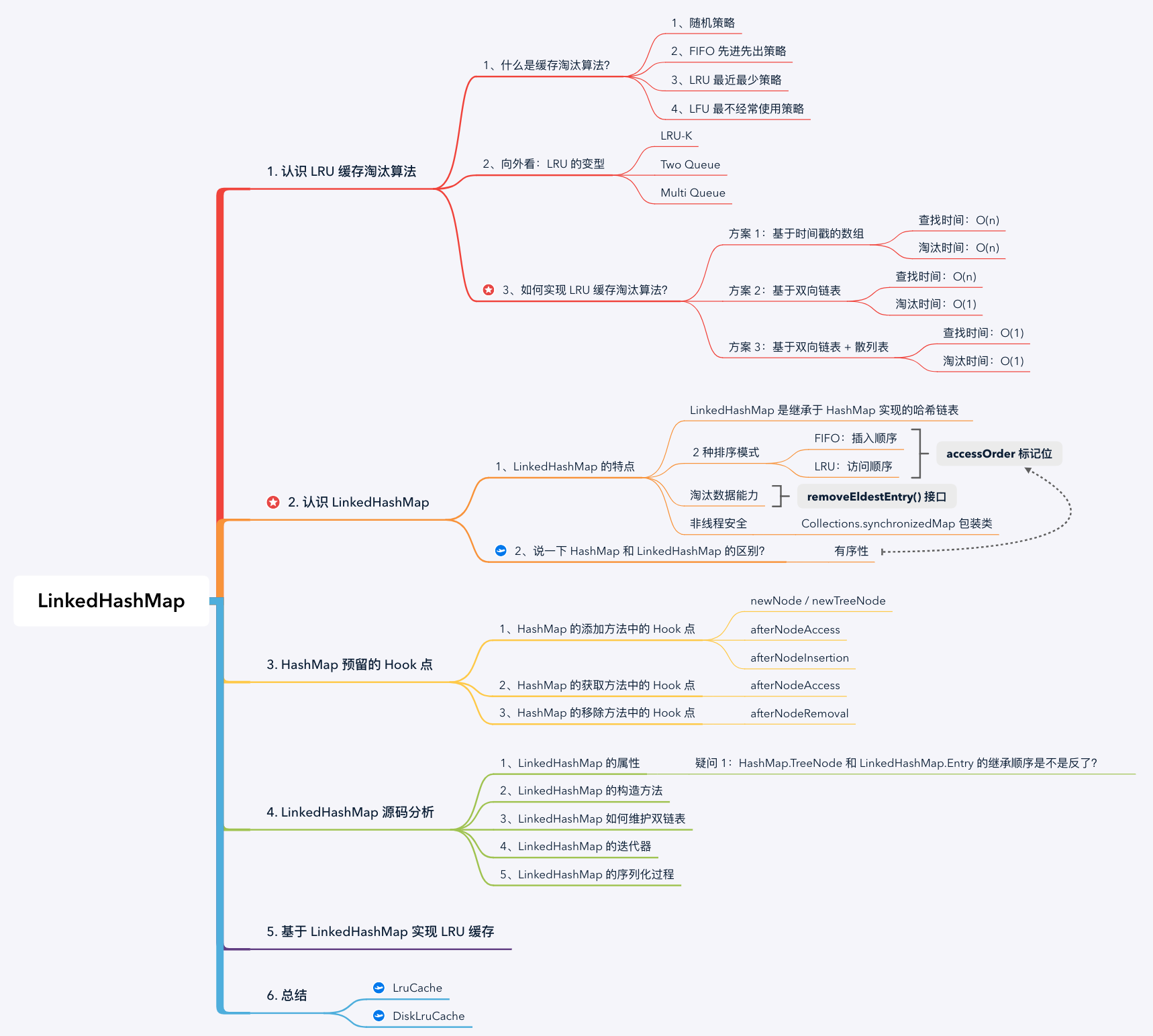
缓存是提高数据读取性能的通用技术,在硬件和软件设计中被广泛使用,例如 CPU 缓存、Glide 内存缓存,数据库缓存等。由于缓存空间不可能无限大,当缓存容量占满时,就需要利用某种策略将部分数据换出缓存,这就是缓存的替换策略 / 淘汰问题。常见缓存淘汰策略有:
1、随机策略: 使用一个随机数生成器随机地选择要被淘汰的数据块;
2、FIFO 先进先出策略: 记录各个数据块的访问时间,最早访问的数据最先被淘汰;
3、LRU (Least Recently Used)最近最少策略: 记录各个数据块的访问 “时间戳” ,最近最久未使用的数据最先被淘汰。与前 2 种策略相比,LRU 策略平均缓存命中率更高,这是因为 LRU 策略利用了 “局部性原理”:最近被访问过的数据,将来被访问的几率较大,最近很久未访问的数据,将来访问的几率也较小;
4、LFU (Least Frequently Used)最不经常使用策略: 与 LRU 相比,LFU 更加注重使用的 “频率” 。LFU 会记录每个数据块的访问次数,最少访问次数的数据最先被淘汰。但是有些数据在开始时使用次数很高,以后不再使用,这些数据就会长时间污染缓存。可以定期将计数器右移一位,形成指数衰减。
FIFO 与 LRU 策略
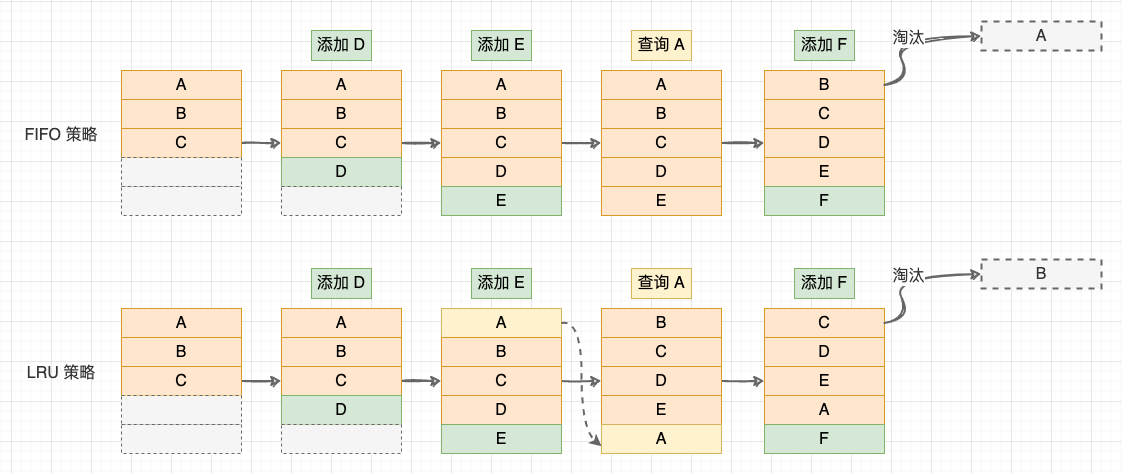
其实,在标准的 LRU 算法上还有一些变型实现,这是因为 LRU 算法本身也存在一些不足。例如,当数据中热点数据较多时,LRU 能够保证较高的命中率。但是当有偶发的批量的非热点数据产生时,就会将热点数据寄出缓存,使得缓存被污染。因此,LRU 也有一些变型:
小彭在 Redis 和 Vue 中有看到这些 LRU 变型的应用,在 Android 领域的框架中还没有看到具体应用,你知道的话可以提醒我。
这一小节,我们尝试找到 LRU 缓存淘汰算法的实现方案。经过总结,我们可以定义一个缓存系统的基本操作:
我们发现,前 3 个操作都有 “查询” 操作, 所以缓存系统的性能主要取决于查找数据和淘汰数据是否高效。 下面,我们用递推的思路推导 LRU 缓存的实现方案,主要分为 3 种方案:
方案 1 - 基于时间戳的数组: 在每个数据块中记录最近访问的时间戳,当数据被访问(添加、更新或查询)时,将数据的时间戳更新到当前时间。当数组空间已满时,则扫描数组淘汰时间戳最小的数据。
方案 2 - 基于双向链表: 不再直接维护时间戳,而是利用链表的顺序隐式维护时间戳的先后顺序。当数据被访问(添加、更新或查询)时,将数据插入到链表头部。当空间已满时,直接淘汰链表的尾节点。
方案 3 - 基于双向链表 + 散列表: 使用双向链表可以将淘汰数据的时间复杂度降低为 O(1),但是查询数据的时间复杂度还是 O(n),我们可以在双向链表的基础上增加散列表,将查询操作的时间复杂度降低为 O(1)。
方案 3 这种数据结构就叫 “哈希链表或链式哈希表”,我更倾向于称为哈希链表,因为当这两个数据结构相结合时,我们更看重的是它作为链表的排序能力。
我们今天要讨论的 Java LinkedHashMap 就是基于哈希链表的数据结构。
需要注意:LinkedHashMap 中的 “Linked” 实际上是指双向链表,并不是指解决散列冲突中的分离链表法。
1、LinkedHashMap 是继承于 HashMap 实现的哈希链表,它同时具备双向链表和散列表的特点。事实上,LinkedHashMap 继承了 HashMap 的主要功能,并通过 HashMap 预留的 Hook 点维护双向链表的逻辑。
2、LinkedHashMap 支持 2 种排序模式,这是通过构造器参数 accessOrder 标记位控制的,表示是否按照访问顺序排序,默认为 false 按照插入顺序。
3、在有序性的基础上,LinkedHashMap 提供了维护了淘汰数据能力,并开放了淘汰判断的接口 removeEldestEntry()。在每次添加数据时,会回调 removeEldestEntry() 接口,开发者可以重写这个接口决定是否移除最早的节点(在 FIFO 策略中是最早添加的节点,在 LRU 策略中是最早未访问的节点);
4、与 HashMap 相同,LinkedHashMap 也不考虑线程同步,也会存在线程安全问题。可以使用 Collections.synchronizedMap 包装类,其原理也是在所有方法上增加 synchronized 关键字。
事实上,HashMap 和 LinkedHashMap 并不是平行的关系,而是继承的关系,LinkedHashMap 是继承于 HashMap 实现的哈希链表。
两者主要的区别在于有序性: LinkedHashMap 会维护数据的插入顺序或访问顺序,而且封装了淘汰数据的能力。在迭代器遍历时,HashMap 会按照数组顺序遍历桶节点,从开发者的视角看是无序的。而是按照双向链表的顺序从 head 节点开始遍历,从开发者的视角是可以感知到的插入顺序或访问顺序。
LinkedHashMap 示意图
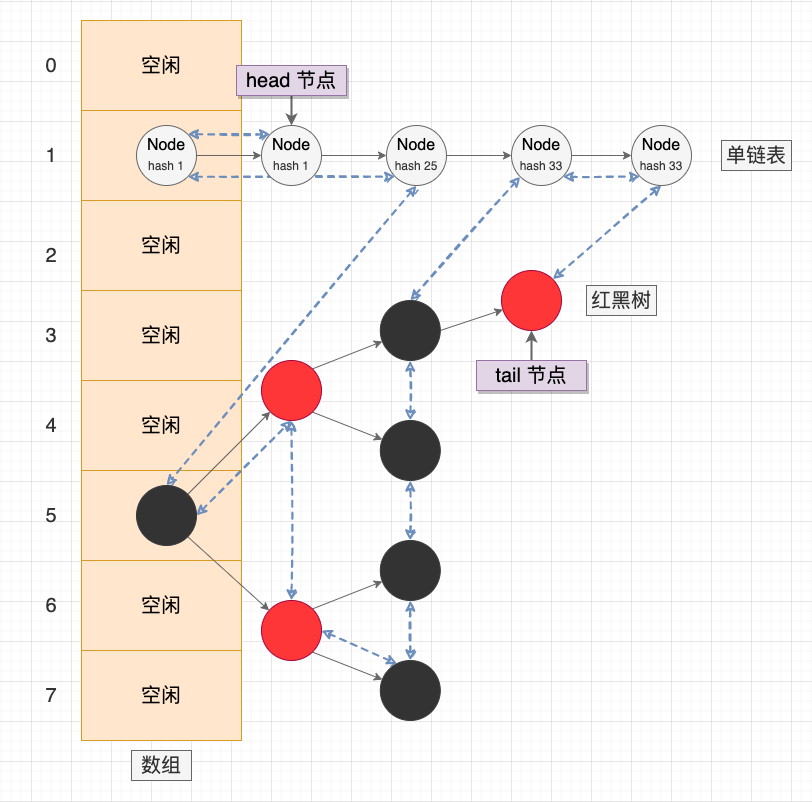
LinkedHashMap 继承于 HashMap,在后者的基础上通过双向链表维护节点的插入顺序或访问顺序。因此,我们先回顾下 HashMap 为 LinkedHashMap 预留的 Hook 点:
evict 标记是否淘汰最早的节点。在初始化、反序列化或克隆等构造过程中,evict 默认为 false,表示在构造过程中不淘汰。HashMap.java
// 节点访问回调
void afterNodeAccess(Node<K,V> p) { }
// 节点插入回调
// evict:是否淘汰最早的节点
void afterNodeInsertion(boolean evict) { }
// 节点移除回调
void afterNodeRemoval(Node<K,V> p) { }
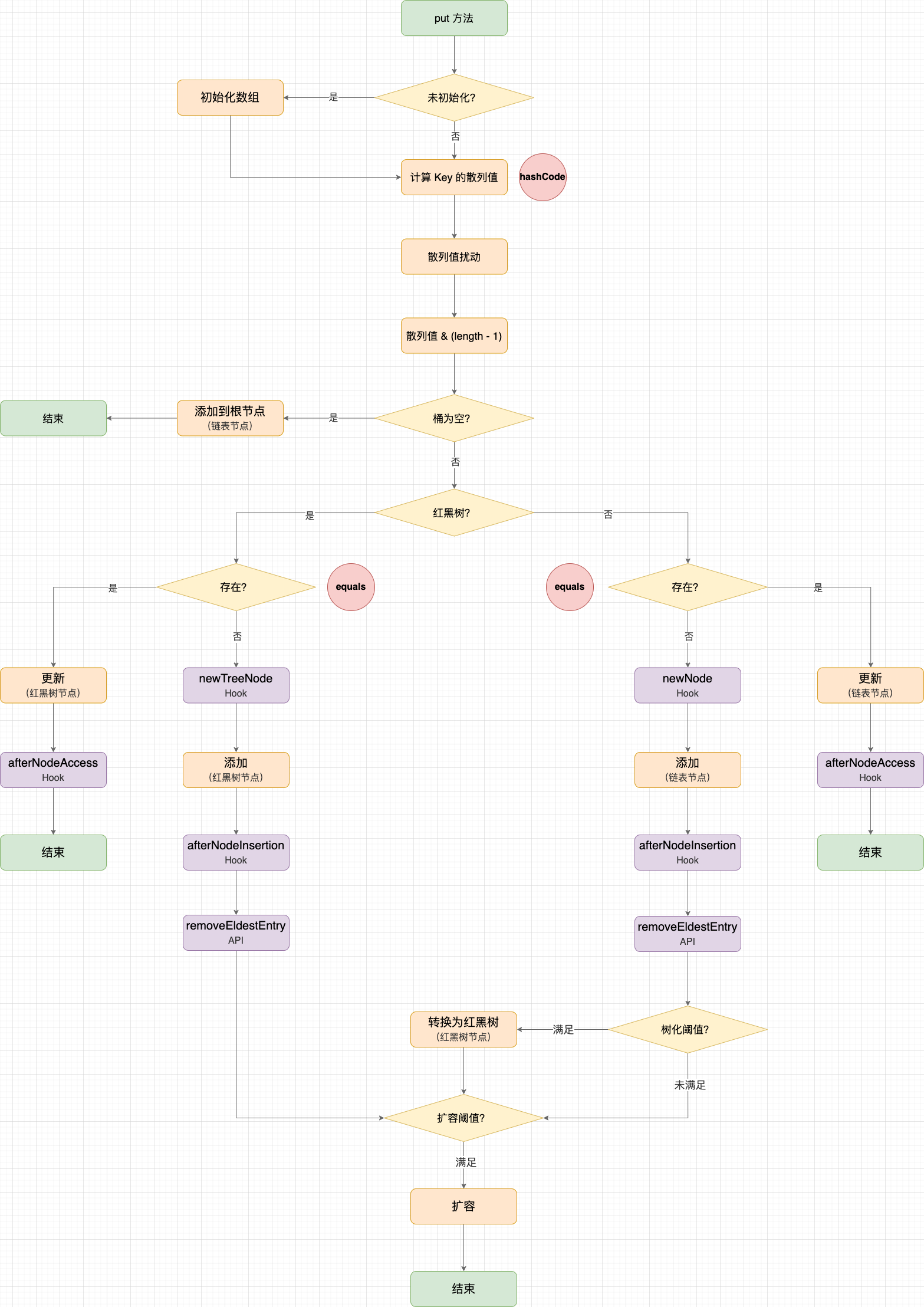
复制除此了这 3 个空方法外,LinkedHashMap 也重写了部分 HashMap 的方法,在其中插入双链表的维护逻辑,也相当于 Hook 点。在 HashMap 的添加、获取、移除方法中,与 LinkedHashMap 有关的 Hook 点如下:
LinkedHashMap 直接复用 HashMap 的添加方法,也支持批量添加:
不管是逐个添加还是批量添加,最终都会先通过 hash 函数计算键(Key)的散列值,再通过 HashMap#putVal 添加或更新键值对,这些都是 HashMap 的行为。关键的地方在于:LinkedHashMap 在 HashMap#putVal 的 Hook 点中加入了双线链表的逻辑。区分 2 种情况:
newNode() 或 newTreeNode() 创建节点,并回调 afterNodeInsertion();afterNodeAccess()。HashMap.java
// 添加或更新键值对
public V put(K key, V value) {
return putVal(hash(key) /*计算散列值*/, key, value, false, true);
}
// hash:Key 的散列值(经过扰动)
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n;
int i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// (n - 1) & hash:散列值转数组下标
if ((p = tab[i = (n - 1) & hash]) == null)
// 省略遍历桶的代码,具体分析见 HashMap 源码讲解
// 1.1 如果节点不存在,则新增节点
p.next = newNode(hash, key, value, null);
// 2.1 如果节点存在更新节点 Value
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 2.2 Hook:访问节点回调
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 扩容
if (++size > threshold)
resize();
// 1.2 Hook:新增节点回调
afterNodeInsertion(evict);
return null;
}
复制HashMap#put 示意图
LinkedHashMap 重写了 HashMap#get 方法,在 HashMap 版本的基础上,增加了 afterNodeAccess() 回调。
HashMap.java
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
复制LinkedHashMap.java
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
// Hook:节点访问回调
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return defaultValue;
// Hook:节点访问回调
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
复制HashMap#get 示意图
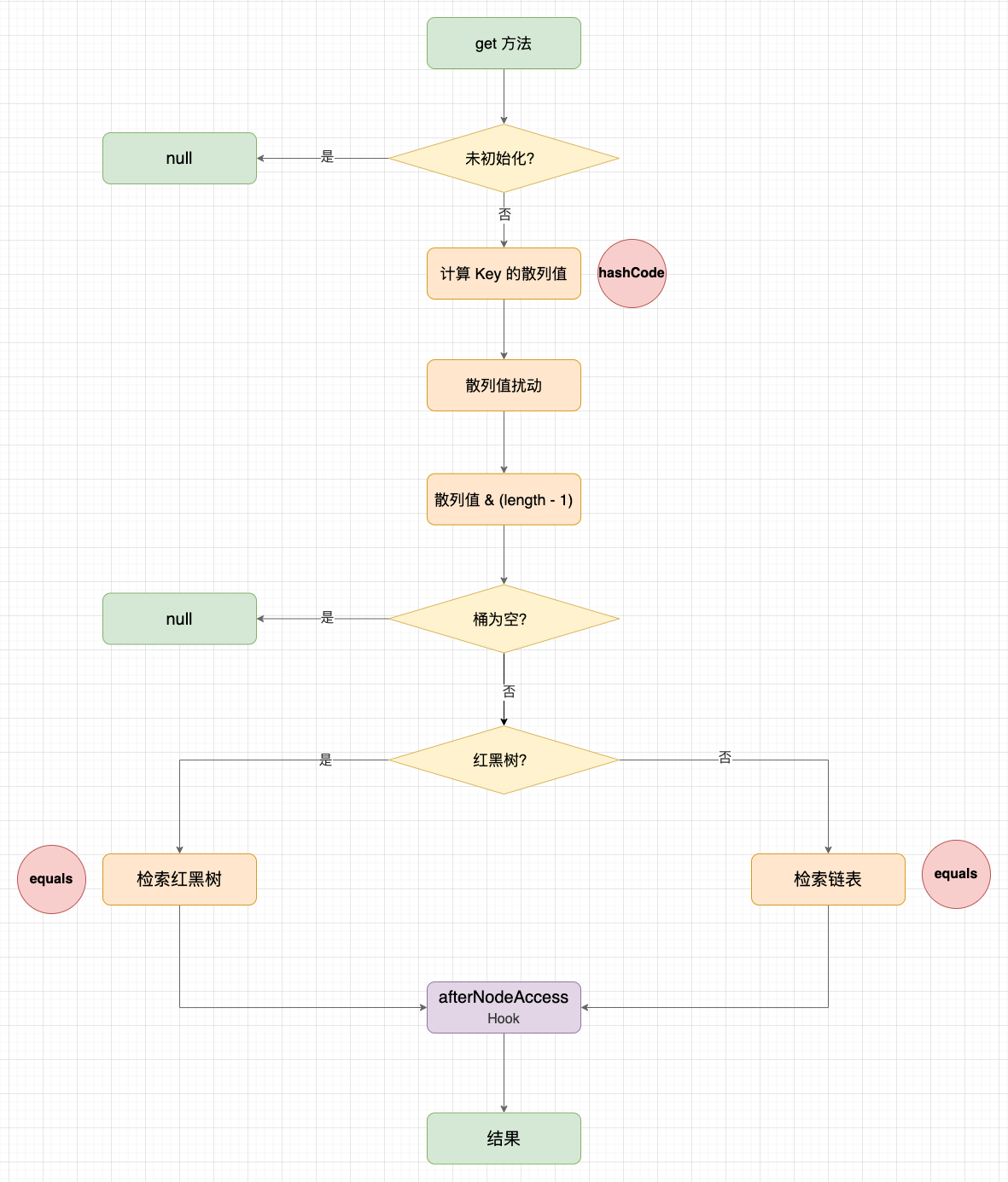
LinkedHashMap 直接复用 HashMap 的移除方法,在移除节点后,增加 afterNodeRemoval() 回调。
HashMap.java
// 移除节点
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key)/*计算散列值*/, key, null, false, true)) == null ? null : e.value;
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab;
Node<K,V> p;
int n, index;
// (n - 1) & hash:散列值转数组下标
if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
// 省略遍历桶的代码,具体分析见 HashMap 源码讲解
// 删除 node 节点
if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) {
// 省略删除节点的代码,具体分析见 HashMap 源码讲解
++modCount;
--size;
// Hook:删除节点回调
afterNodeRemoval(node);
return node;
}
}
return null;
}
复制HashMap#remove 示意图

这一节,我们来分析 LinkedHashMap 中主要流程的源码。
head 和 tail 指针指向链表的头尾节点(与 LinkedList 类似的头尾节点);节点继承关系
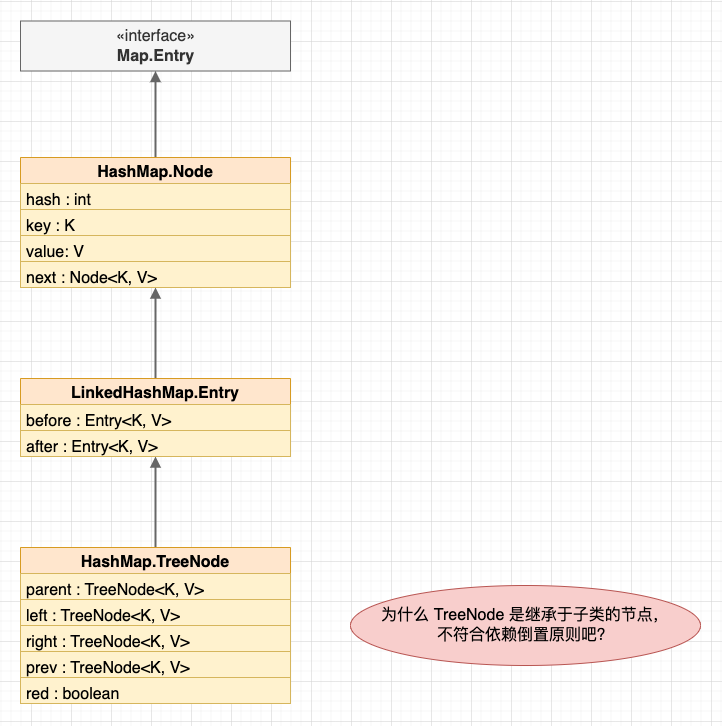
LinkedHashMap.java
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {
// 头指针
transient LinkedHashMap.Entry<K,V> head;
// 尾指针
transient LinkedHashMap.Entry<K,V> tail;
// 是否按照访问顺序排序
final boolean accessOrder;
// 双向链表节点
static class Entry<K,V> extends HashMap.Node<K,V> {
// 前驱指针和后继指针(用于双向链表)
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next/*单链表指针(用于散列表的冲突解决)*/) {
super(hash, key, value, next);
}
}
}
复制LinkedList.java
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
// 头指针(// LinkedList 中也有类似的头尾节点)
transient Node<E> first;
// 尾指针
transient Node<E> last;
// 双向链表节点
private static class Node<E> {
// 节点数据
// (类型擦除后:Object item;)
E item;
// 前驱指针
Node<E> next;
// 后继指针
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}
复制LinkedHashMap 的属性很好理解的,不出意外的话又有小朋友出来举手提问了:
我的理解是作者希望简化节点类型,所以采用了非常规的做法(不愧是标准库)。由于 Java 是单继承的,如果按照常规的做法让 HashMap.TreeNode 直接继承 HashMap.Node,那么在 LinkedHashMap 中就需要区分 LinkedHashMap.Entry 和 LinkedHashMap.TreeEntry,再使用接口统一两种类型。
常规实现
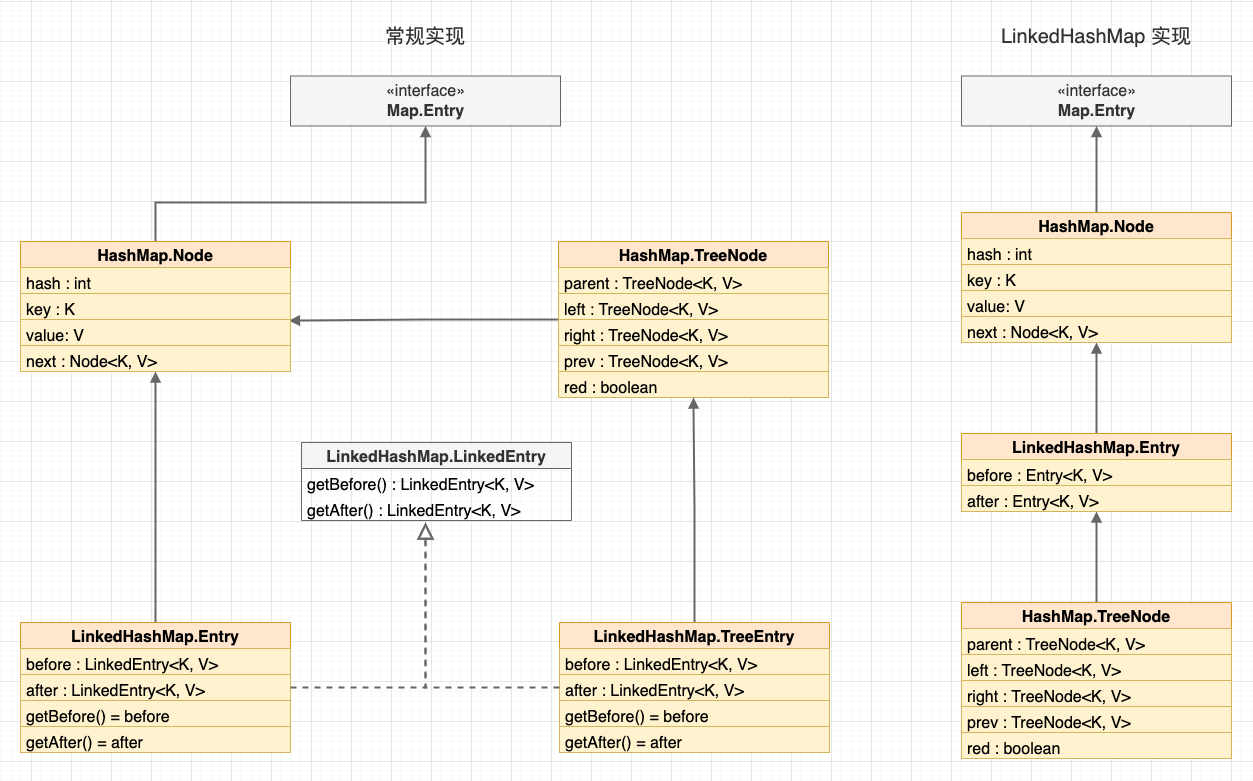
LinkedHashMap 有 5 个构造方法,作用与 HashMap 的构造方法基本一致,区别只在于对 accessOrder 字段的初始化。
// 带初始容量和装载因子的构造方法
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
// 带初始容量的构造方法
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
// 无参构造方法
public LinkedHashMap() {
super();
accessOrder = false;
}
// 带 Map 的构造方法
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
// 带初始容量、装载因子和 accessOrder 的构造方法
// 是否按照访问顺序排序,为 true 表示按照访问顺序排序,默认为 false
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
复制现在,我们看下 LinkedHashMap 是如何维护双链表的。其实,我们将上一节所有的 Hook 点汇总,会发现这些 Hook 点正好组成了 LinkedHashMap 双向链表的行为:
LinkedHashMap.java
// -> 1.1 如果节点不存在,则新增节点
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
// 新建双向链表节点
LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// 添加到双向链表尾部,等价于 LinkedList#linkLast
linkNodeLast(p);
return p;
}
// -> 1.1 如果节点不存在,则新增节点
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
// 新建红黑树节点(继承于双向链表节点)
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
// 添加到双向链表尾部,等价于 LinkedList#linkLast
linkNodeLast(p);
return p;
}
// 添加到双向链表尾部,等价于 LinkedList#linkLast
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
// last 为 null 说明首个添加的元素,需要修改 first 指针
head = p;
else {
// 将新节点的前驱指针指向 last
p.before = last;
// 将 last 的 next 指针指向新节点
last.after = p;
}
}
// 节点插入回调
// evict:是否淘汰最早的节点
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
// removeEldestEntry:是否淘汰最早的节点,即是否淘汰头节点(由子类实现)
if (evict && (first = head) != null && removeEldestEntry(first)) {
// 移除 first 节点,腾出缓存空间
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
// 移除节点回调
void afterNodeRemoval(Node<K,V> e) { // unlink
// 实现了标准的双链表移除
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
// 删除的是头节点,则修正 head 指针
head = a;
else
// 修正前驱节点的后继指针,指向被删除节点的后继节点
b.after = a;
if (a == null)
// 删除的是尾节点,则修正 tail 指针
tail = b;
else
// 修正后继节点的前驱指针,指向被删除节点的前驱节点
a.before = b;
}
// 节点访问回调
void afterNodeAccess(Node<K,V> e) { // move node to last
// 先将节点 e 移除,再添加到链表尾部
LinkedHashMap.Entry<K,V> last;
// accessOrder:是否按照访问顺序排序,为 false 则保留插入顺序
if (accessOrder && (last = tail) != e) {
// 这两个 if 语句块就是 afterNodeRemoval 的逻辑
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
// 这个 if 语句块就是 linkNodeLast 的逻辑
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
// 淘汰判断接口,由子类实现
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
复制与 HashMap 类似,LinkedHashMap 也提供了 3 个迭代器:
区别在于 LinkedHashMap 自己实现了 LinkedHashIterator。在迭代器遍历时,HashMap 会按照数组顺序遍历桶节点,从开发者的视角看是无序的。而 LinkedHashMap 是按照双向链表的顺序从 head 节点开始遍历,从开发者的视角是可以感知到的插入顺序或访问顺序。
LinkedHashMap.java
abstract class LinkedHashIterator {
LinkedHashMap.Entry<K,V> next;
LinkedHashMap.Entry<K,V> current;
// 修改计数
int expectedModCount;
LinkedHashIterator() {
// 从头结点开始遍历
next = head;
// 修改计数
expectedModCount = modCount;
current = null;
}
public final boolean hasNext() {
return next != null;
}
final LinkedHashMap.Entry<K,V> nextNode() {
LinkedHashMap.Entry<K,V> e = next;
// 检查修改计数
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
current = e;
next = e.after;
return e;
}
...
}
复制与 HashMap 相同,LinkedHashMap 也重写了 JDK 序列化的逻辑,并保留了 HashMap 中序列化的主体结构。LinkedHashMap 只是重写了 internalWriteEntries(),按照双向链表的顺序进行序列化,这样在反序列化时就能够恢复双向链表顺序。
HashMap.java
// 序列化过程
private void writeObject(java.io.ObjectOutputStream s) throws IOException {
int buckets = capacity();
s.defaultWriteObject();
// 写入容量
s.writeInt(buckets);
// 写入有效元素个数
s.writeInt(size);
// 写入有效元素
internalWriteEntries(s);
}
// 不关心键值对所在的桶,在反序列化会重新映射
void internalWriteEntries(java.io.ObjectOutputStream s) throws IOException {
Node<K,V>[] tab;
if (size > 0 && (tab = table) != null) {
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
s.writeObject(e.key);
s.writeObject(e.value);
}
}
}
}
复制LinkedHashMap.java
// 重写:按照双向链表顺序写入
void internalWriteEntries(java.io.ObjectOutputStream s) throws IOException {
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
s.writeObject(e.key);
s.writeObject(e.value);
}
}
复制这一节,我们来实现一个简单的 LRU 缓存。理解了 LinkedHashMap 维护插入顺序和访问顺序的原理后,相信你已经知道如何实现 LRU 缓存了。
accessOrder 标记位控制的。所以,这里我们需要将 accessOrder 设置为 true 表示使用 LRU 模式的访问顺序排序。removeEldestEntry(),当缓存数量大于缓存容量时返回 true,表示移除最早的节点。MaxSizeLruCacheDemo.java
public class MaxSizeLruCacheDemo extends LinkedHashMap {
private int maxElements;
public LRUCache(int maxSize) {
super(maxSize, 0.75F, true);
maxElements = maxSize;
}
protected boolean removeEldestEntry(java.util.Map.Entry eldest) {
// 超出容量
return size() > maxElements;
}
}
复制1、LRU 是一种缓存淘汰算法,与其他淘汰算法相比,LRU 算法利用了 “局部性原理”,缓存的平均命中率更高;
2、使用双向链表 + 散列表实现的 LRU,在添加、查询、移除和淘汰数据的时间复杂度都是 O(1),这种数据结构也叫哈希链表;
3、使用 LinkedHashMap 时,主要关注 2 个 API:
accessOrder 标记位: LinkedHashMap 同时实现了 FIFO 和 LRU 两种淘汰策略,默认为 FIFO 排序,可以使用 accessOrder 标记位修改排序模式。removeEldestEntry() 接口: 每次添加数据时,LinkedHashMap 会回调 removeEldestEntry() 接口。开发者可以重写 removeEldestEntry() 接口决定是否移除最早的节点(在 FIFO 策略中是最早添加的节点,在 LRU 策略中是最久未访问的节点)。4、Android 的 LruCache 内存缓存和 DiskLruCache 磁盘缓存中,都直接复用了 LinkedHashMap 的 LRU 能力。
今天,我们分析了 LinkedHashMap 的实现原理。在下篇文章里,我们来分析 LRU 的具体实现应用,例如 Android 标准库中的 LruCache 内存缓存。
可以思考一个问题,LinkedHashMap 是非线程安全的,Android 的 LruCache 是如何解决线程安全问题的?请关注 小彭说 · Android 开源组件 专栏。
