在开始前需要先对 kubernetes Operator 有个简单的认识。
以为我们在编写部署一些简单 Deployment 的时候只需要自己编写一个 yaml 文件然后 kubectl apply 即可。
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: k8s-combat
name: k8s-combat
spec:
replicas: 1
selector:
matchLabels:
app: k8s-combat
template:
metadata:
labels:
app: k8s-combat
spec:
containers:
- name: k8s-combat
image: crossoverjie/k8s-combat:v1
imagePullPolicy: Always
resources:
limits:
cpu: "1"
memory: 300Mi
requests:
cpu: "0.1"
memory: 30Mi
复制kubectl apply -f deployment.yaml复制
这对于一些并不复杂的项目来说完全够用了,但组件一多就比较麻烦了。
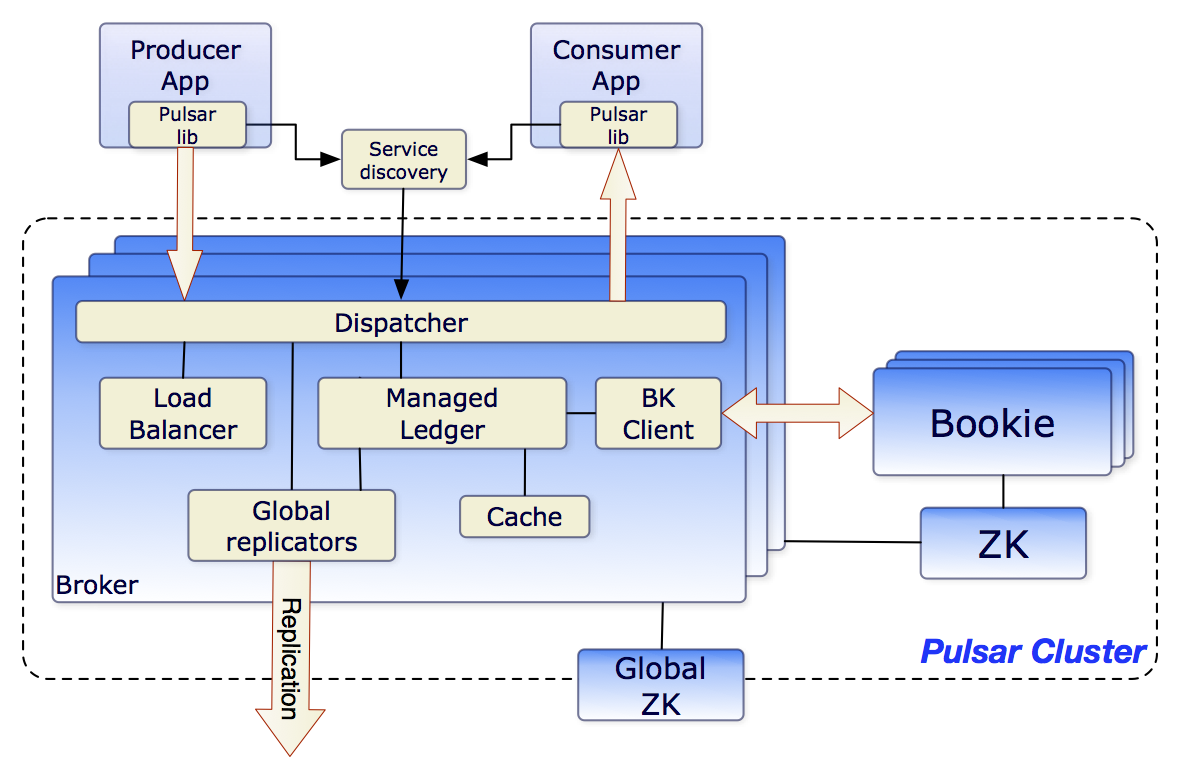
这里以 Apache Pulsar 为例:它的核心组件有:
必须需要等 Zookeeper 和 Bookkeeper 启动之后才能将流量放进来。
此时如何还继续使用 yaml 文件一个个部署就会非常繁琐,好在社区有提供 Helm 一键安装程序,使用它我们只需要在一个同意的 yaml 里简单的配置一些组件,配置就可以由 helm 来部署整个复杂的 Pulsar 系统。
components:
# zookeeper
zookeeper: true
# bookkeeper
bookkeeper: true
# bookkeeper - autorecovery
autorecovery: true
# broker
broker: true
# functions
functions: false
# proxy
proxy: true
# toolset
toolset: true
# pulsar manager
pulsar_manager: false
monitoring:
# monitoring - prometheus
prometheus: true
# monitoring - grafana
grafana: true
# monitoring - node_exporter
node_exporter: true
# alerting - alert-manager
alert_manager: false
复制比如在 helm 的 yaml 中我们可以选择使用哪些 components,以及是否启用监控组件。
最后直接使用这个文件进行安装:
helm install pulsar apache/pulsar \
--values charts/pulsar/values.yaml \
--set namespace=pulsar \
--set initialize=true
复制它就会自动生成各个组件的 yaml 文件,然后统一执行。
所以 helm 的本质上和 kubectl apply yaml 一样的,只是我们在定义 value.yaml 时帮我们处理了许多不需要用户低频修改的参数。
我们可以使用 helm 将要执行的 yaml 输出后人工审核
helm install pulsar apache/pulsar --dry-run --debug > debug.yaml复制
Helm 虽然可以帮我们部署或者升级一个大型应用,但他却没法帮我们运维这个应用。
举个例子:比如我希望当 Pulsar Broker 的流量或者内存达到某个阈值后就指定扩容 Broker,闲时再自动回收。
或者某个 Bookkeeper 的磁盘使用率达到阈值后可以自动扩容磁盘,这些仅仅使用 Helm 时都是无法实现的。
以上这些需求我们目前也是通过监控系统发出报警,然后再由人工处理。
其中最大的痛点就是进行升级:
因为每次升级是有先后顺序的,需要依次观察每个组件运行是否正常才能往后操作。
如果有 Operator 理性情况下下我们只需要更新一下镜像版本,它就可以自动执行以上的所有步骤最后将集群升级完毕。
所以相对于 Helm 来说 Operator 是可以站在一个更高的视角俯视整个应用系统,它能发现系统哪个地方需要它从而直接修复。
而提到 Operator 那就不得不提到 CRD(Custom Resource Definitions)翻译过来就是自定义资源。
这是 kubernetes 提供的一个 API 扩展机制,类似于内置的 Deployment/StatefulSet/Services 资源,CRD 是一种自定义的资源。
这里以我们常用的 prometheus-operator 和 VictoriaMetrics-operator 为例:
Prometheus:
Prometheus:用于定义 Prometheus 的 DeploymentAlertmanager:用于定义 AlertmanagerScrapeConfig:用于定会抓取规则apiVersion: monitoring.coreos.com/v1alpha1
kind: ScrapeConfig
metadata:
name: static-config
namespace: my-namespace
labels:
prometheus: system-monitoring-prometheus
spec:
staticConfigs:
- labels:
job: prometheus
targets:
- prometheus.demo.do.prometheus.io:9090
复制使用时的一个很大区别就是资源的 kind: ScrapeConfig 为自定义的类型。
VictoriaMetrics 的 CRD:
# vmcluster.yaml
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMCluster
metadata:
name: demo
spec:
retentionPeriod: "1"
replicationFactor: 2
vmstorage:
replicaCount: 2
storageDataPath: "/vm-data"
storage:
volumeClaimTemplate:
spec:
resources:
requests:
storage: "10Gi"
resources:
limits:
cpu: "1"
memory: "1Gi"
vmselect:
replicaCount: 2
cacheMountPath: "/select-cache"
storage:
volumeClaimTemplate:
spec:
resources:
requests:
storage: "1Gi"
resources:
limits:
cpu: "1"
memory: "1Gi"
requests:
cpu: "0.5"
memory: "500Mi"
vminsert:
replicaCount: 2
复制以上是用于创建一个 VM 集群的 CRD 资源,应用之后就会自动创建一个集群。
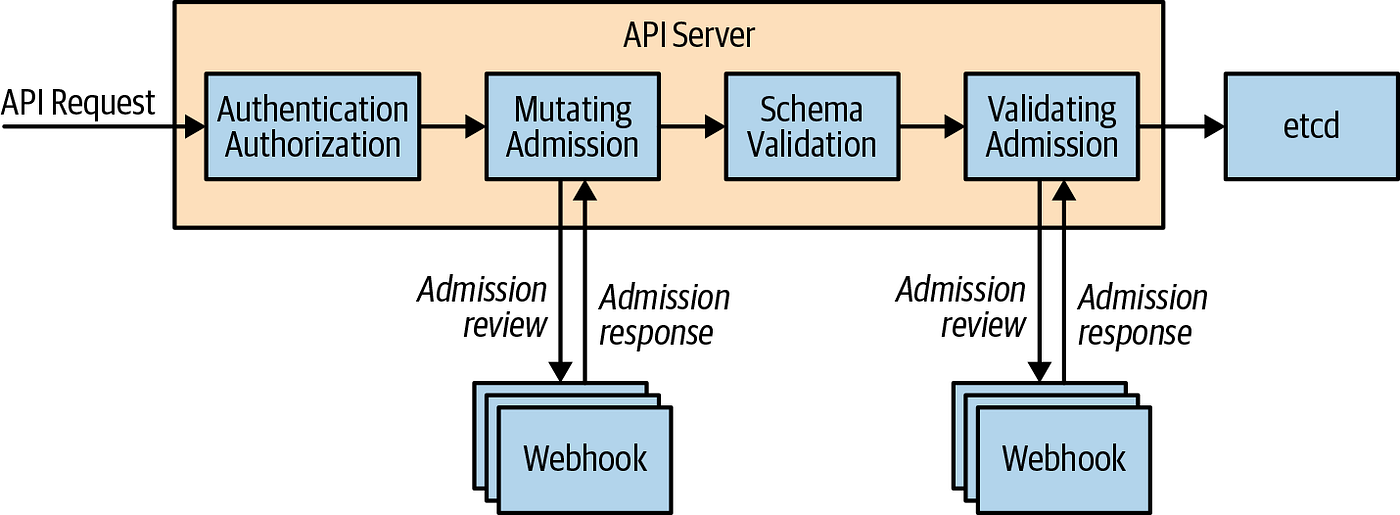
Operator 通常是运行在 kubernetes API server 的 webhook 之上,简单来说就是在一些内置资源的关键节点 API-server 会调用我们注册的一个 webhook,在这个 webhook 中我们根据我们的 CRD 做一些自定义的操作。
理论上我们可以使用任何语言都可以写 Operator,只需要能处理 api-server 的回调即可。
只是 Go 语言有很多成熟的工具,比如常用的 kubebuilder 和 operator-sdk.
他们内置了许多命令行工具,可以帮我们节省需要工作量。
这里以 operator-sdk 为例:
$ operator-sdk create webhook --group cache --version v1alpha1 --kind Memcached --defaulting --programmatic-validation复制
会直接帮我们创建好一个标准的 operator 项目:
├── Dockerfile ├── Makefile ├── PROJECT ├── api │ └── v1alpha1 │ ├── memcached_webhook.go │ ├── webhook_suite_test.go ├── config │ ├── certmanager │ │ ├── certificate.yaml │ │ ├── kustomization.yaml │ │ └── kustomizeconfig.yaml │ ├── default │ │ ├── manager_webhook_patch.yaml │ │ └── webhookcainjection_patch.yaml │ └── webhook │ ├── kustomization.yaml │ ├── kustomizeconfig.yaml │ └── service.yaml ├── go.mod ├── go.sum └── main.go复制
其中 Makefile 中包含了开发过程中常用的工具链(包括根据声明的结构体自动生成 CRD 资源、部署k8s 环境测试等等)、Dockerfile 等等。
这样我们就只需要专注于开发业务逻辑即可。
因为我前段时间给 https://github.com/open-telemetry/opentelemetry-operator 贡献过两个 feature,所以就以这个 Operator 为例:
它有一个 CRD: kind: Instrumentation,在这个 CRD 中可以将 OpenTelemetry 的 agent 注入到应用中。
apiVersion: opentelemetry.io/v1alpha1
kind: Instrumentation
metadata:
name: instrumentation-test-order
namespace: test
spec:
env:
- name: OTEL_SERVICE_NAME
value: order
selector:
matchLabels:
app: order
java:
image: autoinstrumentation-java:2.4.0-release
extensions:
- image: autoinstrumentation-java:2.4.0-release
dir: /extensions
env:
- name: OTEL_RESOURCE_ATTRIBUTES
value: service.name=order
- name: OTEL_INSTRUMENTATION_MESSAGING_EXPERIMENTAL_RECEIVE_TELEMETRY_ENABLED
value: "true"
- name: OTEL_TRACES_EXPORTER
value: otlp
- name: OTEL_METRICS_EXPORTER
value: otlp
- name: OTEL_LOGS_EXPORTER
value: none
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: http://open-telemetry-opentelemetry-collector.otel.svc.cluster.local:4317
- name: OTEL_EXPORTER_OTLP_COMPRESSION
value: gzip
- name: OTEL_EXPERIMENTAL_EXPORTER_OTLP_RETRY_ENABLED
value: "true"
复制它的运行规则是当我们的 Pod 在启动过程中会判断 Pod 的注解中是否开启了注入 OpenTelemetry 的配置。
如果开启则会将我们在 CRD 中自定义的镜像里的 javaagent 复制到业务容器中,同时会将下面的那些环境变量也一起加入的业务容器中。
要达到这样的效果就需要我们注册一个回调 endpoint。
mgr.GetWebhookServer().Register("/mutate-v1-pod", &webhook.Admission{
Handler: podmutation.NewWebhookHandler(cfg, ctrl.Log.WithName("pod-webhook"), decoder, mgr.GetClient(),
[]podmutation.PodMutator{
sidecar.NewMutator(logger, cfg, mgr.GetClient()),
instrumentation.NewMutator(logger, mgr.GetClient(), mgr.GetEventRecorderFor("opentelemetry-operator"), cfg),
}),})
复制当 Pod 创建或有新的变更请求时就会回调我们的接口。
func (pm *instPodMutator) Mutate(ctx context.Context, ns corev1.Namespace, pod corev1.Pod) (corev1.Pod, error) {
logger := pm.Logger.WithValues("namespace", pod.Namespace, "name", pod.Name)
}
复制在这个接口中我们就可以拿到 Pod 的信息,然后再获取 CRD Instrumentation 做我们的业务逻辑。
var otelInsts v1alpha1.InstrumentationList
if err := pm.Client.List(ctx, &otelInsts, client.InNamespace(ns.Name)); err != nil {
return nil, err
}
// 从 CRD 中将数据复制到业务容器中。
pod.Spec.InitContainers = append(pod.Spec.InitContainers, corev1.Container{
Name: javaInitContainerName,
Image: javaSpec.Image,
Command: []string{"cp", "/javaagent.jar", javaInstrMountPath + "/javaagent.jar"},
Resources: javaSpec.Resources,
VolumeMounts: []corev1.VolumeMount{{
Name: javaVolumeName,
MountPath: javaInstrMountPath,
}},
})
for i, extension := range javaSpec.Extensions {
pod.Spec.InitContainers = append(pod.Spec.InitContainers, corev1.Container{
Name: initContainerName + fmt.Sprintf("-extension-%d", i),
Image: extension.Image,
Command: []string{"cp", "-r", extension.Dir + "/.", javaInstrMountPath + "/extensions"},
Resources: javaSpec.Resources,
VolumeMounts: []corev1.VolumeMount{{
Name: javaVolumeName,
MountPath: javaInstrMountPath,
}},
})
}
复制不过需要注意的是想要在测试环境中测试 operator 是需要安装一个 cert-manage,这样
webhook才能正常的回调。
要使得 CRD 生效,我们还得先将 CRD 安装进 kubernetes 集群中,不过这些 operator-sdk 这类根据已经考虑周到了。
我们只需要定义好 CRD 的结构体:

然后使用 Makefile 中的工具 make bundle 就会自动将结构体转换为 CRD。
参考链接: