操作系统 :Windows 10_x64
Python版本:3.9.2
noisereduce版本:3.0.2
从事音频相关工作,大概率会碰到降噪问题,今天整理下之前学习音频文件降噪的笔记,并提供Audacity和python示例。
我将从以下几个方面展开:配套资源下载
pypi地址:https://pypi.org/project/noisereduce/
GitHub地址:
https://github.com/timsainb/noisereduce
安装命令:
pip install noisereduce复制
noisereduce库用于音频降噪,支持稳态降噪和非稳态降噪,大致介绍如下:
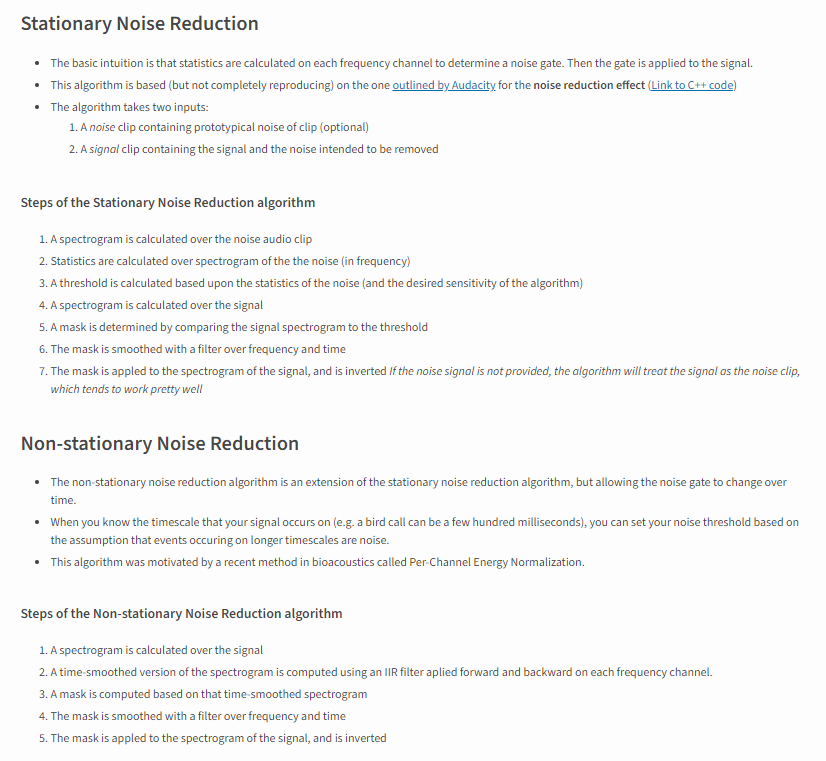
其中稳态降噪基于(并不完全是)Audacity的降噪算法,降噪Audacity效果可通过体验,对应的C++实现如下:
https://github.com/audacity/audacity/blob/master/src/effects/NoiseReduction.cpp
如果链接打不开,可从文末提供的渠道获取该文件。
Audacity的降噪算法需要两个输入:1) 带噪音的音频数据;2) 噪音特征音频数据;
其核心思路是通过fft在频域进行滤波处理并还原,具体实现建议阅读源码。
非稳定降噪算法是稳态降噪算法的扩展,但允许噪声门随时间变化。
Audacity版本:3.1.3
这里使用Audacity进行噪音文件的生成,如果不了解Audacity软件,可参考这篇文章:
这里使用鼓点模拟正常音频,具体如下:
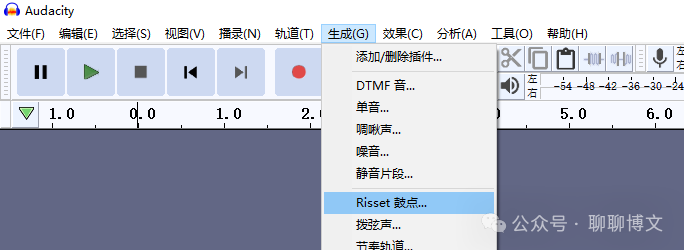
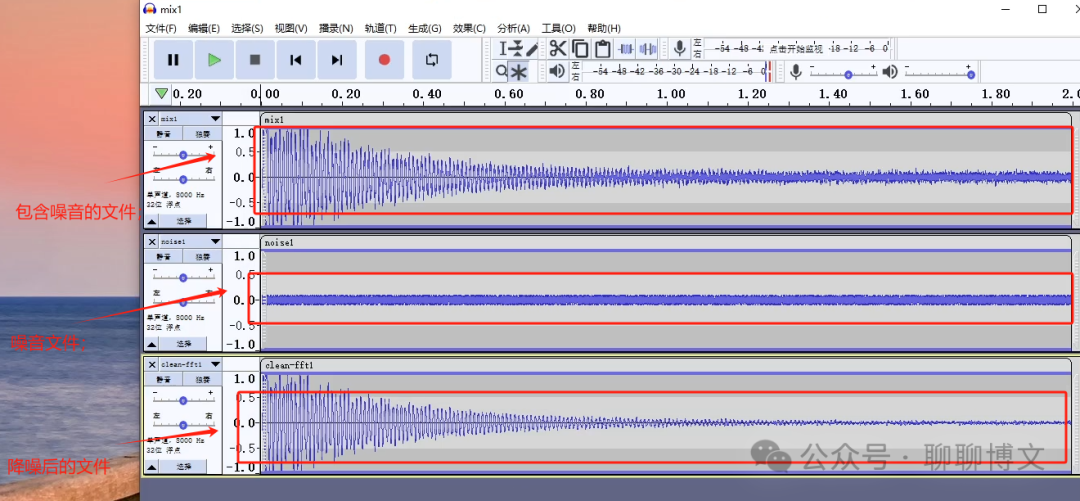
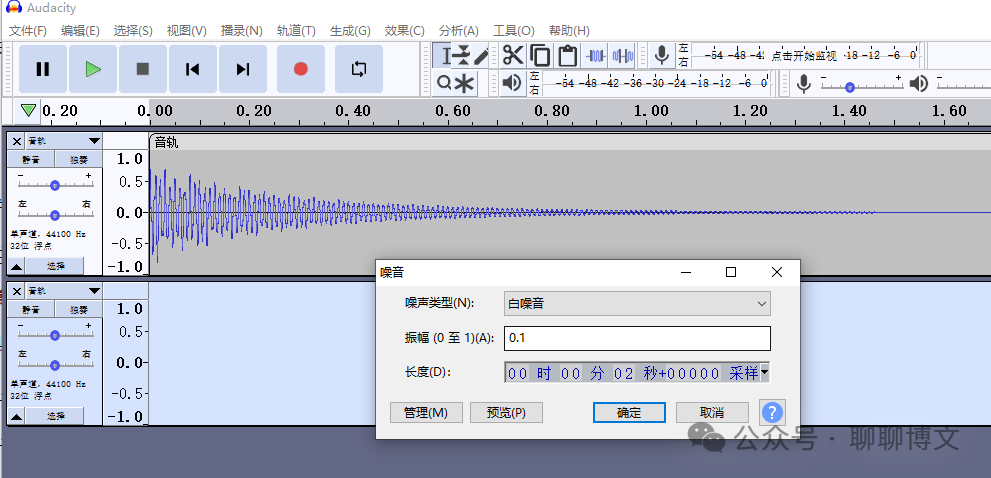
选择菜单“生成-》噪音”选项,这里选择“白噪音”,振幅选择0.1:
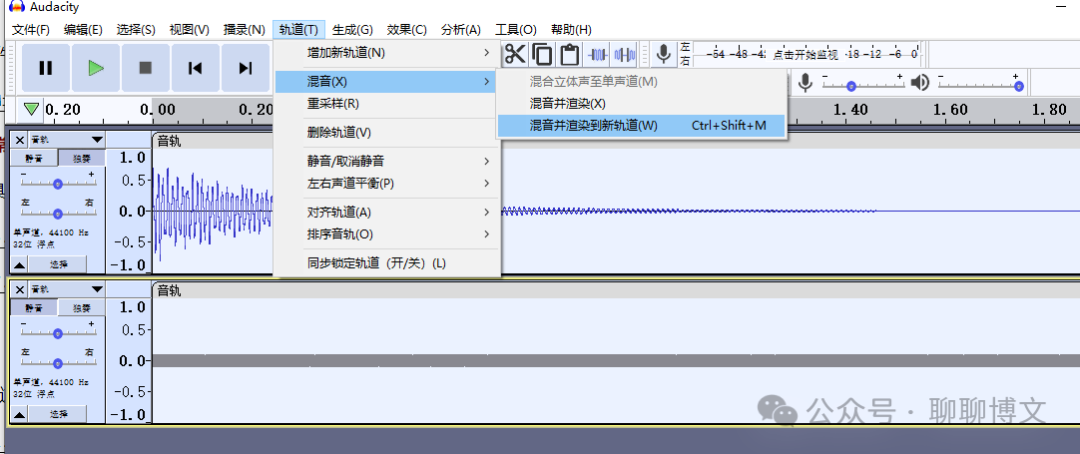
选中两个音轨,然后混音:
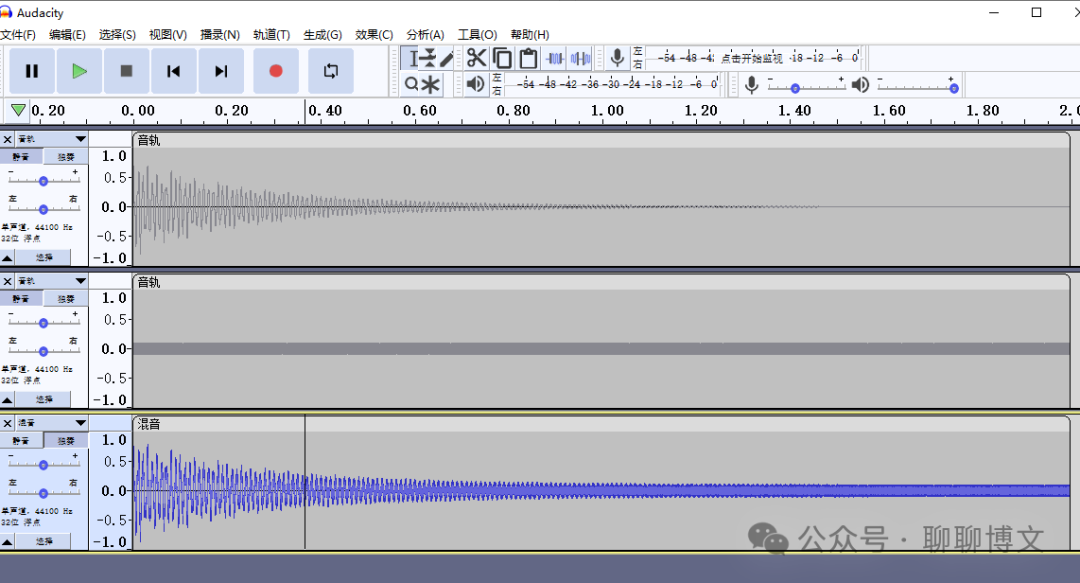
如果想直接使用导出的混音文件(mix1.wav),可从如下渠道获取:
这里首先描述下如何使用Audacity进行降噪,其中,Audacity降噪是完全操作层面的事情,不涉及编写代码;进一步的,会提供如何使用fft进行滤波降噪的示例,主要是模拟稳态降噪算法(并不完全是);最后,会提供如何使用noisereduce进行降噪的示例。
1) 选中噪音特征数据
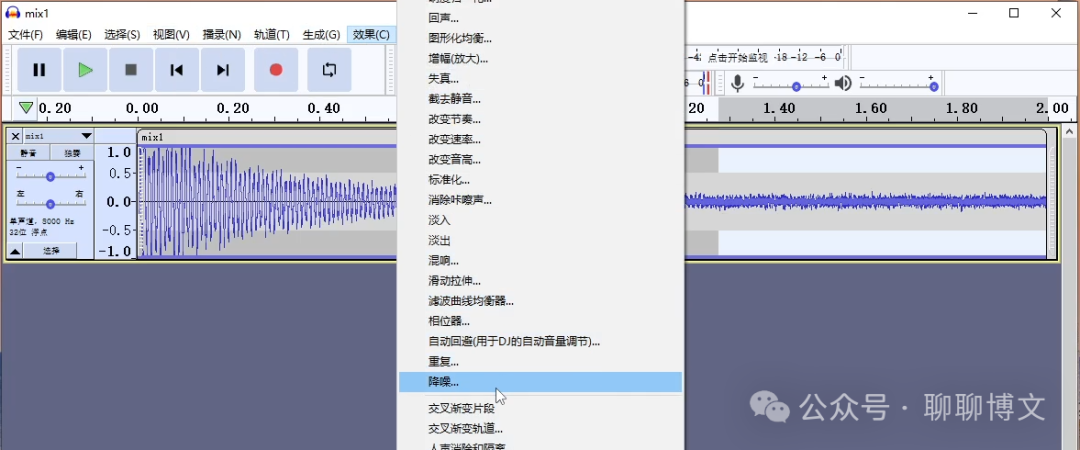
2) 获取噪音特征数据
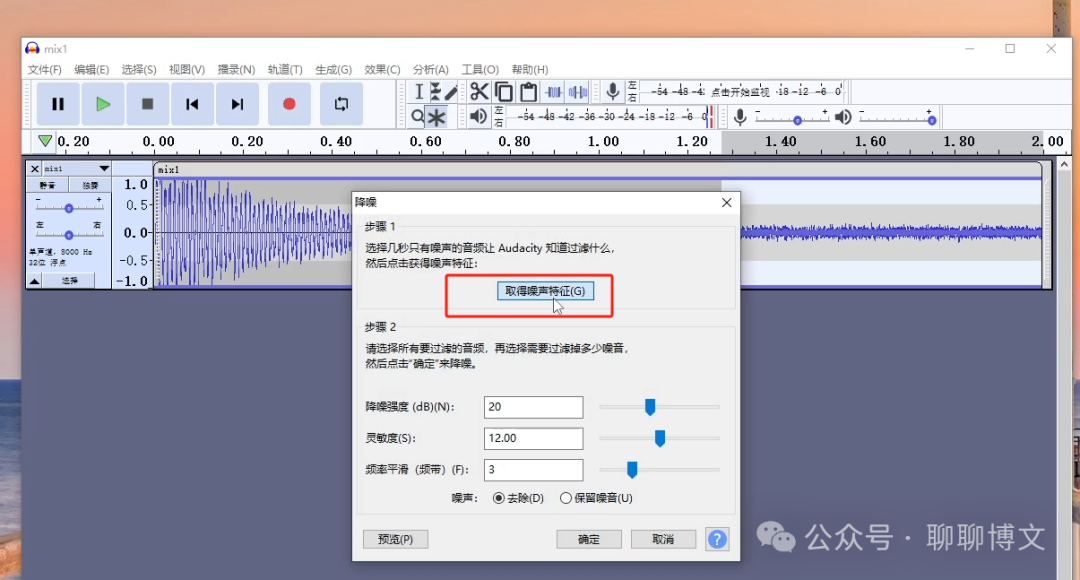
3) 选中需要降噪的原始音频,执行降噪操作
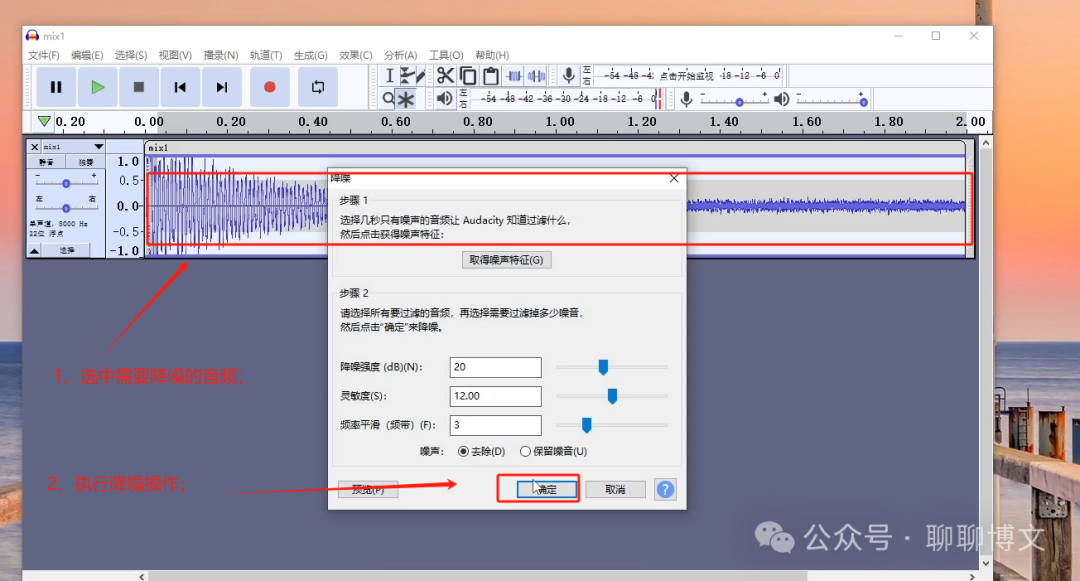
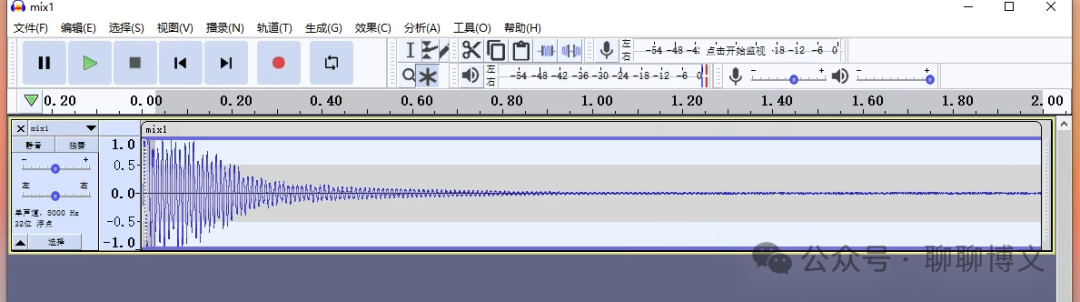
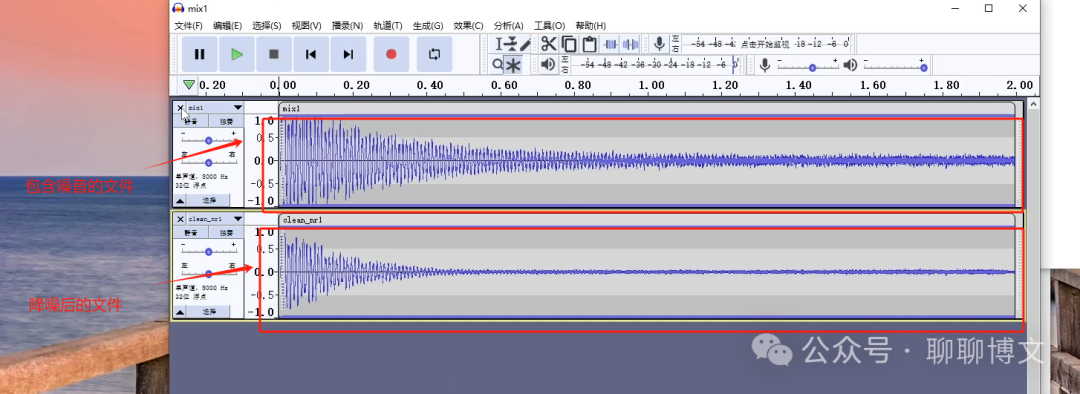
降噪后的效果如下:
使用Audacity进行降噪的过程及效果视频,可从如下渠道获取:
傅立叶变换是可逆的,在频域中对信号所做的任何更改都将在将其变换回时域时应用。可利用这一点来过滤音频并去除高频,进而实现降噪,当然该方法仅适用于高频噪音。
直接在频域进行过滤,大致流程如下:
1) 加载混音文件(mix1.wav),使用fft获取频域数据;
2) 加载噪音文件(noise1.wav),使用fft获取频域数据;
3) 在频域进行滤波;
4) 进行ifft逆变换;
5) 导出降噪后的文件;
示例如下(fftTest1.py):
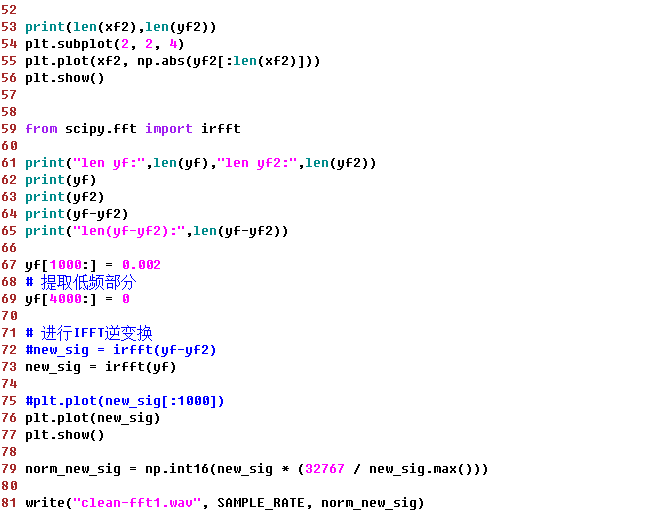
完整源码可从如下渠道获取:
使用noisereduce库进行降噪的运行效果视频,可从如下渠道获取:
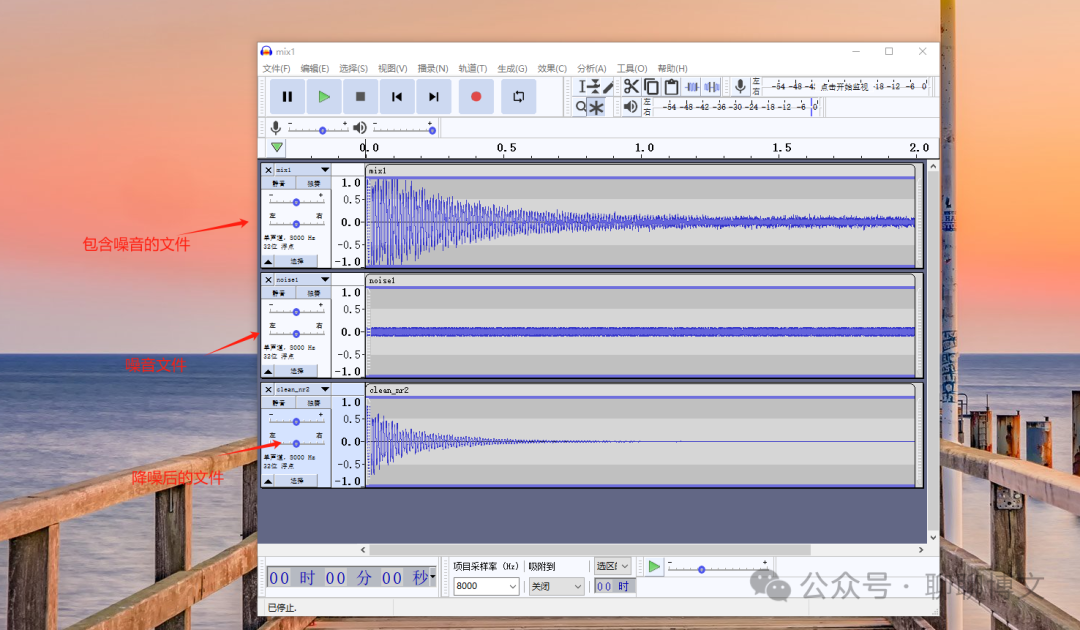
也可以使用标准降噪,提取音频特征文件后过滤,示例如下:
from scipy.io import wavfile import noisereduce as nr # load data rate, data = wavfile.read("mix1.wav") _, noise_data = wavfile.read("noise1.wav") # perform noise reduction reduced_noise = nr.reduce_noise(y=data, sr=rate, y_noise =noise_data, stationary = True, # this should be true #sigmoid_slope_nonstationary = 50, ) wavfile.write("clean_nr2.wav", rate, reduced_noise)复制
运行效果如下:
本文涉及源码及相关文件,可以从如下途径获取:
本文简要介绍了Java 把多个音频拼接成一个音频的方法,给出了一个基于JLayer(用于MP3)和TarsosDSP(一个音频处理库)的简化示例,并给出了详细的代码示例。