在这里同步一篇本人的原创文章。原文发布于2023年发布在知乎专栏,转移过来时略有修改。全文共计3万余字,希望帮助到GEE小白快速进阶。
这篇文章主要解答GEE中.map()和.iterate()函数的用法。
首先解答一个疑问,为什么需要自己写循环?确实,GEE 为各种数据类型提供了无数常用的内置函数,对这些方法做排列组合足以应对大多数使用场景,算法效率也颇佳。在有内置函数的情况下,我永远推荐内置函数。
然而,对策赶不上需求,总有时候需要部署个性化的算法。举个例子,数据聚合问题:现有一个小时级的气温数据集 hourlyTemp_imgcol,每小时整点提供一张近地表气温图像,要求借此生成一个每日平均均气温数据集 dailyTem_imgcol,每天提供一张日均近地表气温图像。那么,GEE 有没有这样的内置函数:
var dailyTemp_imgcol = hourlyTemp_imgcol.aggregate('daily');
让我们一行代码出结果呢?没有。
以上的例子是细分学科下的任务,听起来还是挺稀罕的。那我就再举一个编程初学者一定会接触的算法,数列递推:由一个初始值按照一定的递推公式,生成一个固定长度的列表。GEE有没有类似这样的递推函数:
var List = Number.RECURSIVE_SEQUENCE(function, list_length);
来一步到位实现这个简单任务呢?很遗憾,也是没有的。
因此,尽管 GEE 内置函数库丰富,学会自己部署循环仍然很有必要。这是跨过初学者阶段、独立开展项目的必经之路。
在第一个例子中,我们需要按时间循环,每个日期计算一幅平均气温图像。在第二个例子中,我们需要按列表索引位置循环,每个索引位置上计算一个递推值。
第一个例子代表了一类问题,处理函数作用在每个元素上,让每个元素被映射到一个新的东西上,这样的话一定是多个输入和多个输出,并且有一一对应的关系。关于这种循环,我们使用.map()操作来处理,请阅读本文第(一)节。
第二个例子代表了另一类问题,处理函数的任务是产生累积的效果,后面步骤的执行会依赖前面步骤的产出。关于这一种循环,我们使用.iterate()操作来处理,请阅读本文第(二)节。
有些初学者会说,哪里需要那么麻烦,我以不变应万变,老师教的for循环就是无脑易上手,再说GEE又不是不支持。我想说,这种习惯在技术上确实可行,但是如果是放在 GEE 上部署,会严重拖慢计算效率。在展示如何写 GEE 式循环之前,我专门开一个第(〇)节,探讨一下这个问题。非常建议初学者阅读,会帮助你更好地理解,GEE 如何处理用户提交的任务。
然而并不是说任何情况都不能使用for循环。 有些情况下,因为.map()和.iterate()的技术限制,循环必须在本地端进行。我会举一下这种应用场景的例子,放在第(三)节。
让我们开始吧。
GEE 常被描述为“地理云计算平台”。那么,之所以被称为云计算,就是因为操作和计算是在服务器上发生的,而不是在自己的电脑(本地)上完成的。向服务器告知计算任务时所用的“语言”,称为API。目前已有JavaScript API(即Code Editor)、Python API、Julia API。
-- 那么老哥,for和while是跟GEE服务器对话的语言吗?
-- 不是。
-- 难道说GEE服务器不看for语句?
-- 它不看。
-- 唉不对啊,我明明在Code Editor上面写了for循环却还能运行的,你说服务器不看for,难不成还能是浏览器给我跑的?
-- 恭喜你答对了,还真是浏览器给跑的。
要解释这个问题,需要对GEE的工作机制有一个大概的了解。
作为小白,我们在Code Editor上写出几行代码并点击Run的一刻,可能很少想过这之后发生了什么。实际上,你的代码其实并不是直接抄一份送给服务器去读,而是要先在本地端浏览器上去做解析,重写成一套服务器听得懂的请求,然后才把请求送上去。
本地翻译的过程,在于解析每一个由用户声明的变量,把它们各自整理成一套能指导服务器算出结果的结构——你可以理解成是每一个云端对象在本地端的代理,是影子。它们会跟云端的、承载实际数据和计算的对象相对应。
在《Deferred Execution(延迟运行)》的页面上[1],谷歌解释了这一本地解析的过程:
When you write a script in Earth Engine (either JavaScript or Python), that code does NOT run directly on Earth Engine servers at Google. Instead, the client library encodes the script into a set of JSON objects, sends the objects to Google and waits for a response. Each object represents a set of operations required to get a particular output, an image to display in the client, for example.
当您在Earth Engine上编写脚本时(无论JavaScript还是Python),该代码不会直接在谷歌的Earth Engine服务器上运行。相反,客户端库将脚本编码为一组JSON对象,将对象发送给谷歌并等待响应。每个对象表示获得特定输出所需的一组操作,例如,要在客户端上显示的图像。
进一步解释一下:代码写好之后,只会在本地做解析。本地端解析之后,会生成一些JSON对象。这些JSON对象是做什么用的呢?是客户端写给服务器的字条:“如此如此算一遍,把结果发给我。”
由此可以看出,本地端解析代码所能做的,只是解析代码,帮服务器提前理解该怎么做事而已,不涉及任何实际数据。它编写的JSON文件,只是云端数据在本地端的影子。生成这个影子的目的,或者说这个影子里所容纳的信息,就是指挥Google服务器以某某运算组合依次操作那个云端上的对象。
这样就解释了为什么for循环只在本地端有意义。我们在for循环里写的一切,是一种过程而不是一种对象,只会平添本地端的解析负担。for循环对服务器上计算过程产生影响之前,是要本地客户端来徒手拆循环的。
说句题外话,这其实很像在编纂纪传体史书。历史的原始记录就像我们写的代码一样,关注的是事情从头到尾怎么进行,是一种过程。而纪传体史书则关注主要人物个体如何发展,这更像GEE服务器的关注点,是一种对象。把流水账般的事项记录(过程),编制成人物个体的发展历程(对象及其操作顺序),并对互相影响的人物各自立传、一起成书,这些就是史官(和GEE API)的工作。
理解了本地端和服务器端对象的区别和联系,让我们再来讨论以for为代表的本地端循环,为什么不被推荐。
举个例子,我们这里有一个重复1万次的for循环,里面的内容是让一个ee.Number(服务器端的数)每次加 i:
// 语法没错但跑不通的例子,只是因为用了 for 循环
var num = ee.Number(0);
for (var i=1; i<=10000; i++) {
num = num.add(i);
}
print(num);
已知服务器不看也看不懂for循环,那么这个拆循环的工作,一定是在本地完成的。浏览器需要认真的把1万次迭代走完。然而,它在迭代时可不是替服务器执行实际计算,而是在字条里写一步请求:嘿服务器,这一步,你执行加 i 操作。于是它把这句话又写了9999次。在循环结束时,它出的活将是一个超长的、一万个处理步骤的字条。
这就是浏览器上的客户端API在面对for循环时负担的压力。浏览器表示写字条太苦逼了,求求你还是让我来算数吧。
看着是不是替自己的浏览器捏把汗呢?实际上,这个代码在我的电脑上根本跑不通,因为这个预计超长的JSON对象,是超出了我的浏览器写字条的能力的(报错:Maximum call stack size exceeded)。
一旦选择去写for循环,那么制约代码运行效率的因素,就不在于服务器的计算速度了,而是本地端的翻译能力。而这还不是最差的情况。最不推荐的做法是for循环中还带有.getInfo()函数,向服务器请求发回这一步计算结果,它让本该只是影子的本地变量取回它在服务器端对应的值。这个函数会打断异步计算的工作方式,在当前值被发送回本地前,一切其它步骤的计算都不能接着进行,同时服务器也闲置了。如果被套进很多层for循环中,用户实际的感受就是,本地等待时间非常长,浏览器无响应(甚至提示崩溃)。
反面案例:
// for 循环与 getInfo 合用则是更大的错误!
// 以下代码能跑通,但亲测可以让浏览器卡死数十分钟
// 不要运行!!!
var num = ee.Number(0);
for (var i=1; i<=10000; i++) {
num = ee.Number(num).add(i).getInfo();
}
print(num);
那么,使用.map()和.iterate()就能绕过这个问题吗?是的。这是因为,它们两个都是服务器端的函数,是服务器可以直接读懂的东西。这样一来,调用它们也就无需让客户端去拆循环,只需一次解析,剩下的事情就交给服务器了。浏览器压力大减。
要是for和while循环哪怕尚有一成的用处,我的这篇文章也就没有什么必要了。但我可以拍着胸脯说,除了极少数情况(见第三节),都是可以寻找到对本地循环的替代方案的。这里推荐阅读GEE的官方教程文档《Functional Programming Concepts》[2](函数式编程的概念),教你把习惯的过程式编程做法(for循环、if/else条件语句、累积迭代)重构为适合GEE的代码。
有多个类型的 ee 对象都带有.map()操作:ee.List(列表),ee.Dictionary(字典),ee.ImageCollection(图像集),ee.FeatureCollection(要素集)。借用Python语言中的概念,它们都是可迭代对象iterables。ee.List和ee.Dictionary类似于Python的List和Dictionary。ee.ImageCollection和ee.FeatureCollection则非常类似于Python的集合,set。
巧的是,在Python中也有一个map函数处理可迭代对象,用法如下,是一个让数列逐项加1的脚本。
""" map(fun, iter)
\* fun - 处理函数,map将每个元素传递给它
\* iter - 可迭代对象,map作用于它的每个元素上
"""
list1 = [1, 2, 3, 4]
list2 = list( map(lambda x: x+1, list1) )
list2 # [2, 3, 4, 5]
这个脚本,放在 GEE Code Editor 中的话,应该这样写:
/** ee.List.map(baseAlgorithm)
* this: list - 输入对象,此例中为列表,map作用于它的每个元素上
* baseAlgorithm - 处理函数,map将每个元素传递给它
*/
var list1 = ee.List([1, 2, 3, 4]);
var list2 = list1.map(
function(x){
return ee.Number(x).add(1);
}
);
print(list2); // [2, 3, 4, 5]
可以看到,map和.map()在两个平台上有着一样的本质功能,都是逐个元素处理,逐一映射。也就是说,把处理函数作用在输入对象的每个元素上,并且在输出对象中创建一一对应的新元素。
二者在编写结构上有一些细节上的差别:
map是在它的括号里套起来处理函数和输入对象。而GEE中的.map() 则只套处理函数,跟在输入对象后。map可以同时传递进来多个可迭代对象(以上示例中没有展示),而GEE的.map()则只能处理一个对象。lambda语句创建匿名函数,而GEE Code Editor用function语句。由于采用function语句,GEE Code Editor用户可以在.map()的括号里写一个带更多步骤的匿名函数(以上示例中没有展示)。map的直接输出是一个map object,需要用container套起来去赋予类型,比如写成 list(map(...)) 。而GEE中的.map()则返回一个与输入对象类型相同的对象,进来是什么类型出去就还是什么类型。这种处理是并行化进行的。在上面的例子中,我们并不关心是数字1先被处理,还是数字4先,只在乎它们被处理完后有没有被摆在正确的位置。4个数字或许是同时被各自送入不同的 CPU 核,同时被输出,同时被填放。又或许是先处理3个,再处理1个,齐活之后再一起上菜。又或许是先处理2个再处理2个……具体怎么调度的,那是后台的事,对我们用户其实毫无影响。
但值得放在脑子中的信息是,这种处理不会是像for循环那样,一个一个依次操作,而是以并行化的方式提高效率。记住这一点,后面要考的。
简单的.map()操作常用于对图像集中的图像、要素集中的矢量要素作批量处理,编辑、处理后,生成对应的新数据。在更复杂的情况中,通常是自定义的特殊处理任务,我们需要以给定的时间、空间、或关键字等信息为依据,对其它数据作聚合,如统计日平均气温,即气温数据在时间维度的聚合。对于这两种.map()操作的应用场景,这里给出例1和例2两个假想的数据处理任务以供参考。
这里给出的例子是对于图像集(ee.ImageCollection)进行批量编辑。对要素集(ee.FeatureCollection,或者称矢量集)的批量编辑虽然在任务性质上会有差异,但在对.map()的使用方式上同理,所以就不予赘述了。
我们设想这样一种任务,对图像集里的每一个图像,都进行一次掩膜操作,把不想要的像元筛除掉。这样的任务常见于定量遥感,常常是数据准备阶段中的一步预处理。掩膜图层常常是特定的土地覆盖类型(如森林、水体、农田),或气候条件阈值(如温度、降水量),或有云/无云的位置。我这里举两个非常最常用的Landsat预处理操作:1. 使用质量控制波段,对Landsat 8地表反射率数据集进行掩膜。2. 使用官方给定的放缩乘数(scale factor)和偏置(offset),将数据集里的源数据转换成能够使用的地表反射率。
首先,取得Landsat 8地表反射率数据集(注意是Collection 2)。这里仅取同一个地点上2个月的图像,一共4张,因为取多了处理时间会拉长。4张图像的云量分别为:89.8%,0.05%,21.39%,75.44%。
/////////////////////////////////////////////////////////////
// 获取Landsat 8 Collection 2 Tier 1地表反射率(Level 2)图像集
// 获取到的图像ID及云量:
// LANDSAT/LC08/C02/T1_L2/LC08_012031_20210711 - 89.8%
// LANDSAT/LC08/C02/T1_L2/LC08_012031_20210727 - 0.05%
// LANDSAT/LC08/C02/T1_L2/LC08_012031_20210812 - 21.39%
// LANDSAT/LC08/C02/T1_L2/LC08_012031_20210828 - 75.44%
var landsat8 = ee.ImageCollection("LANDSAT/LC08/C02/T1_L2")
.filter(ee.Filter.and(
ee.Filter.eq('WRS_PATH', 12),
ee.Filter.eq('WRS_ROW', 31)))
.filterDate('2021-07-01', '2021-09-01');
其次,写一个函数来实现:对一幅输入进来的Landsat 8图像,利用它自身的质量控制波段,去除云和云影。质量控制波段是一幅数值图像。在二进制化后,它的每一个(或2个)数位指示像元质量的某一个属性。我们需要第1至第4数位,分别是dilated cloud(检测到的云范围的放大范围)、cirrus cloud(卷云)、cloud(明显的云)、cloud shadow(云影)。
/////////////////////////////////////////////////////////////
////////////// 云掩模函数 //////////////
function prep_l8 (l8_image) {
// 转换成图像,以保证数据类型正确
l8_image = ee.Image(l8_image);
// 使用QA数位1-4,构建掩模图层(取1是不受云影响的像元,取0是受云影响的像元)
// Bit 0: fill (0)
// Bit 1: dilated cloud
// Bit 2: cirrus cloud
// Bit 3: cloud
// Bit 4: cloud shadow
var l8_qa = l8_image.select("QA_PIXEL");
var dilated_cloud_mask = l8_qa.bitwiseAnd(1 << 1).eq(0);
var cirrus_cloud_mask = l8_qa.bitwiseAnd(1 << 2).eq(0);
var cloud_mask = l8_qa.bitwiseAnd(1 << 3).eq(0);
var cloud_shadow_mask = l8_qa.bitwiseAnd(1 << 4).eq(0);
var mask = dilated_cloud_mask
.and(cirrus_cloud_mask)
.and(cloud_mask)
.and(cloud_shadow_mask);
// 放缩和偏置,并恢复在乘法加法中丢失的元数据(metadata)
var scale = 0.0000275;
var offset = -0.2;
var l8_image_scaled = ee.Image(l8_image.multiply(scale).add(offset)
.copyProperties(l8_image))
.set(
"system:id", l8_image.get("system:id"),
"system:version", l8_image.get("system:version")
);
// 掩模并返回图像
var l8_image_scaled_masked = l8_image_scaled.updateMask(mask);
return l8_image_scaled_masked;
}
接下来执行批量编辑,也就是让上面的处理函数作用在图像集的每个图像身上。具体的写法,是让.map()括起来处理函数的名字(或者可以在.map()里写函数),再跟随在待处理的图像集后面即可。
/////////////////////////////////////////////////////////////
// 批量预处理,显示结果
landsat8 = landsat8.map(prep_l8);
var visualization = {
bands: ['SR_B4', 'SR_B3', 'SR_B2'],
min: 0.0,
max: 0.1,
};
Map.addLayer( ee.Image(landsat8.toList(10).get(0)), visualization, "2021-07-11" );
Map.addLayer( ee.Image(landsat8.toList(10).get(1)), visualization, "2021-07-27" );
Map.addLayer( ee.Image(landsat8.toList(10).get(2)), visualization, "2021-08-12" );
Map.addLayer( ee.Image(landsat8.toList(10).get(3)), visualization, "2021-08-28" );
显示这4张经过预处理后的图像。可以发现,我们用一步操作为4张图像去除掉了受云影响的像元,可以说.map()的老本行是GIS数据批量处理实在不为过。

GEE 上能实现的聚合不仅限于求和。做乘积、求平均、求方差、找极值等等,只要用得上就都能做。我们这里以求平均为例子说明做数据聚合的技巧。
在时间维度上做数据聚合,输入到算法中信息有两个:时间集、数据集。不同于在批量编辑操作中的做法,我们这回不能再让.map()当数据集的“跟屁虫”,而是要转而去跟随时间集。
原因很好理解。.map()操作,输入输出的维度必须是相同的。我们如果想实现一个时间出一张图,那就必须让时间成为.map()的输入。(至于数据集,它可以去当处理函数的输入。这里有个非常好用的技巧我接下来会在处理函数代码处细说)
做法是把时间维度放到一个 ee.List 列表对象中。因为 ee.List 也带有.map()操作,我们的编程灵活性有了保证。
考虑到ee.List.map()的输出变量是另一个 ee.List,我们有必要对结果进行变换——重建所需的数据类型,比如转换成 ee.ImageCollection 或 ee.FeatureCollection。
这里展示的代码将实现我们在引言中提到的,将逐小时气温数据转换为每日平均气温。可以点击此链接在 GEE Code Editor 中查看。
首先,定义输入量:
var hourly_temp = ee.ImageCollection("NOAA/NWS/RTMA").select("TMP");
var dates = ee.List([
ee.Date('2022-01-01T00:00:00', 'EST5EDT'),
ee.Date('2022-01-02T00:00:00', 'EST5EDT'),
ee.Date('2022-01-03T00:00:00', 'EST5EDT')
]);
然后,定义处理函数。在每一个日期上,这个函数要实现三个步骤:首先对 hourly_temp 图像集做筛选,然后对筛选后的图像集作聚合生成一张均值图像,最后重命名均值图像。
/**
* 本函数构造一个内函数并返回
* 使内函数满足ee.List.map()对处理函数格式的要求
*/
function calc_daily_mean(imgcol) {
/** 在内函数中完成处理 */
return function(idate) {
idate = ee.Date(idate);
/** 第一步:对图像集按日期做筛选 */
var filtered_imgcol = imgcol.filterDate(idate);
/** 第二步:对筛选后的图像集作聚合,生成一张均值图像 */
var mean_img = filtered_imgcol.mean();
/** 第三步01:提取原图像集的波段名称 */
var band_names = imgcol.first().bandNames();
/** 第三步02:用“原波段名称+年月日”重命名均值图像的波段,如:"TMP20220101" \*/
band_names = band_names.map(function(name){return ee.String(name).cat(idate.format('YYYYMMdd','EST5EDT'))});
return mean_img.rename(band_names);
};
}
终于可以把前面卖的关子揭开了。可以看到,处理函数的结构是,一个外函数返回一个内函数。为什么要这样设计呢?我们在引例中提到,GEE 的.map()则只能处理一个输入变量。这样就产生了矛盾,因为我们的数据聚合任务必须含有两个变量:时间集和数据集。当我们已经把时间集指定为.map()的输入时,数据集似乎就无处可去了。然而,假如我们稍微改造一下处理函数,写成这样的外函数套内函数、并返回内函数的结构,就可以做到让数据集输入到外函数,时间集里的日期输入到内函数。这样一来,可以同时满足两方面看似矛盾的要求。
使用这一处理函数的代码如下。第一输入——时间集 dates ——放在.map()的左侧。第二输入——数据集hourly_temp ——就让外函数括起来。然后,在整个语句的最外层,用ee.ImageCollection()套起来,把.map()的输出结果(原本是ee.List)转换成图像集。
var daily_temp = ee.ImageCollection(dates.map(calc_daily_mean(hourly_temp)));
最后,让我们在地图视图中查看一下算好的平均气温。另外,再生成一个颜色条方便阅读数据。
var vis = {
min: -30,
max: 20,
palette: ['001137','01abab','e7eb05','620500']
};
Map.addLayer(daily_temp.first(), vis, "2022-01-01 mean temperature");
Map.addLayer(ee.Image(daily_temp.toList(3).get(1)), vis, "2022-01-02 mean temperature");
Map.addLayer(ee.Image(daily_temp.toList(3).get(2)), vis, "2022-01-03 mean temperature");
var legendTitle = ui.Label({
value: 'Mean temperature (C)',
style: {fontWeight: 'bold'}
});
var legendLabels = ui.Panel({
widgets: [
ui.Label(vis.min, {margin: '4px 8px'}),
ui.Label(
((vis.max-vis.min) / 2+vis.min),
{margin: '4px 8px', textAlign: 'center', stretch: 'horizontal'}),
ui.Label(vis.max, {margin: '4px 8px'})
],
layout: ui.Panel.Layout.flow('horizontal')
});
var colorBar = ui.Thumbnail({
image: ee.Image.pixelLonLat().select(0),
params: {
min: 0,
max: 1,
palette: vis.palette,
bbox: [0, 0, 1, 0.1],
},
style: {stretch: 'horizontal', margin: '0px 8px', maxHeight: '24px'},
});
Map.add(ui.Panel([legendTitle, colorBar, legendLabels]));
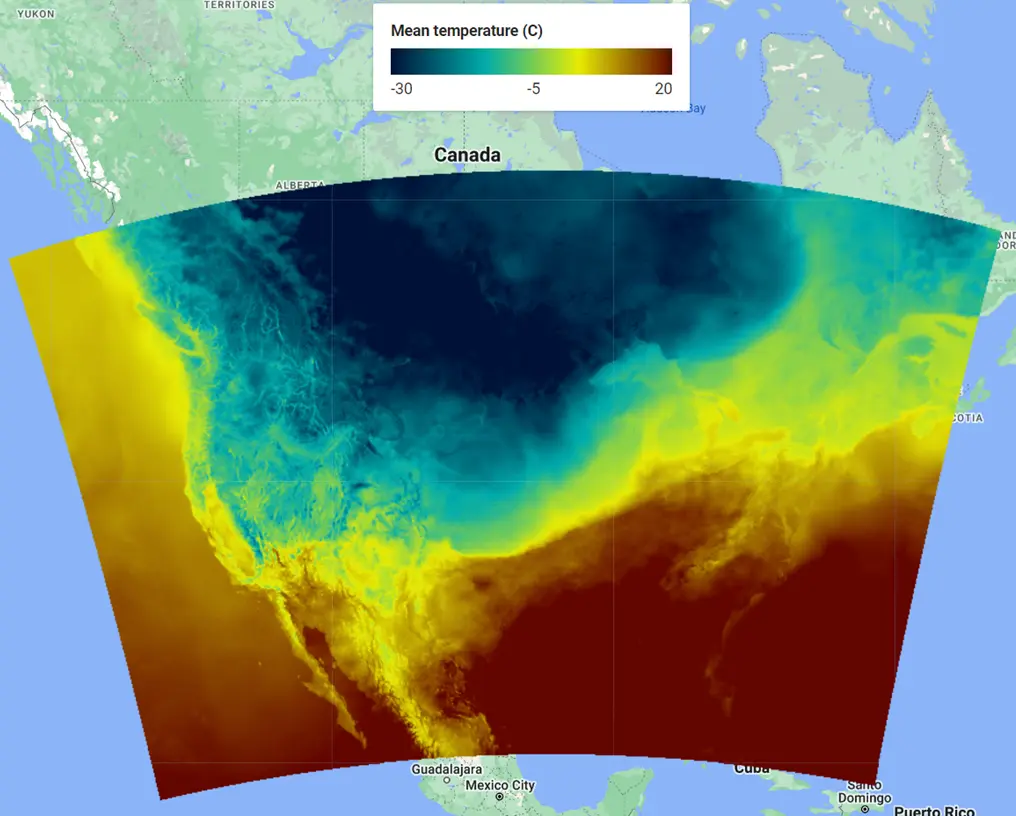
美国大陆部分2022年1月1日平均气温地图。

2022年1月2日
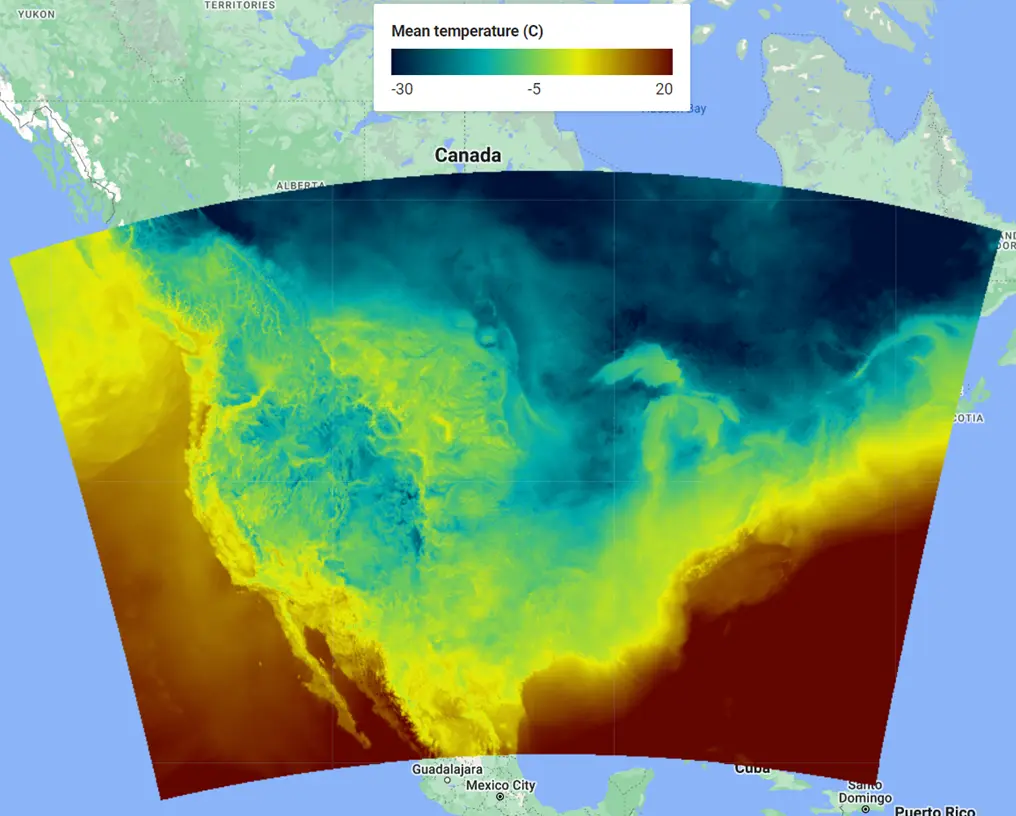
2022年1月3日
在GEE上使用.map()时,有必要牢记一些易错点。.map()里运行出的错,报错反馈可能不会指出问题出在了代码第几行,也许也无法提供足够精确的诊断信息(这可能是 GEE 最难用的地方,不过 GEE 似乎正在改进这一点)。把易错点烂熟于心,至少对于debug是很有帮助的。
首先,输入对象和元素类别的问题。.map()的输入变量类型只能是 ee.List、ee.Dictionary、ee.ImageCollection、ee.FeatureCollection 四者之一。除了这些ee对象以外,不能对其它类型使用.map()。并且,输入对象中的元素经由.map()送入处理函数中时,一律都会被服务器理解成一个“没有类型的”云端对象 ee.ComputedObject,而不是原本的类型,所以在处理函数中需要为元素重新定义对象类别。
比如,引例中 ee.List 的元素,在使用.add()进行处理之前,需要被定义成 ee.Number。即使我们把输入列表中的对象都写成 ee.Number,在被送入处理函数后也仍然会“失去”类型——见下方的错误程序及其报错。
/** 这是一个错误示例 */
/** 说明数值元素在送入处理函数时没有被理解为ee.Number,而是需要重新定义 */
var list1 = ee.List([ee.Number(1), ee.Number(2), ee.Number(3), ee.Number(4)]);
var list2 = list1.map(
function(x){
return x.add(1); // 正确写法:return ee.Number(x).add(1)
}
);
print(list2); // 报错:"x.add is not a function"
其次,本地端操作的问题。由于.map()循环是完全交给服务器运行的,它的处理函数里面不能写print、if、for这些程序员喜闻乐见的语句。一旦写上了就会弹出报错"A mapped function's arguments cannot be used in client-side operations"(映射函数的参数不能在客户端操作中使用)。print的问题实在解决不了,但是if和for还是有替代品的。例如ee.Algorithms.If可以实现if,不过更推荐的做法是用.filter()操作提前筛选好数据。要是手痒痒想写for的话,那就叠一个.map()或.iterate()循环好咯。
.map()适用于逐个元素处理、逐一映射的任务。.map()在 GEE 后台采用并行化的执行方式。.map()的两种常用场景:GIS数据的批量编辑,以及在时间、空间、或关键字等维度上进行信息聚合。前一小节中,我们讨论了.map()操作的适用范围——映射。细心的同学们可能已经发现了,.map()对元素的处理是一种各自独立的访问方式,顺序无所谓谁先谁后,只要处理好后放置顺序正确即可。因此,它的处理函数没有“步”的概念,也就不能产生按步累积的效果。
但是我们学习for循环时,还有一个很重要应用就是按步求累积啊,这可怎么办?
这就是.iterate()的功能了。.iterate()操作适用于那些需要考虑状态逐步积累、逐步改变的计算任务。
这里提供一个简单的判断标准,决定你该不该用.iterate()。如果你的问题必须拆解成子步骤逐步计算,且后步必须依赖前步的计算结果,那么它就是.iterate()的应对范围。反之,则优先尝试使用.map()。
适合用.map()去解决的问题较多,而非得用.iterate()的问题较少。.iterate()执行起来是完全按照规定好的1234步来做的。能用.map()去并行执行的任务非要写成.iterate(),倒也不是出不了结果,但属实是有点一核有难多核围观了。
带有.iterate()操作的对象类型有3个:ee.List,ee.ImageCollection,ee.FeatureCollection,比.map()少一个 ee.Dictionary。
调用.iterate()的代码格式比.map()繁琐一些。 .iterate()需要两个输入:处理函数 + 第一步循环开始前的初始状态,二者都是必须的输入量,后者是.map()没有的。同样繁琐的还有.iterate()对处理函数的要求:循环控制变量 + 前一轮的迭代状态(作为本轮迭代的基准)。
下文中给出用.iterate()实现做累积迭代的一些任务。例3是对存储在 ee.FeatureCollection 中的要素属性进行求和的例子。例4汇流算法是一个相当复杂的循环迭代过程,套在大一些的研究区上很容易超出GEE计算限制,因此不建议在GEE上部署。
这里举一个官方文档[4]中的例子。构造一个要素集(ee.FeatureCollection),其中每个要素以感兴趣区ROI为几何形状,以一个月份的月降水量为字段,共12个要素。.iterate()承担的任务是以迭代的方式对12个月降水量求和,得到感兴趣区内的年降水量。
https://developers.google.com/earth-engine/apidocs/ee-featurecollection-iterate
首先,数据源和感兴趣区。数据源选择了一个按月更新的气候数据集(图像集ee.ImageCollection),取一年期。感兴趣区选在美国新墨西哥州的一片区域。
/**
* CAUTION: ee.FeatureCollection.iterate can be less efficient than alternative
* solutions implemented using ee.FeatureCollection.map or by converting feature
* properties to an ee.Array object and using ee.Array.slice and
* ee.Array.arrayAccum methods. Avoid ee.FeatureCollection.iterate if possible.
*/
// Monthly precipitation accumulation for 2020.
var climate = ee.ImageCollection('IDAHO_EPSCOR/TERRACLIMATE')
.filterDate('2020-01-01', '2021-01-01')
.select('pr');
// Region of interest: north central New Mexico, USA.
var roi = ee.Geometry.BBox(-107.19, 35.27, -104.56, 36.83);
然后,使用分区统计的方式逐一构造矢量要素来存储月降水量,合成一个要素集。这里使用了.map()操作来实现对每一张月降水量图像出产当月的矢量要素。
// A FeatureCollection of mean monthly precipitation accumulation for the
// region of interest.
var meanPrecipTs = climate.map(function(image) {
var meanPrecip = image.reduceRegion(
{reducer: ee.Reducer.mean(), geometry: roi, scale: 5000});
return ee.Feature(roi, meanPrecip)
.set('system:time_start', image.get('system:time_start'));
});
以上都是准备阶段,下面进入正题。首先建立一个处理函数,名为cumsum,以当前要素(变量名currentFeature)为循环控制变量,以已经参与过月降水量加和的要素所组成的列表(变量名featureList,类型为ee.List)为前一轮迭代状态。处理函数所做的事情,是把已有的月降水量的和(featureList最尾端要素的“pr_cumsum”字段)和当前月份的降水量(currentFeature的“pr”字段)分别取出并求和,再新建一个要素赋予这个求和值,并把新建的要素添加到featureList列表中。
// A cumulative sum function to apply to each feature in the
// precipitation FeatureCollection. The first input is the current feature and
// the second is a list of features that accumulates at each step of the
// iteration. The function fetches the last feature in the feature list, gets
// the cumulative precipitation sum value from it, and adds it to the current
// feature's precipitation value. The new cumulative precipitation sum is set
// as a property of the current feature, which is appended to the feature list
// that is passed onto the next step of the iteration.
var cumsum = function(currentFeature, featureList) {
featureList = ee.List(featureList);
var previousSum = ee.Feature(featureList.get(-1)).getNumber('pr_cumsum');
var currentVal = ee.Feature(currentFeature).getNumber('pr');
var currentSum = previousSum.add(currentVal);
return featureList.add(currentFeature.set('pr_cumsum', currentSum));
};
为了使用这一处理函数,我们以上文中构造好的月降水量要素集为输入,并且再构造一个循环起始时的要素列表(变量名first,将“pr_cumsum”字段设置为0)。在循环结束后,卸磨杀驴,去除掉这个占位用的要素。
// Use "iterate" to cumulatively sum monthly precipitation over the year with
// the above defined "cumsum" function. Note that the feature list used in the
// "cumsum" function is initialized as the "first" variable. It includes a
// temporary feature with the "pr_cumsum" property set to 0; this feature is
// filtered out of the final FeatureCollection.
var first = ee.List([ee.Feature(null, {pr_cumsum: 0, first: true})]);
var precipCumSum =
ee.FeatureCollection(ee.List(meanPrecipTs.iterate(cumsum, first)))
.filter(ee.Filter.notNull(['pr']));
由此我们可以画出这样的年内降水量曲线。蓝线表示月降水量,红线表示累积降水量。这样一来,我们借助.iterate(),给for循环的迭代求和功能找到了替代。

在以上例子中我们利用.iterate()以一种迭代的方式去对所有要素按一个字段求和,然而这并不是唯一的实现方式。实际上,如果只想要对字段求和(但不要求同时给出逐时累积曲线)的话,GEE有内置函数.aggregate_sum(property)提供相同的功能,不必要自己编写迭代代码。
实际上,很多我们直觉上认为需要写累积循环的情况,GEE都贴心的提供了内置函数。内置函数不光调用更方便,而且往往运行更快。
注:GEE上已入库全球90米级别的MERIT Hydro数据集[5]。如果不追求更高分辨率,建议直接使用现有产品,无需亲自运行汇流算法。
汇流问题地形分析中的经典老问题,但也是一个需要巨量迭代、狂吃内存和时间的老大难技术性问题。
汇流问题通常是这样的:已知一片感兴趣区的DEM图像,要生成一张新图像,使得每个像元的值取该位置所对应的集水区(catchment area,或catchment basin)的面积。集水区的定义:对于地表上任何一个地点而言,凡是落在它邻近某个区域内的雨水,经过不断汇聚和流动都会流到这个地点,这个雨水降落和汇流的区域就称为该地点的“集水区”。落在这个集水区边界以外的雨水,不论怎样流动,都不会经过这个地点[6]。

集水区的概念图(图源:Nazhad et al., 2017 [7])。任意一个地点(图上小红点和大红点)都可以有各自对应的集水区(黄圈和绿圈)。一般来说,上游地点拥有的集水区面积较小,下游地点拥有的集水区面积更大。分析集水区有助于推断河流的形成。
那么这个汇流问题,有什么难点呢?
思考一下简化版的问题,为一个像元,我们称为A,圈出它的集水区,不能圈多不能圈少。这等同于需要标记全场其它像元BCDEFG…,哪些能给像元A送水,哪些不能。
似乎,是不是要遍历全场像元呀?是的,而且不止一遍。首先,对任意像元BCDEFG…,要规划水落在该位置上可能的流向。为了简化,我们假设水只会选择向8-邻接像元流动,并且只会选择其中的1个像元为流动方向,也就是下坡坡度最大方向的那个像元。所以在第一次遍历中,我们需要在全图范围上,逐像元按照邻域地形确定下坡坡向。这张坡向图告诉我们的是,水落下来后紧接着的下一步,只有一步哦,的流动方向。
有了坡向图/流向图,能顺水推舟圈集水区了吗?可以了。思路是,在A的邻域里逆向查找流向指向A的像元,标记下来。再对新标记的所有像元,执行同样的查找过程,再标记新一批像元,以此类推。直到标出范围外,或者标无可标(延伸到了流域边界),则停止。停止这个逆流追溯过程后,把已标记的全部像元转换成像元总数(或总面积),赋值给A。
所以,为解决一个像元相应集水区的简化版问题,我们要开动一次追溯。在这个过程中,全场像元被遍历了几遍,取决于客观上有多少个像元给A送水。只要上一步的追溯还能发现新像元,哪怕一个,卷积核就得给我再接着滑。

汇流问题的示意图,DEM -> 流向图 -> 集水区。此例子中为所有像元都统计集水区。图源: [8]
上文所述,是为一个像元圈出集水区的思路,它只是为了方便向大家说明算法需要考虑的基本问题。事实上,为全场像元都统计集水区,并不需要逐个像元跑追溯,那样会产生太多重复步骤,浪费计算资源。优化的方式,是把下游向上游“追溯”的思路,切换成上游向下游“传播”的思路。第一次迭代中,每个像元向处在自己流向/坡向的唯一邻居像元,告知自己的存在(或自己的面积),而接收了信号的像元需要对信号求和。第二步及之后的每次迭代中,还是向同样的下游邻居像元通信,但告知内容变成,自己在上一步(且仅在上一步)中收集到的、来自更上游像元的通信总数(或总面积)。这样,来自上游的“信号”逐渐向下游传递且被累加起来,每个像元都能在一个迭代步中更新当前已经发现的上游像元总数(或总面积),且不会出现重复计数。直到所有最上游像元的信号都传递到各自相应的最下游,结束循环。
但是,技术上减少计算量的手段,并不能改变汇流问题需要反复执行迭代操作的本质。科学家针对这一问题提出过很多种算法以求优化这一问题的解决方案,但该问题上仍然缺乏简单高效的对策。在对范围广大、分辨率高的DEM数据做处理时,汇流算法的处理时间能以十小时甚至百小时为单位。
这里姑且把“传播”算法的实现方式给贴出来。纯粹是为了技术展示,并不是真的号召大家在GEE上写这种东西。
汇流算法的GEE代码来自GIS Stack Exchange论坛上的问答[9][10],作者为用户Bert Coerver,转载代码请注明原始出处。
首先,作者手动添加了一个感兴趣区,位于印度。
var geometry1 = ee.Geometry.Polygon(
[[[81.32080078125, 19.114029215761995],
[80.958251953125, 18.999802829053262],
[80.947265625, 18.672267305093758],
[81.71630859375, 18.396230138028827],
[82.09808349609375, 18.747708976598744],
[82.02667236328125, 19.072501451715087]]]);
这里我需要注明一下,汇流算法的作用区域,一般要至少覆盖一整个流域,否则集水区面积的计算结果是会偏小的。这里代码作者随手画的这个范围应该是没有覆盖流域,因此计算结果仅供教学,可能不具备现实中的指示作用。

感兴趣区示意图,由代码作者Bert Coerver标画
其次,定义输入量:
data的图像,用作上文所述的自上而下传播算法的初始迭代量。// Set the number of routing iterations:
var iteration_steps = ee.Number(120);
// Give an image with some data to rout:
var data = ee.Image(1);
// or E.G.: data = ee.Image.pixelArea().divide(1e6);
// Give the bandname from 'data' to rout:
var bandname = ee.String("constant");
// or E.G.: var bandname = ee.String("area");
// Give unit of the data:
var unit = "pixels";
// or E.G.: unit = "km2";
// Give image with flow directions:
var dir = ee.Image("WWF/HydroSHEDS/30DIR").select(["b1"]);
// Set Area-Of-Interest:
var geom = geometry1;
// Set output data type:
var typ = "uint32";
接下来,重命名迭代量data图像的波段为“rout”(可能是单词route/routed的简写),该波段的初值为1,即1个像元,用户可以自行在上方代码中改用像元面积为计量。复制rout波段,创建一个新波段赋给data图像,重命名为“summed”,这样summed波段初值也为1(或自身像元面积)。
rout波段可以理解成每个像元在当前步骤持有的“信号”,它或来自自身初始化或来自上游传入,并且这个信号将在后续步骤中传递出去。summed波段可以理解为,每个像元已发现的汇流像元数量或面积(自身也算,如果不想算自身的话,summed可以赋初值为0)。
// Rename the band.
data = data.select([bandname],["rout"]);
// Add a band to store the summation of the routs.
data = data.addBands(data.select(["rout"],["summed"]));
// Set property indicating the current iteration step.
data = data.set("iter_idx", 0);
借用ee.FeatureCollection创建表格(矢量数据的属性表)的能力,创建一个集合来定义方向。这里面每个矢量要素都不含地理参考信息(geometry字段为null),因此是“伪要素”,我们专注于属性表里的信息即可。
// Create a feature-collection that describes to what directions (e.g. 128 is NE).
var col = ee.FeatureCollection(ee.List([
ee.Feature(null, {"weight": ee.List([[0,0,0],[1,0,0],[0,0,0]]),
"direction": "E",
"dir_id": 1,}),
ee.Feature(null, {"weight": ee.List([[1,0,0],[0,0,0],[0,0,0]]),
"direction": "SE",
"dir_id": 2,}),
ee.Feature(null, {"weight": ee.List([[0,1,0],[0,0,0],[0,0,0]]),
"direction": "S",
"dir_id": 4,}),
ee.Feature(null, {"weight": ee.List([[0,0,1],[0,0,0],[0,0,0]]),
"direction": "SW",
"dir_id": 8,}),
ee.Feature(null, {"weight": ee.List([[0,0,0],[0,0,1],[0,0,0]]),
"direction": "W",
"dir_id": 16,}),
ee.Feature(null, {"weight": ee.List([[0,0,0],[0,0,0],[0,0,1]]),
"direction": "NW",
"dir_id": 32,}),
ee.Feature(null, {"weight": ee.List([[0,0,0],[0,0,0],[0,1,0]]),
"direction": "N",
"dir_id": 64,}),
ee.Feature(null, {"weight": ee.List([[0,0,0],[0,0,0],[1,0,0]]),
"direction": "NE",
"dir_id": 128,})]));
⬆可以看到,“direction”和“dir_id”字段,正是对照着HydroSHEDS水流流向数据集对于流向/坡向的定义,但“weight”字段中的矩阵则是反过来的。比如,[[0,0,0], [1,0,0], [0,0,0]]应该指向西,却对应于“东”。这样设计是因为,上游像元向下游像元传播信号的过程,实际上是靠下游像元的主动收集来实现的(图像卷积操作)。上游像元向东发送的信号,需要下游像元从西面去接收。“direction”和“dir_id”字段所定义的是信号发送的去向,而“weight”字段定义的则是信号接收的来向。有必要说明一下这个问题以免产生疑惑。
最内核的部分来了:传播算法的执行函数。每一步迭代时,正是这个函数来把“信号”向下游移动一步。
// The iteration algorithm.
var iterate_route = function(iter_step, data){
// The function to do one routing iteration for one direction.
var route = function(ft){
// Create the kernel for the current flow direction.
var kernel = ee.Kernel.fixed({width: 3,
height: 3,
weights: ft.get("weight")
});
// Get the number corresponding to the flow direction map.
var dir_id = ee.Number(ft.get("dir_id"));
// Mask irrelevent pixels.
var routed = ee.Image(data).select("rout").updateMask(dir.eq(dir_id));
// Move all the pixels one step in the direction currently under consideration.
var routed_dir = routed.reduceNeighborhood({reducer: ee.Reducer.sum(),
kernel: kernel,
skipMasked: false
});
return routed_dir;
};
// Loop over the eight flow directions and sum all the routed pixels together.
var step = ee.ImageCollection(col.map(route)).sum().rename("rout")
.reproject(dir.projection())
.set("iter_idx", iter_step)
.clip(geom);
// Sum the newest routed pixels with previous ones.
var summed = step.select("rout").add(ee.Image(data).select("summed")).rename("summed");
// Add the 'rout' and 'summed' bands together in one image.
var data_next_step = step.addBands(summed);
return data_next_step;
};
⬆可以看到,这个大函数iterate_route里嵌套了一个小函数route。小函数的输入是八方向之一,作用是实现所有像元集体朝一个方向收听一次,判断该方向上是否是一个上游像元,收集上游像元带多少信号。让小函数对我们的八方向集合中的每个方向逐一处理(用.map()实现),并对结果求和,也就实现了信号的一次从上游到下游的传播。由传播的结果重建rout波段。传播完成之后,把rout波段和summed波段求和,用来更新summed波段。
推演一下,对于 i 取任意值,第 i 步迭代之后,来自信号都向下游流动一步,汇集到了下游像元的rout和summed波段中。而没有信号流入的像元(可能是因为自身处在最上游,或是因为自身的上游邻居在第 i-1 步没有更上游的信号流入),则在第 i 步之后rout值为0(这意味着第 i+1 步迭代时无法向下游传递信号),summed值不变。
定义好执行函数后,就只需调用.iterate()执行即可。创建一个名为steps的数列,取值1至120。以steps规定的步骤,按步运行执行函数iterate_route。将输出图像的数据类型转换成32位整型。
// Create dictionary to cast output to the chosen datatype.
var cast = ee.Dictionary({"rout" : typ,
"summed": typ});
// Create the list with iteration step numbers.
var steps = ee.List.sequence(1, iteration_steps);
// Do the actual iterations.
var full = ee.Image(steps.iterate(iterate_route, data)).cast(cast);
最后,在地图窗口上展示汇流算法的输出结果。
// Add Layer to Map
Map.addLayer(full.select("summed"), {min: 0, max: 1000}, "summed");
Map.centerObject(full.select("summed"))

汇流算法给出的各像元集水区,计量方式:像元个数。黑色像元约为1-100,灰色像元值数百,亮白色像元1000以上。
后续:在GEE上运行汇流算法,尤其需要注意预设一个合适的迭代次数。因为GEE的.iterate()函数不存在类似break或continue那样跳过或提前中断循环的语句,所以迭代次数就成为了关乎任务规模的唯一控制量。如果预设的太少,传播没有完成就结束了循环,集水区计算就会偏小。如果预设的太大,传播完成后的那些迭代次数就成了没有必要的空转,严重浪费时间。建议提前估算出全流域内最长的一条汇水路径的长度,并将迭代次数设置为略大于这条路径上的像元数量。并且,在算法的输出里,建议加上标记传播当前状态的rout波段,作为算法结束后校验传播是否已经客观完成的参考依据。
另外,需要提醒注意,运行时间过长、内存占用过大的任务可能无法在GEE上顺利运行。运行汇流算法时,流域范围不宜过大、空间分辨率不宜过高。虽然GEE没有公布过给每个用户的内存配额,或是运行时间的上限(经验值是12小时),但GEE官方开设的开发者讨论区经常有汇报相关报错信息的帖子。对于那些需要运行大流域、高分辨率汇流算法的朋友们来说,GEE也许不是非常稳妥的选择。如果90米分辨率可以接受的话,GEE已经入库的MERIT Hydro数据集[5]可以直接拿来使用,该数据提供像元数量和面积两种集水区计量方式,并且覆盖全球。
.iterate()适用于需要考虑状态逐步积累、逐步改变的问题。在不需要按步执行的循环问题上,应该优先使用.map()去实现。.iterate()的替代函数。优先使用GEE内置函数以提高计算效率。.iterate()的输入量有两个:执行函数 + 第一步循环开始前的初始状态。.iterate()要求执行函数的输入量为:循环控制变量 + 前一轮迭代状态。输出量为本轮迭代状态。.iterate()不支持跳过或中断循环,预估任务所需的迭代次数并设计输入变量的元素数量很重要。.map()的易错点,比如在处理函数中需要为元素重新定义对象类别、不支持本地端操作,对.iterate()同样适用。在第(〇)节中,我曾苦口婆心地劝大家不要用for循环,甚至为此不惜冒着被大家左滑退出的风险谈了些枯燥的、技术性的东西。然而,我必须承认,有的时候本地循环就是不得不用。
我们在第(一)节说过,.map()不支持print、if、for这些语句,这些限制对于.iteration()也存在。这里再补充两条,它们俩内部同样不支持Export,也不支持Map.addLayer()。前者是将计算结果输出到Google Drive、GEE Assets、以及Google Cloud Storage,后者是在地图面板上添加数据图层。我个人觉得,在循环里用Map.addLayer()以便添加图层,以及用Export以便批量输出,还是比较常见的需求。既然GEE的循环函数不支持,我们就不得不转而寻求本地循环。
在例5中,用一个类似for循环的语句forEach来实现本地循环,使每个循环执行一套独立的计算,将结果表格输出到Google Drive中。
本例来自于GIS Stack Exchange上的问答[12],转载代码请注明原始出处。本文对部分原始代码进行了一点小修改以避免文件名格式报错。
先介绍一下这段代码的大意。有2个空间位置(83.1499°E, 23.14985°N 和 79.477034°E, 11.015846°N),以及2个时段(1980-2006 和 2024-2060)。任务是对每个空间位置、每个时段,从某个气候数据库(NASA NEX-GDDP)中整理出来每日时间序列,各生成1个表格输出。共计2x2=4个表格。
2个空间位置的坐标存放在sites列表中,2个时段的始末年份存放在yearRanges列表中,这些列表都是本地列表(而非ee.List)。
构造了一个自定义函数exportTimeseries来按坐标和时段提取数据记录,函数输入为一组坐标和时段,函数内调用Export.table.toDrive来输出表格。
使用forEach搭配匿名函数,编写了一个二重循环,以便对sites和yearRanges实现循环遍历。在二重循环内部运行自定义的exportTimeseries函数。
var sites = [
[83.1499, 23.14985],
[79.477034, 11.015846],
];
var yearRanges = [
[1980, 2006],
[2040, 2060]
];
sites.forEach(function (site) {
yearRanges.forEach(function (yearRange) {
exportTimeseries(site, yearRange);
});
});
function exportTimeseries(site, yearRange) {
var startDate = ee.Date.fromYMD(yearRange[0], 1, 1);
var endDate = ee.Date.fromYMD(yearRange[1], 1, 1);
// get the dataset between date range and extract band on interest
var dataset = ee.ImageCollection('NASA/NEX-GDDP')
.filter(ee.Filter.date(startDate,endDate));
var maximumAirTemperature = dataset.select('tasmax');
// get projection information
var proj = maximumAirTemperature.first().projection();
var point = ee.Geometry.Point(site);
// calculate number of days to map and extract data for
var n = endDate.difference(startDate,'day').subtract(1);
// map over each date and extract all climate model values
var timeseries = ee.FeatureCollection(
ee.List.sequence(0,n).map(function(i){
var t1 = startDate.advance(i,'day');
var t2 = t1.advance(1,'day');
var feature = ee.Feature(point);
var dailyColl = maximumAirTemperature.filterDate(t1, t2);
var dailyImg = dailyColl.toBands();
// rename bands to handle different names by date
var bands = dailyImg.bandNames();
var renamed = bands.map(function(b){
var split = ee.String(b).split('_');
return ee.String(split.get(0)).cat('_').cat(ee.String(split.get(1)));
});
// extract the data for the day and add time information
var dict = dailyImg.rename(renamed).reduceRegion({
reducer: ee.Reducer.mean(),
geometry: point,
scale: proj.nominalScale()
}).combine(
ee.Dictionary({'system:time_start':t1.millis(),'isodate':t1.format('YYYY-MM-dd')})
);
return ee.Feature(point,dict);
})
);
var name = yearRange.join('-') + '_' + [site[0].toPrecision(2),site[1].toPrecision(2)].join('-');
Map.addLayer(point, null, name);
Map.centerObject(point,6);
// export feature collection to CSV
Export.table.toDrive({
collection: timeseries,
description: 'a_hist_tmax_' + name,
fileFormat: 'CSV',
});
}
我用5个实例展示了一些GEE上常见的循环的用法。.map()2个,.iterate()2个,本地循环1个。它们当然不可能覆盖全部的场景,不过我想也足够提供一定的技术性参考了。写这些主要是为了方便新手查阅,毕竟初学GEE时实在是有着相当陡峭的学习曲线。次要一点的动力就是,希望我的技术分享能给这个逐渐走向内容凋敝的中文互联网环境一点新鲜血液吧。
写循环可能是衡量GEE用户是否是熟练工的标准。祝GEE初学者们尽快走过新手期,掌握这个必要技巧。不过,我有必要在结尾重复一下引言中的那句话,在有内置函数的情况下,我永远推荐内置函数。
欢迎与我交流探讨!
[1] How Earth Engine Works: Deferred Execution | GEE Guides https://developers.google.com/earth-engine/guides/deferred_execution
[2] Functional Programming Concepts - Google Earth Engine https://developers.google.com/earth-engine/tutorials/tutorial_js_03
[3] RTMA: Real-Time Mesoscale Analysis - Earth Engine Data Catalog https://developers.google.com/earth-engine/datasets/catalog/NOAA_NWS_RTMA
[4] Google Earth Engine - ee.FeatureCollection.iterate https://developers.google.com/earth-engine/apidocs/ee-featurecollection-iterate
[5] MERIT Hydro: Global Hydrography Datasets - Earth Engine Data Catalog https://developers.google.com/earth-engine/datasets/catalog/MERIT_Hydro_v1_0_1
[6] 集水区 - 维基百科中文 https://zh.wikipedia.org/zh-hans/集水区
[7] Nezhad, S. G., Mokhtari, A. R., & Rodsari, P. R. (2017). The true sample catchment basin approach in the analysis of stream sediment geochemical data. Ore Geology Reviews, 83, 127–134. https://doi.org/10.1016/j.oregeorev.2016.12.008
[8] 汇流问题示意图 http://spatial-analyst.net/ILWIS/htm/ilwisapp/flow_accumulation_functionality.htm
[9] 使用Google Earth Engine计算汇流 - GIS Stack Exchange https://gis.stackexchange.com/questions/279793/calculating-flow-accumulation-using-google-earth-engine
[10] 汇流算法的GEE分享链接 https://code.earthengine.google.com/ba976e61fe8cc75062494750d99edb10
[11] WWF HydroSHEDS Drainage Direction, 30 Arc-Seconds - Earth Engine Data Catalog https://developers.google.com/earth-engine/datasets/catalog/WWF_HydroSHEDS_30DIR
[12] 批量输出GEE结果的模板 - GIS Stack Exchange https://gis.stackexchange.com/questions/342461/writing-a-loop-in-google-earth-engine-and-save-all-files-as-unique