正文
B+树重要操作
中间节点
- 中间节点的key,与其对应的指针的原则是,小于key的元素在其指针指向的节点中
- 中间节点的key可以看成是右斜着排放的,即小于等于key的节点由key对应的指针指定,最有一个指针指向大于最右侧key的节点
分裂
- 当中间节点数量满了时,进行分裂,新生成一个相邻的中间节点right_internal_node
- 计算原先保留多少元素, 例如保留left_count = K/2
- 将left_count对应的key作为upper_key后续插入到中间节点
- 从left_count + 1下标开始,将key复制到新生成的节点中
- 将left_count下表对应的指针留在左节点
- 将left_count +1 下表对应的指针开始复制到新生成的节点中
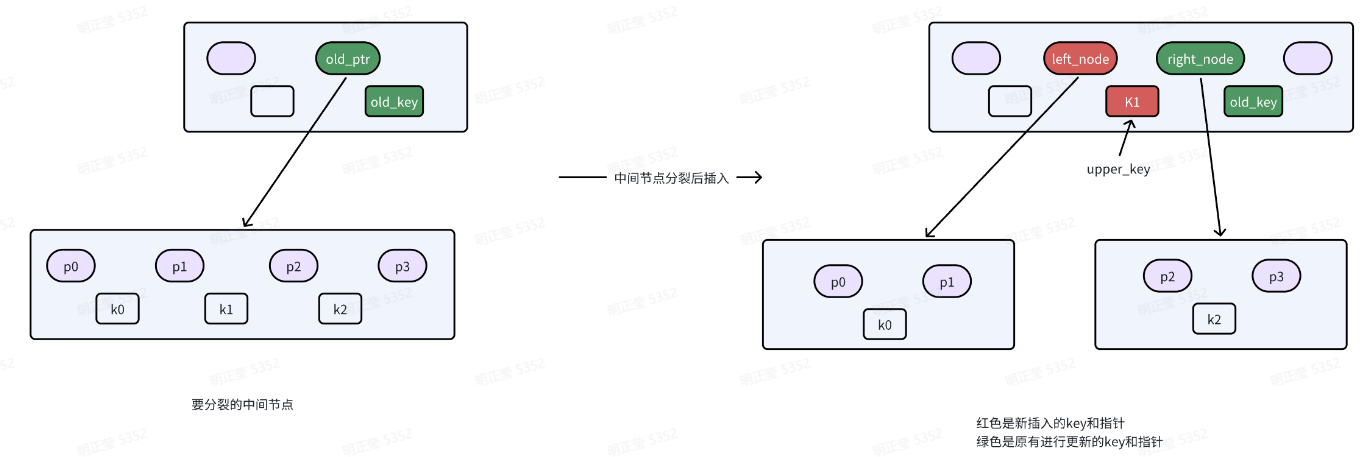
分裂后插入上层中间节点
- 经过分裂有三个重要元素:left_internal_node(也就是原先被分裂节点), right_internal_node(新生成的节点),upper_key
- 上层中间节点为upper_internal_node
- 注意原先upper_internal_node有一个old_key和old_ptr指针指向left_internal_node,这个old_key肯定是比upper_key大的
- 将(upper_key, left_internal_node)作为一对插入到upper_internal_node
- 将old_key对应的old_ptr改成指向right_internal_node
删除
借入数据
中间节点删除数据后,如果数量少于最低值K/2,那么它可以尝试从它的相邻节点借入数据。那么它的相邻节点在哪里呢?第一类相邻节点是与中间节点共享一个父节点的节点,很容易通过其父节点找到。第二类相邻节点,不与其共享一个父节点:想象一下当节点是父节点的最左边节点时,那么在其父节点下,它只有一个右侧相邻节点,这个时候它的左侧相邻节点不在其父节点下;当节点是父节点的最右边节点时,那么在其父节点下,它只有一个左侧相邻节点,这时候它的右侧相邻节点不在其父节点下,而在右侧树分支下。
- 注意第二类的借入在实现的时候也可以不考虑,只不过这样会过早的带来节点合并。
节点合并
当节点确实从左右都没有节点可以借入数据时,那么它就可以与左右节点合并了。正因为其左右节点也没有多的节点可以借,说明其左右节点不大于K/2,那么合并后节点节点数量是会小于K的。
节点合并,我们可以总是选择与其相同父节点下的相邻节点进行合并。节点合并后,需要使父节点删除掉被合并数据的节点(需要注意的是在实际操作中,我们可以选择被删除的节点最终保留下来,也可以选择相邻节点最终保留下来,这只是实现方式)。
降级
父节点删除某个子节点后,需要检查父节点的key数量是否满足K/2要求,如果父节点不满足,那么父节点也需要执行借入动作,如果父节点无法接入,那么就需要执行合并动作。并最终出发祖父节点的删除动作。整个流程会递归上去最终可能会到根节点,若根节点删除了数据,且一个key也没有了。那么就要将其子节点设置成新的root了(奇怪?没有key还有子节点?注意中间节点指针比key多一个,就是说没有key,也至少有一个指针)。
叶子节点
插入
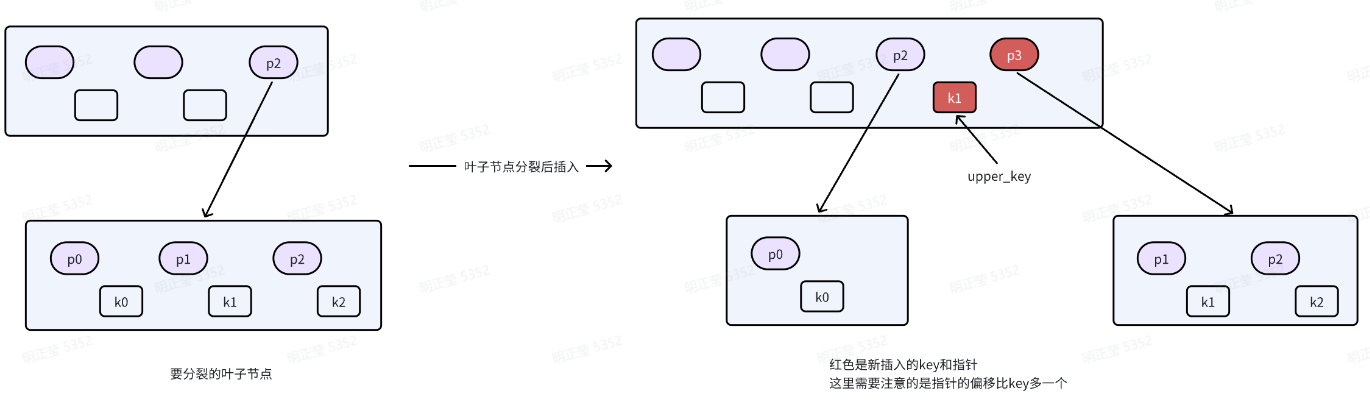
分裂
- 当叶子节点数量满了时,进行分裂,新生成一个相邻sibling节点
- 计算原先保留多少元素, 例如保留left_count = K/2
- 将下标left_count开始的key移动到新生成的节点
- 将left_count对应的key作为upper_key后续插入到中间节点
- 将下标left_count开始的value移动到新生成的节点
分裂后插入上层中间节点
- 新分裂出的节点的第一个key为upper_key
- 如果叶子节点没有上层中间节点,那么就新建一个中间节点作为根节点,把原先叶子节点以及新分裂出的叶子节点直接插入到新的中间节点。同时将upper_key插入到新中间节点中。即它有1个key,两个指针。
- 如果有上层中间节点
- 首先将upper_key插入到中间节点
- 其次将新分裂出的节点指针也插入到中间节点,这里需要注意的是由于中间节点的指针数量比key数量多一个。所以指针插入的index要比upper_key插入的index大1
删除
- 删除后,尝试从其右侧的节点借数据,前提是右侧节点包含m/2 +1个元素
- 若节点(且该节点不是中间节点的最左侧节点)最左边一个元素被删除了,则需要更新中间对应的key
借入数据
借入数据的流程是简单的,与中间节点类似。找到其相邻节点并拿到数据。同样需要注意的是它的相邻节点也可能不在其父节点下。
节点合并
与中间节点的操作类似,找到相邻节点,拷贝数据。通知父节点删除一个节点即可。
要记录哪些指针
- 从B+树的定义上来看,至少每个叶子节点需要记录一个指向右侧相邻节点的指针
其他指针要不要记录呢?
- 节点是否要记录父节点指针?
- 中间节点是否要记录右侧节点的指针?
- 节点是否要记录其左侧节点的指针?
这个因设计实现而异了,记录更多的指针,那么在寻找定位的时候肯定更加容易,但是也带来了很多维护成本,这个在设计的时候做考量。
如何找到相邻的节点
相同父节点下的相邻节点
很容易,很自然,进行遍历就可以或者对key进行find或二分法(注意所有节点里面的key都是有序的)
非相同父节点下的相邻节点
- 最节点的方式是记录节点(包括中间节点)的左侧、右侧指针
另外一种方式,如果不想过多的记录指针,那么可以通过搜索回溯的方式来找目标节点到相邻节点。 某个最左侧中间节点为例:
- 从它开始往上回溯,当回溯到的节点不是其父节点的最左侧节点时,说明我们已经找到了共同祖先
- 然后从共同祖先中的左侧节点(对应下图1的左侧节点3)开始往下找其最右侧的子节点,当往下搜索的层数与向上回溯的层数相同时,我们就找到了目标节点的相邻节点。
- 最右侧中间节点的搜索过程是类似的。
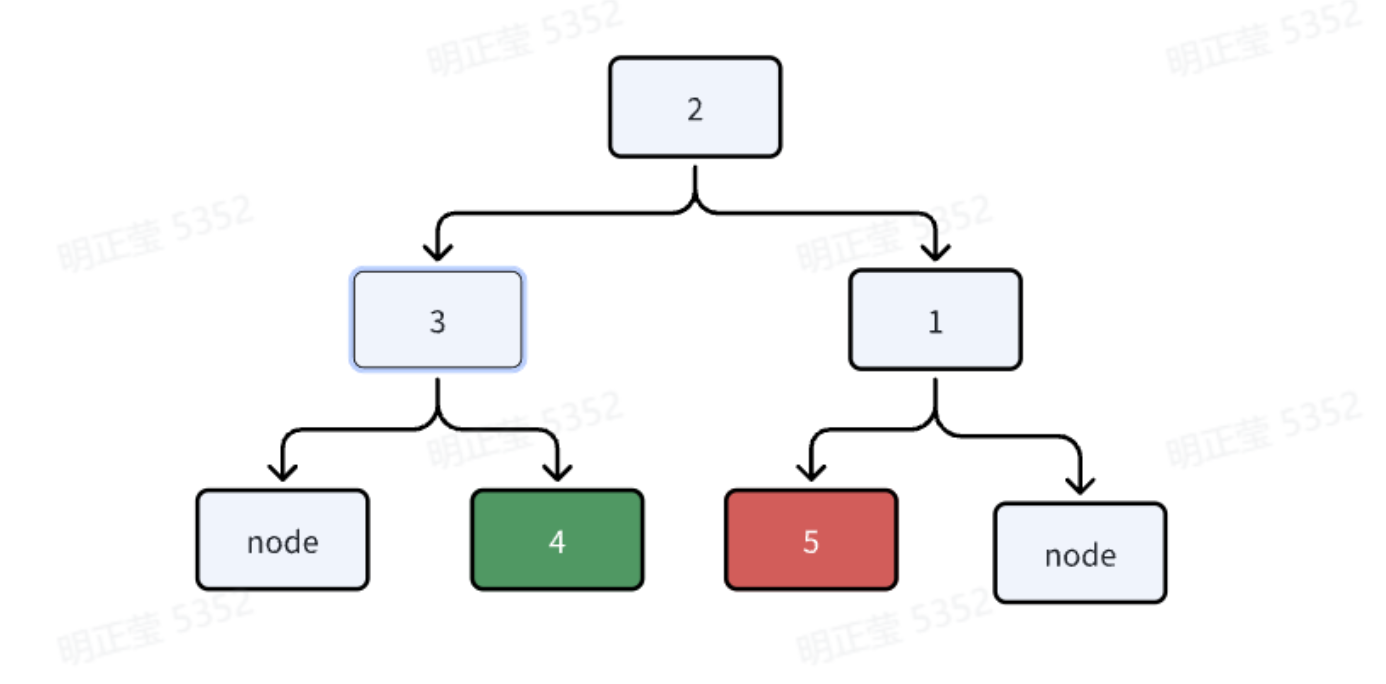
例如想找到节点5的做相邻节点4,就往上回溯首先到1, 5是1的最左侧节点,则继续向上到2,1不是2的最左侧节点,所有2就是共同祖先了。1的左侧节点3往下,找到最右侧节点4, 4与5是相同层级的,那么就是5的相邻左节点了。
另外一个问题是如何进行回溯呢?一种实现方式是子节点记录父节点的指针;另一种实现方式是,记录搜索过程的搜索栈(即从根节点到叶子节点经过了哪些中间节点,记录到一个列表里面)。