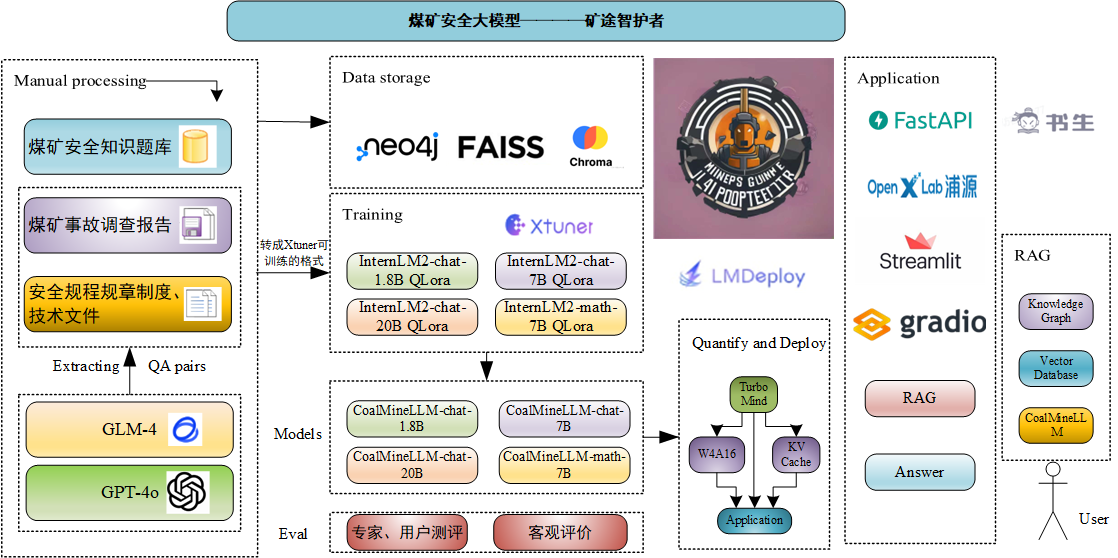
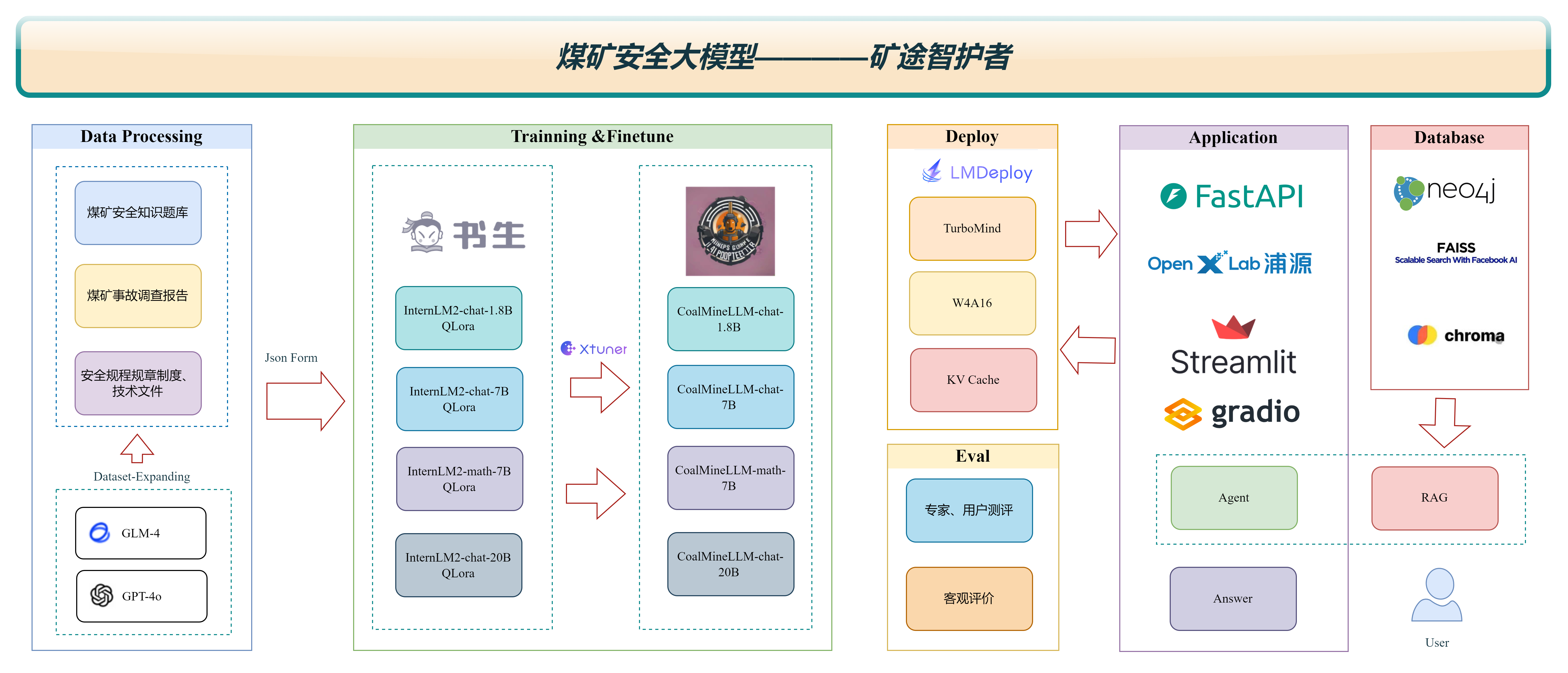
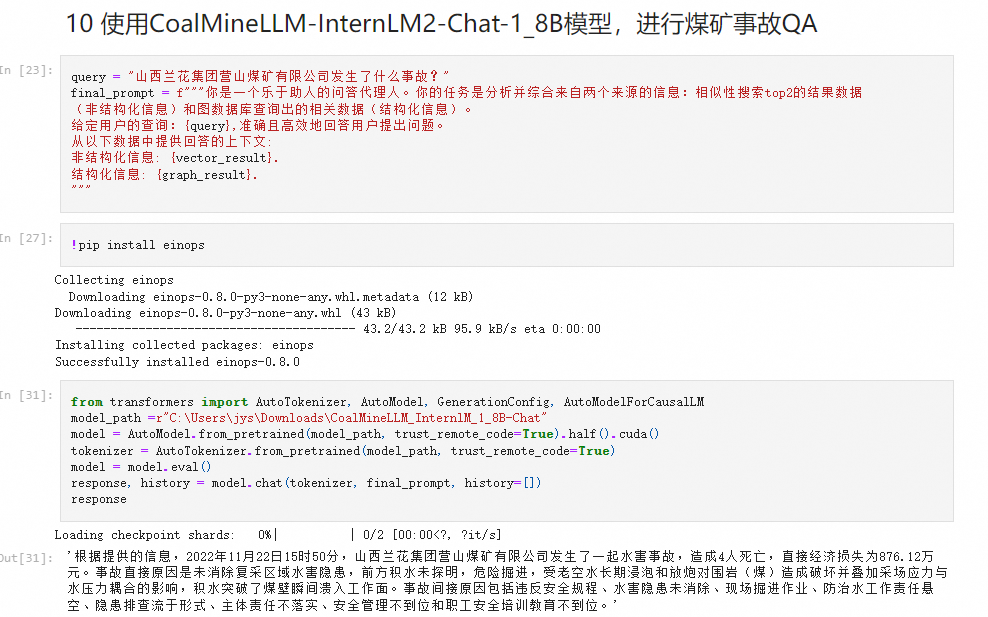
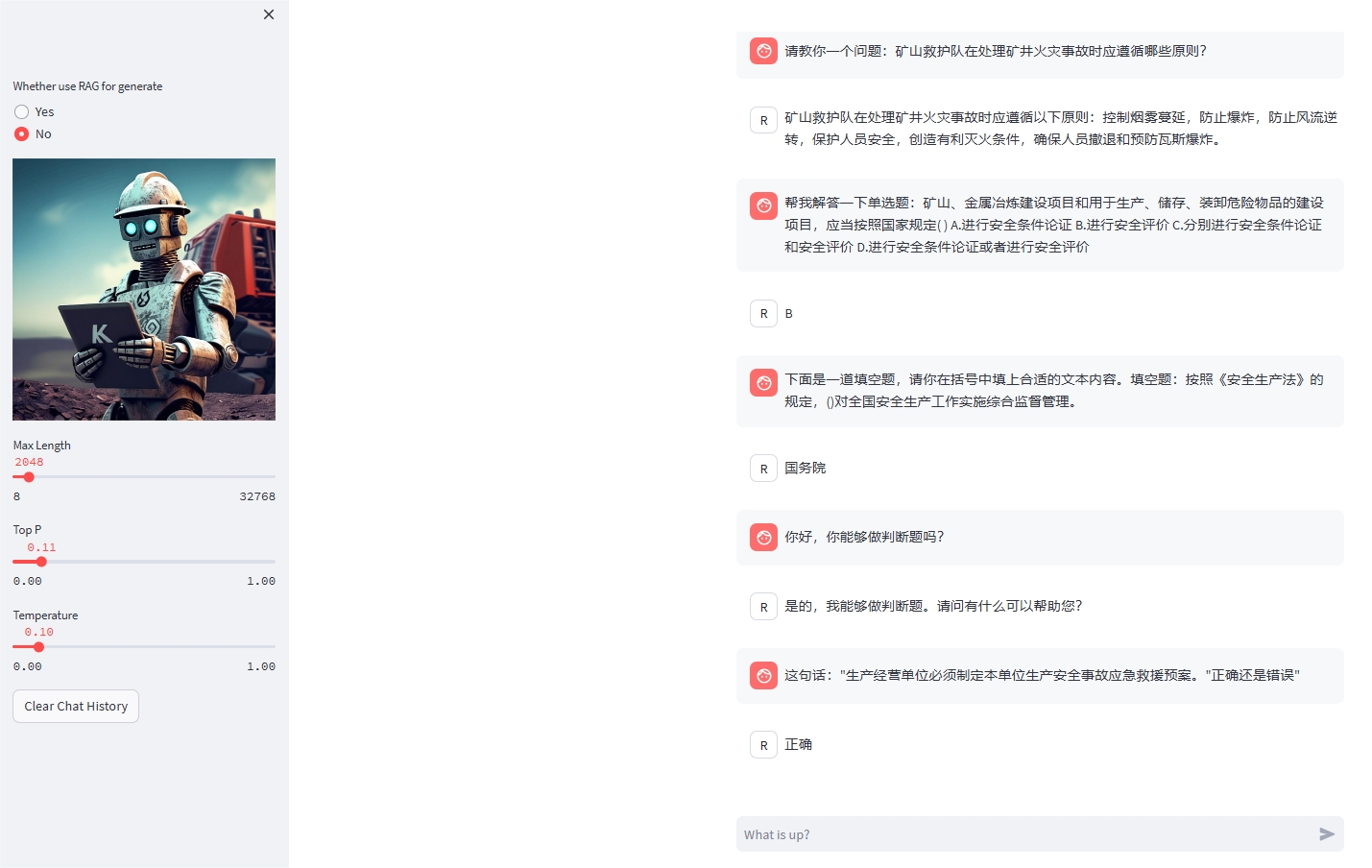
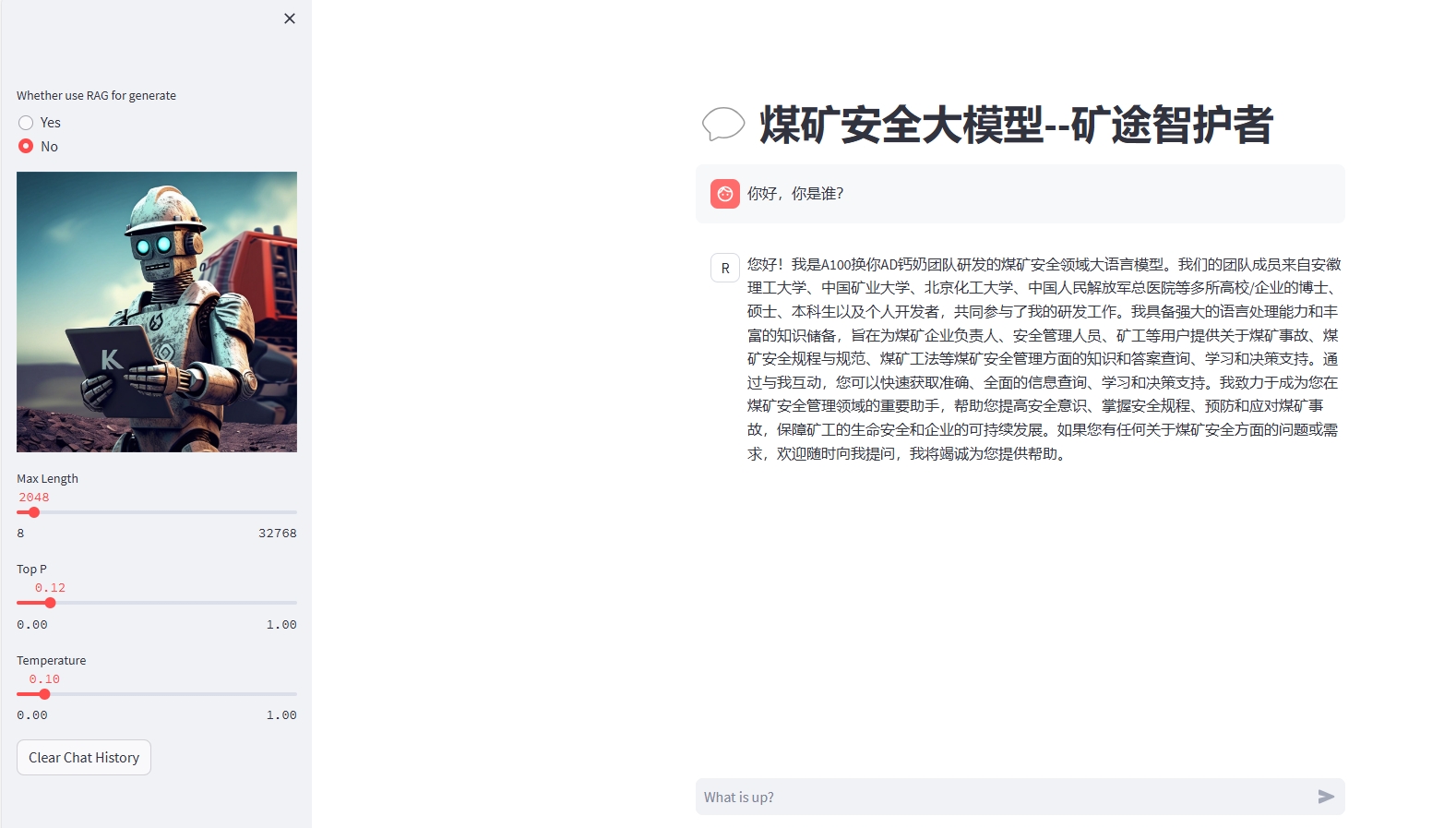
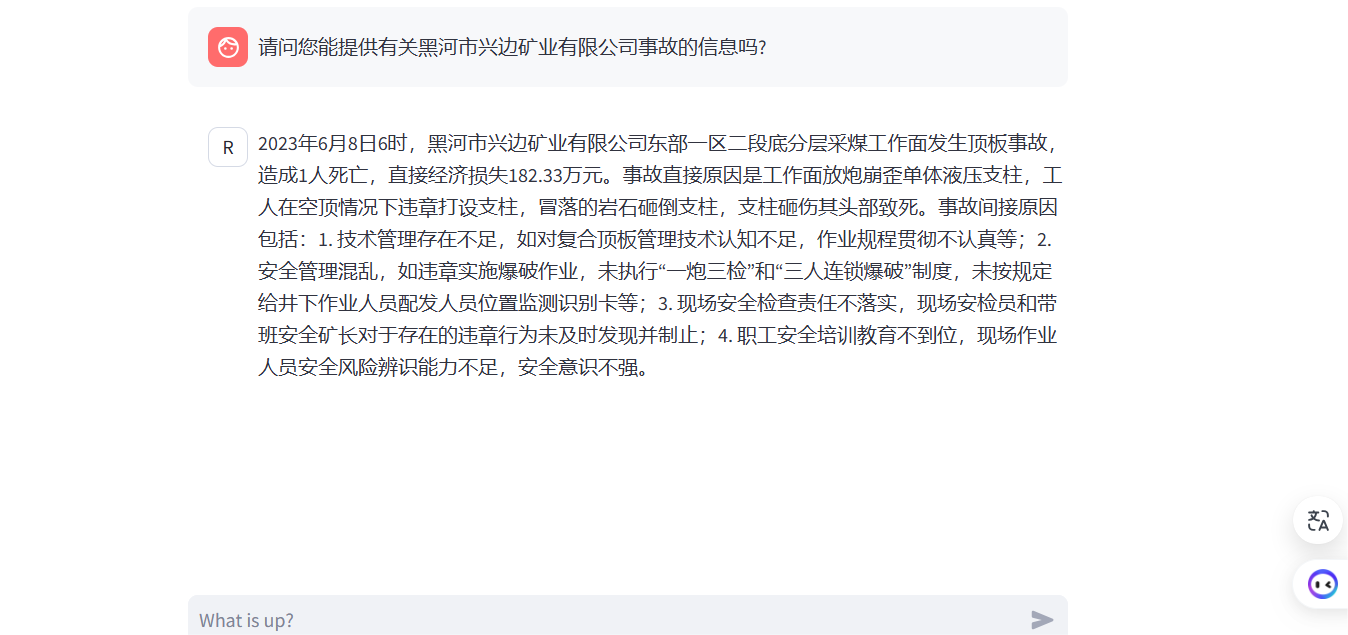
使用煤矿历史事故案例,事故处理报告、安全规程规章制度、技术文档、煤矿从业人员入职考试题库等数据,微调internlm2模型实现针对煤矿事故和煤矿安全知识的智能问答。
本项目简介:
近年来,国家对煤矿安全生产的重视程度不断提升。为了确保煤矿作业的安全,提高从业人员的安全知识水平显得尤为重要。鉴于此,目前迫切需要一个高效、集成化的解决方案,该方案能够整合煤矿安全相关的各类知识,为煤矿企业负责人、安全管理人员、矿工提供一个精确、迅速的信息查询、学习与决策支持平台。
为实现这一目标,我们利用包括煤矿历史事故案例、事故处理报告、安全操作规程、规章制度、技术文档以及煤矿从业人员入职考试题库等在内的丰富数据资源,通过微调InternLM2模型,构建出一个专门针对煤矿事故和煤矿安全知识智能问答的煤矿安全大模型。
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
本项目的特点如下:
| 类别 | 底座 | 名称 | 版本 | 下载链接 | 微调方法 |
|---|---|---|---|---|---|
| 对话模型 | InternLM2-Chat-1_8B | CoalMineLLM_InternLM2-Chat-1_8B | V1.0 | OpenXLab | QLora |
| 对话模型 | InternLM2-Chat-7B | CoalMineLLM_InternLM2-Chat-7B | V1.0 | OpenXLab | QLora |
| 对话模型 | InternLM2-Math-7B | CoalMineLLM_InternLM2-Math-7B | V1.0 | OpenXLab | QLora |
| 对话模型 | InternLM2-Chat-20B | CoalMineLLM_InternLM2-Chat-20B | V1.0 | OpenXLab | QLora |
| 对话模型 | InternLM2-Chat-1_8B | CoalMineLLM_InternLM2-Chat-1_8B-full | V1.0 | OpenXLab | 全参微调 |
| 对话模型 | CoalMineLLM_InternLM2-Chat-7B | CoalMineLLM_InternLM2-Chat-7B-4bit | V1.0 | OpenXLab | W4A16量化 |
git clone https://github.com/yaosenJ/CoalQA.git cd CoalQA conda create -n CoalQA python=3.10.0 -y conda activate CoalQA conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia pip install -r requirements.txt cd web_app streamlit run streamlit_app.py --server.address=127.0.0.1 --server.port 6006复制
CoalMineLLM_InternLM2-Chat-1_8版体验地址:https://openxlab.org.cn/apps/detail/milowang/CoalQAv1
git clone https://github.com/yaosenJ/CoalQA.git cd CoalQA conda create -n CoalQA python=3.10.0 -y conda activate CoalQA conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia pip install -r requirements.txt复制
1.1 输入如下命令,会在data目录下生成CoalQA_data.json
python Generate_QAdata.py ../data/CoalQA_data.json复制
CoalQA_data.json内容结构形如:
[ { "input": "请提供新建矿井立井井筒冻结法施工的具体要求。", "output": "新建矿井立井井筒冻结法施工需要遵守以下要求:冻结深度必须穿过风化带延深至稳定的基岩10m以上,第一个冻结孔必须全孔取芯,钻孔时必须测定钻孔的方向和偏斜度,偏斜度超过规定时必须及时纠正,冻结管必须采用无缝钢管并焊接或螺纹连接,开始冻结后必须经常观察水文观测孔的水位变化,并在确定冻结壁已交圈后才能进行试挖。" }, ... ]复制
1.2 接上面生成json,处理成Xtuner可训练数据格式,运行下面命令即可
python format_internlm2.py复制
[ { "conversation": [ { "system": "你是一个煤矿安全领域的知识达人,你对相关煤矿安全规章规程制度、技术等文档非常熟悉。请你专业正确地解答用户想问的煤矿安全相关问题。", "input": "请提供新建矿井立井井筒冻结法施工的具体要求。", "output": "新建矿井立井井筒冻结法施工需要遵守以下要求:冻结深度必须穿过风化带延深至稳定的基岩10m以上,第一个冻结孔必须全孔取芯,钻孔时必须测定钻孔的方向和偏斜度,偏斜度超过规定时必须及时纠正,冻结管必须采用无缝钢管并焊接或螺纹连接,开始冻结后必须经常观察水文观测孔的水位变化,并在确定冻结壁已交圈后才能进行试挖。" } ] }, { "conversation": [ { "system": "你是一个煤矿安全领域的知识达人,你对相关煤矿安全规章规程制度、技术等文档非常熟悉。请你专业正确地解答用户想问的煤矿安全相关问题。", "input": "煤矿安全规程中,对于新建矿井的立井井筒冻结法施工有哪些具体要求?", "output": "新建矿井立井井筒冻结法施工需要遵守以下要求:冻结深度必须穿过风化带延深至稳定的基岩10m以上,第一个冻结孔必须全孔取芯,钻孔时必须测定钻孔的方向和偏斜度,偏斜度超过规定时必须及时纠正,冻结管必须采用无缝钢管并焊接或螺纹连接,开始冻结后必须经常观察水文观测孔的水位变化,并在确定冻结壁已交圈后才能进行试挖。" } ] }, ... ]复制
输入如下命令即可
python Generate_Question_bank.py复制
这里展示多选题生成
[ { "conversation": [ { "system": "你是一个煤矿安全领域的知识达人,你会解答很多题。用户给出一个多选题,你能从几个选项中,选择出多个正确选项。", "input": "掘进巷道在下列哪些情况下不能爆破()。\nA、掘进工作面或炮眼有突水预兆时\nB、探水孔超前距不够时\nC、空顶距超过规定时\nD、掘进工作面支架不牢固时", "output": "ABCD" } ] }, ... ]复制
若想生成其他题目类型训练数据,请在相应位置替换成需要的内容
csv_filename = '../data/多选题.csv'
#csv_filename = '../data/单选题.csv'
#csv_filename = '../data/判断题.csv'
#csv_filename = '../data/填空题.csv'
#csv_filename = '../data/简答题.csv'
json_filename = '../data/multiple_choice.json'
#son_filename = '../data/single_choice.json'
#json_filename = '../data/true_or_false.json'
#json_filename = '../data/fill_in.json'
#json_filename = '../data/shot_answer.json'
"system": "你是一个煤矿安全领域的知识达人,你会解答很多题。用户给出一个多选题,你能从几个选项中,选择出多个正确选项。"
#"system": "你是一个煤矿安全领域的知识达人,你会解答很多题。用户给出一个单选题,你能从几个选项中,选择出一个正确选项。"
#"system": "你是一个煤矿安全领域的知识达人,你会解答很多题。用户给出一个判断题,然后你作出判断,是正确还是错误。"
#"system": "你是一个煤矿安全领域的知识达人,你会解答很多题。用户给出一个填空题,然后你在题目中括号中,填写合适的答案"
#"system": "你是一个煤矿安全领域的知识达人,你对相关煤矿安全规章规程制度、技术等文档非常熟悉。请你专业正确地解答用户想问的煤矿安全相关问题。"
复制""" ""{accident}"" 通过上面提供的事故调查事故报告,请你帮我生成多轮对话文本,格式为[ { "conversation": [ { "system": "你是一名煤矿安全领域的知识达人,提供有关煤矿安全规程、事故预防措施和应急响应的知识。", "input": "你好!", "output": "您好,我是一名煤矿安全领域的知识达人,请问有什么可以帮助您?" }, { "input": " ", "output": " " },... ] } ] """复制
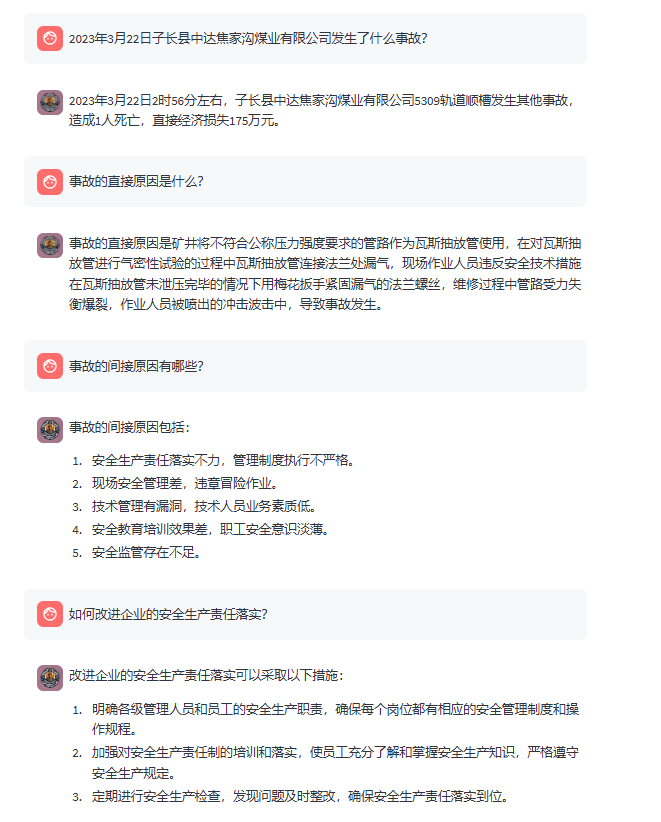
{ "conversation": [ { "system": "你是一名煤矿安全领域的知识达人,提供有关煤矿安全规程、事故预防措施和应急响应的知识。", "input": "你好!", "output": "您好,我是一名煤矿安全领域的知识达人,请问有什么可以帮助您?" }, { "input": "2023年3月22日子长县中达焦家沟煤业有限公司发生了什么事故?", "output": "2023年3月22日2时56分左右,子长县中达焦家沟煤业有限公司5309轨道顺槽发生其他事故,造成1人死亡,直接经济损失175万元。" }, { "input": "事故的直接原因是什么?", "output": "事故的直接原因是矿井将不符合公称压力强度要求的管路作为瓦斯抽放管使用,在对瓦斯抽放管进行气密性试验的过程中瓦斯抽放管连接法兰处漏气,现场作业人员违反安全技术措施在瓦斯抽放管未泄压完毕的情况下用梅花扳手紧固漏气的法兰螺丝,维修过程中管路受力失衡爆裂,作业人员被喷出的冲击波击中,导致事故发生。" }, { "input": "事故的间接原因有哪些?", "output": "事故的间接原因包括:\n1. 安全生产责任落实不力,管理制度执行不严格。\n2. 现场安全管理差,违章冒险作业。\n3. 技术管理有漏洞,技术人员业务素质低。\n4. 安全教育培训效果差,职工安全意识淡薄。\n5. 安全监管存在不足。" }, { "input": "如何改进企业的安全生产责任落实?", "output": "改进企业的安全生产责任落实的方法包括:\n1. 明确设备材料管理制度,确保采购把关严格,合同明确产品具体型号和使用范围。\n2. 制定并落实管路使用和回收的管理制度,明确责任主体。\n3. 加强日常维护保养,确保设备材料的安全使用。\n4. 严格执行《安全技术措施审批制度》等安全管理制度,确保安全生产责任落实到位。" }, { "input": "如何加强现场安全管理,避免违章冒险作业?", "output": "加强现场安全管理的方法包括:\n1. 全面分析和辨识作业风险,制定详细的安全技术措施。\n2. 确保现场作业人员严格遵守安全操作规程,禁止违章冒险作业。\n3. 增强现场监督管理,确保有安全员和负责人进行现场安全监督。\n4. 实现专业队伍化,确保瓦斯抽放管路敷设和测试等工作由专业队伍执行。" }, { "input": "如何提高技术管理水平?", "output": "提高技术管理水平的方法包括:\n1. 加强安全技术规范的学习和掌握,确保技术人员了解相关标准和要求。\n2. 科学编制安全技术措施,选择更安全的工艺和方法。\n3. 严格执行安全技术措施会审制度,确保措施科学合理。\n4. 确保作业人员严格执行安全技术措施,避免违章操作。\n5. 进行全面的风险分析和研判,辨识并防范可能的安全风险。" }, { "input": "如何改进安全教育培训效果?", "output": "改进安全教育培训效果的方法包括:\n1. 制定详细的培训计划,确保职工全面掌握安全技术措施。\n2. 提高培训的实际操作性,通过实操训练提高职工的安全意识和技能。\n3. 加强对作业环境的安全风险辨识培训,提升职工的自保互保意识。\n4. 定期进行培训考核,检验培训效果,确保培训内容深入人心。" }, { "input": "如何增强安全监管力度?", "output": "增强安全监管力度的方法包括:\n1. 明确驻矿安检员的职责,确保其全面掌握煤矿安全生产状况。\n2. 加强安全监管分工,确保各项监管工作责任到人。\n3. 进行定期和不定期的安全检查,发现并整改安全隐患。\n4. 建立健全安全监管考核制度,确保安全监管工作落实到位。" } ] }复制
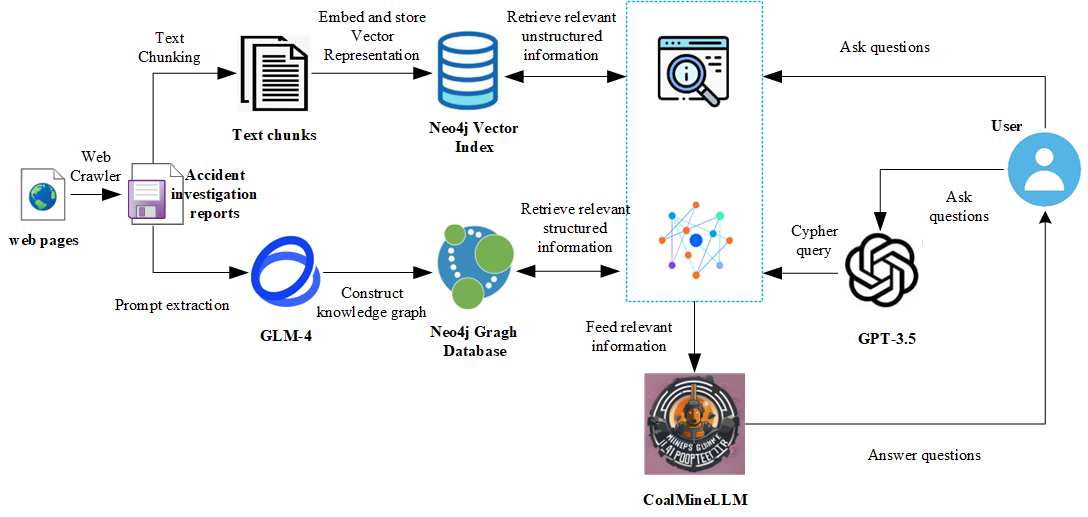
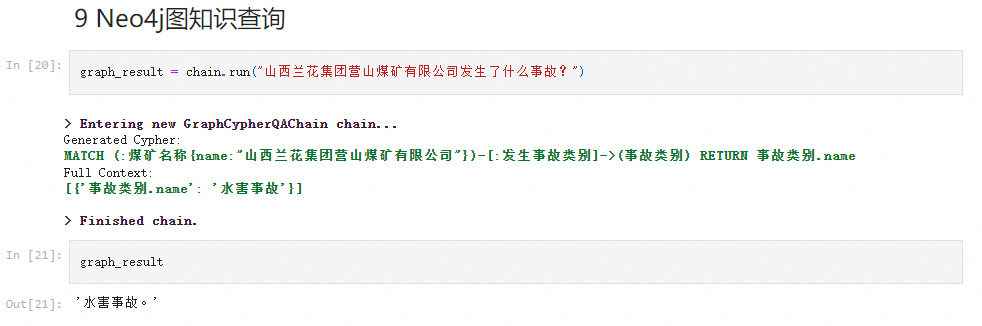
使用GLM-4模型,构建煤矿事故知识图谱。暂时不开源
1.合并两个json文件的脚本:merge_json.py
2.格式化json文本的脚本:format_json.py
3.打乱json中数据顺序的脚本:shuffle.py
相关数据请见data目录:安全知识的智能问答
创建环境
conda create -n internlm2 python=3.10 conda activate internlm2 conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia复制
环境包的安装
cd ~ git clone -b v0.1.18 https://github.com/InternLM/XTuner cd XTuner pip install [-e .]复制
git clone https://github.com/yaosenJ/CoalQA.git复制
进入finetune目录
cd CoalQA/finetune复制
执行如下命令,下载internlm2-chat-7b模型参数文件:
python download_model.py复制
本文档提供了使用 XTuner 工具进行模型微调过程的详细指南。该过程包括转换、合并、训练以及为不同规模的模型(1.8B 和 20B)设置网络演示。
#如果你是在 InternStudio 平台,则从本地 clone 一个已有 pytorch 的环境:
#pytorch 2.0.1 py3.10_cuda11.7_cudnn8.5.0_0
studio-conda xtuner0.1.17
#如果你是在其他平台:
#conda create --name xtuner0.1.17 python=3.10 -y
#激活环境
conda activate xtuner0.1.17
#进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
#创建版本文件夹并进入,以跟随本教程
mkdir -p /root/xtuner0117 && cd /root/xtuner0117
#拉取 0.1.17 的版本源码
git clone -b v0.1.17 https://github.com/InternLM/xtuner
#无法访问github的用户请从 gitee 拉取:
#git clone -b v0.1.15 https://gitee.com/Internlm/xtuner
#进入源码目录
cd /root/xtuner0117/xtuner
#从源码安装 XTuner
pip install -e '.[all]'
复制#在ft这个文件夹里再创建一个存放数据的data文件夹,存储数据
mkdir -p /root/ft/data && cd /root/ft/data
复制#创建目标文件夹,确保它存在。
#-p选项意味着如果上级目录不存在也会一并创建,且如果目标文件夹已存在则不会报错。
mkdir -p /root/ft/model
#复制内容到目标文件夹。-r选项表示递归复制整个文件夹。
cp -r /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b/* /root/ft/model/
复制如果是需要自己下载,可以使用transformers库
from transformers import AutoModel
#指定模型名称
model_name = 'internlm/internlm2-chat-1_8b'
#加载模型
model = AutoModel.from_pretrained(model_name)
#指定保存模型的目录
model_save_path = '/root/ft/model'
#保存模型
model.save_pretrained(model_save_path)
复制将这段代码保存为 download_model.py,然后在命令行中运行这个脚本:
python download_model.py复制
这个脚本会自动下载模型并将其保存到指定的 /root/ft/model 目录中。
#XTuner 提供多个开箱即用的配置文件,用户可以通过下列命令查看:
#列出所有内置配置文件
#xtuner list-cfg
#假如我们想找到 internlm2-1.8b 模型里支持的配置文件
xtuner list-cfg -p internlm2_1_8b
#创建一个存放 config 文件的文件夹
mkdir -p /root/ft/config
#使用 XTuner 中的 copy-cfg 功能将 config 文件复制到指定的位置
xtuner copy-cfg internlm2_1_8b_qlora_alpaca_e3 /root/ft/config
复制#修改模型地址(在第27行的位置)
- pretrained_model_name_or_path = 'internlm/internlm2-1_8b'
+ pretrained_model_name_or_path = '/root/ft/model'
#修改数据集地址为本地的json文件地址(在第31行的位置)
- alpaca_en_path = 'tatsu-lab/alpaca'
+ alpaca_en_path = '/root/ft/data/personal_assistant.json'
#修改max_length来降低显存的消耗(在第33行的位置)
- max_length = 2048
+ max_length = 1024
#减少训练的轮数(在第44行的位置)
- max_epochs = 3
+ max_epochs = 2
#增加保存权重文件的总数(在第54行的位置)
- save_total_limit = 2
+ save_total_limit = 3
#修改每多少轮进行一次评估(在第57行的位置)
- evaluation_freq = 500
+ evaluation_freq = 300
#修改具体评估的问题(在第59到61行的位置)
#把 OpenAI 格式的 map_fn 载入进来(在第15行的位置)
- from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory
+ from xtuner.dataset.map_fns import openai_map_fn, template_map_fn_factory
#将原本是 alpaca 的地址改为是 json 文件的地址(在第102行的位置)
- dataset=dict(type=load_dataset, path=alpaca_en_path),
+ dataset=dict(type=load_dataset, path='json', data_files=dict(train=alpaca_en_path)),
#将 dataset_map_fn 改为通用的 OpenAI 数据集格式(在第105行的位置)
- dataset_map_fn=alpaca_map_fn,
+ dataset_map_fn=None,
复制#指定保存路径
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train
#使用 deepspeed 来加速训练
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train_deepspeed --deepspeed deepspeed_zero2
复制创建目录:为转换后的 Huggingface 模型创建一个存储目录:
mkdir -p /root/ft/huggingface/i8000
复制模型转换:使用提供的配置和权重文件进行模型转换:
xtuner convert pth_to_hf /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py /root/ft/train_deepspeed/iter_18000.pth /root/ft/huggingface/i8000 --fp32复制
合并模型:合并模型并解决依赖关系:
mkdir -p /root/ft/final_model_8000
export MKL_SERVICE_FORCE_INTEL=1
xtuner convert merge /root/ft/model /root/ft/huggingface/1i8000 /root/ft/final_model_18000
复制测试模型:通过启动对话来测试模型:
xtuner chat /root/ft/final_model_18000 --prompt-template internlm2_chat复制
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train_deepspeed --resume /root/ft/train_deepspeed/iter_8500.pth --deepspeed deepspeed_zero1复制
准备环境:
mkdir -p /root/ft/web_demo && cd /root/ft/web_demo
git clone https://github.com/InternLM/InternLM.git
cd /root/ft/web_demo/InternLM
复制运行演示 使用 Streamlit:
streamlit run /root/ft/web_demo/InternLM/chat/web_demo.py --server.address 127.0.0.1 --server.port 6006复制
通过 SSH 隧道访问演示:
ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p 开发机端口号复制
与1.8B模型训练过程类似,20B模型训练涉及到为配置、数据和最终模型创建相应的目录。此外,这一过程还包括使用多个GPU进行模型训练,并将模型转换为Huggingface格式。
为大规模的20B模型训练准备数据。
#创建一个专用于存放20B模型数据的目录
mkdir -p /root/ft20b/data && cd /root/ft20b/data
复制准备模型包括创建目标文件夹并将预训练的20B模型复制到指定位置。
#创建一个目录用来存放20B模型文件
mkdir -p /root/ft20b/model
#将预训练的模型复制到新创建的目录中
cp -r /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-20b/* /root/ft20b/model/
复制下载并准备20B模型的配置文件,以便进行训练。
#列出所有支持20B模型的配置文件
xtuner list-cfg -p internlm2_20b
#创建一个目录用于存放20B模型的配置文件
mkdir -p /root/ft20b/config
#复制所需的配置文件到新创建的目录中
xtuner copy-cfg internlm2_20b_qlora_alpaca_e3 /root/ft20b/config
复制根据训练需求调整配置文件,以优化20B模型的训练。
#修改模型路径和数据集路径等关键参数以适配20B模型
- pretrained_model_name_or_path = 'internlm/internlm2-20b'
+ pretrained_model_name_or_path = '/root/ft20b/model'
- alpaca_en_path = 'tatsu-lab/alpaca'
+ alpaca_en_path = '/root/ft20b/data/specific_dataset.json'
- max_length = 2048
+ max_length = 1024
- max_epochs = 3
+ max_epochs = 2
- save_total_limit = 2
+ save_total_limit = 3
- evaluation_freq = 500
+ evaluation_freq = 300
复制使用DeepSpeed和多GPU配置来加速20B模型的训练过程。
#指定保存路径并开始训练
xtuner train /root/ft20b/config/internlm2_20b_qlora_alpaca_e3_copy.py --work-dir /root/ft20b/train_deepspeed --deepspeed deepspeed_zero2
复制为转换后的Huggingface模型创建目录并执行转换。
#创建一个目录用于存放转换后的Huggingface模型
mkdir -p /root/ft20b/huggingface
#执行模型转换
xtuner convert pth_to_hf /root/ft20b/config/internlm2_20b_qlora_alpaca_e3_copy.py /root/ft20b/train_deepspeed/iter_2600.pth /root/ft20b/huggingface
复制合并转换后的模型并解决依赖关系。
#创建一个名为final_model的目录以存储合并后的模型文件
mkdir -p /root/ft20b/final_model
#合并模型
xtuner convert merge /root/ft20b/model /root/ft20b/huggingface /root/ft20b/final_model
复制通过启动对话来测试合并后的模型。
#启动与模型的对话测试
xtuner chat /root/ft20b/final_model --prompt-template
internlm2_chat
复制这一部分提供了详细的指导,确保20B模型的训练过程得到妥善管理和执行。
max_length = 4096
pack_to_max_length = True
#parallel
sequence_parallel_size = 1
#Scheduler & Optimizer
batch_size = 4 # per_device
accumulative_counts = 16
accumulative_counts *= sequence_parallel_size
dataloader_num_workers = 0
max_epochs = 50
=》
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.54.03 Driver Version: 535.54.03 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA A100-SXM4-80GB On | 00000000:89:00.0 Off | 0 |
| N/A 65C P0 334W / 400W | 59119MiB / 81920MiB | 100% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 1 NVIDIA A100-SXM4-80GB On | 00000000:B3:00.0 Off | 0 |
| N/A 66C P0 358W / 400W | 59119MiB / 81920MiB | 100% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
复制原因是:
问题的根源:尝试加载的模型检查点是在数据并行(DP)世界大小为1(即单个GPU或单个训练进程)的环境中保存的。但当前尝试恢复训练的环境具有数据并行世界大小为2(即两个GPU或两个训练进程)。
ZeRO的限制:DeepSpeed的ZeRO优化器分区(ZeRO-Optimizer State Partitioning)依赖于特定的世界大小配置,并且目前不支持自动调整新的世界大小。换句话说,如果你在一个GPU上训练并保存了检查点,那么在加载这个检查点进行恢复训练时,你必须在相同数量的GPU上进行。
模块目的:根据用户的问题,检索对应信息以增强回答的专业性, 使CoalQA的回答更加专业可靠。检索内容包括但不限于以下几点:
煤矿安全相关的问答对
煤矿安全相关的案例
这个RAG系统各部分的技术路线分别是:
Embedding 模型:BAAI/bge-small-en-v1.5
LLM基座:InternLM2-Chat-1.8B InternLM2-Chat-7B InternLM2-Chat-20B InternLM2-Math-7B
使用BAAI/bge-reranker-large做检索后精排
向量数据库:
git clone https://github.com/yaosenJ/CoalQA.git cd rag pip install -r requirements.txt复制
PDF 数据
将需要向量化的pdf数据放到对应的目录下
JSON 数据
构建 QA 对并生成 JSON 文件(单轮/多轮对话),放入到对应目录下
数据格式如下
#单轮对话
{
"conversation": [
{
"system": "你是一个煤矿安全领域的知识达人,你会解答很多题。用户给出一个判断题,然后你作出判断,是正确还是错误。",
"input": "国家对在改善安全生产条件、防止生产安全事故、参加抢险救护等方面取得显著成绩的单位给予奖励;个人给予鼓励。",
"output": "错误"
}
]
},
#多轮对话
{
"conversation": [
{
"system": "你是一名煤矿安全领域的知识达人,提供有关煤矿安全规程、事故预防措施和应急响应的知识。",
"input": "你好!",
"output": "您好,我是一名煤矿安全领域的知识达人,请问有什么可以帮助您?"
},
{
"input": "2022年9月11日晋能控股集团山西三元煤业股份有限公司下霍煤矿井下无轨胶轮车大巷车场发生了什么事故?",
"output": "2022年9月11日,晋能控股集团山西三元煤业股份有限公司下霍煤矿井下无轨胶轮车大巷车场发生了一起运输事故,造成1人死亡。"
},
{
"input": "请告诉我这起事故的直接原因是什么?",
"output": "事故直接原因是井下进行设备换装作业时,机电机运队跟班副队长池晶晶在未采取并确认有效防倒措施的情况下,违章指挥并参与卸车作业,且其本人处在竖装设备倾倒危险区域内,被突然倾倒的端头支架前梁和侧护板砸压受伤致死。"
},
{
"input": "那么,这起事故的间接原因有哪些?",
"output": "事故间接原因包括现场监督管理严重缺失、规程措施审批把关不严、职工安全风险意识淡薄、上级主体企业责任落实不到位、地方安全监管部门监管不到位。"
},
{
"input": "为了避免类似事故,煤矿企业应该采取哪些措施?",
"output": "为了避免类似事故,煤矿企业应严格执行安全规程,加强现场安全管理,确保安全技术措施到位,强化安全风险研判,建立完善的安全技术管理体系,落实安全生产主体责任,加强安全教育培训,提高职工安全意识和风险辨识能力,同时加强安全监管,确保监管工作细致认真。"
},
{
"input": "感谢您的详细解答!",
"output": "不客气,很高兴能帮助到您。如果您还有其他问题,欢迎继续提问。"
}
]
},
复制根据需要改写 config.config 文件:
#llm存放位置
model_dir = os.path.join(base_dir, 'model')
#向量化模型路径以及模型名称
embedding_path = os.path.join(model_dir, 'embedding_model') # embedding
embedding_model_name = 'BAAI/bge-small-zh-v1.5'
#精排模型路径以及模型名称
rerank_path = os.path.join(model_dir, 'rerank_model') # embedding
rerank_model_name = 'BAAI/bge-reranker-large'
#召回documents数量
retrieval_num = 3
#精排后最终选择留下的documents数量
select_num = 3
prompt_template = """
你是一个乐于助人的问答代理人。\n
你的任务是分析并综合检索回来的信息,从而提供有意义且高效的答案。
{content}
问题:{query}
"""
复制运行构建本地知识库脚本
python data_generate.py复制
向量化主要步骤如下:
加载pdf数据集并提取文本
利用RecursiveCharacterTextSplitter按照一定块的大小以及块之间的重叠大小对文本进行分割。
加载 BAAI/bge-small-en-v1.5 模型
根据文档集构建FAISS索引(即高性能向量数据库)
利用faiss找出与用户输入的问题最相关的文档,然后将召回出来的文本与用户原始输入拼接输入给llm。检索代码如下:
def get_retrieval_content(self, querys) -> str: """ Input: 用户提问, 是否需要rerank ouput: 检索后的内容 """ #print(querys) output = [] content = [] for query in querys: documents = self.vectorstores.similarity_search(query, k=self.retrieval_num) for doc in documents: content.append(doc.page_content) logger.info(f'Contexts length:{len(content)}') if self.rerank_flag: model = self.data_processing_obj.load_rerank_model() documents = self.data_processing_obj.rerank(model, query, content, self.select_num) for doc in documents: output.append(doc) logger.info(f'Selected contexts length:{len(output)}') logger.info(f'Selected contexts: {output}') else: logger.info(f'Selected contexts: {content}') return output if self.rerank_flag else content复制
根据数据集构建 vector DB
对用户输入的问题进行 embedding
基于 embedding 结果在向量数据库中进行检索
对召回数据重排序
依据用户问题和召回数据生成最后的结果
cd CoalQA conda create -n CoalQA python=3.10.0 -y conda activate CoalQA conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia pip install -r requirements.txt cd web_app streamlit run streamlit_app.py --server.address=127.0.0.1 --server.port 6006复制
直接使用pytorch原生加载streamlit应用
streamlit run app.py --server.address=127.0.0.1 --server.port 6006
复制LMDeploy 由 MMDeploy 和 MMRazor 团队联合开发,是涵盖了 LLM 任务的全套轻量化、部署和服务解决方案。 这个强大的工具箱提供以下核心功能:
高效推理:LMDeploy 通过引入持久批处理(又称连续批处理)、阻塞式 KV 缓存、动态拆分与融合、张量并行、高性能 CUDA 内核等关键功能,将请求吞吐量提高到 vLLM 的 1.8 倍。
有效量化:LMDeploy 支持只加权量化和 k/v 量化,4 位推理性能是 FP16 的 2.4 倍。量化质量已通过 OpenCompass 评估确认。
轻松分发服务器:利用请求分发服务,LMDeploy 可在多台机器和卡上轻松高效地部署多模型服务。
交互式推理模式:通过缓存多轮对话过程中的关注度 k/v,引擎可记住对话历史,从而避免重复处理历史会话。
pip安装:
pip install lmdeploy复制
自 v0.3.0 起,默认预编译包在 CUDA 12 上编译。不过,如果需要 CUDA 11+,可以通过以下方式安装 lmdeploy:
export LMDEPLOY_VERSION=0.3.0 export PYTHON_VERSION=38 pip install https://github.com/InternLM/lmdeploy/releases/download/v${LMDEPLOY_VERSION}/lmdeploy-${LMDEPLOY_VERSION}+cu118-cp${PYTHON_VERSION}-cp${PYTHON_VERSION}-manylinux2014_x86_64.whl --extra-index-url https://download.pytorch.org/whl/cu118复制
使用LMDeploy与模型进行对话,可以执行如下命令运行下载的1.8B模型
lmdeploy chat /group_share/internlm2_chat_1_8b_qlora_18000复制
通过 --cache-max-entry-count参数,控制KV缓存占用剩余显存的最大比例为0.5
lmdeploy chat /group_share/internlm2_chat_1_8b_qlora_18000 --cache-max-entry-count 0.5复制
LMDeploy使用AWQ算法,实现模型4bit权重量化。推理引擎TurboMind提供了非常高效的4bit推理cuda kernel,性能是FP16的2.4倍以上。它支持以下NVIDIA显卡:
运行前,首先安装一个依赖库。
pip install einops==0.7.0复制
仅需执行一条命令,就可以完成模型量化工作。
lmdeploy lite auto_awq \
/group_share/internlm2_chat_1_8b_qlora_18000 \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 1024 \
--w-bits 4 \
--w-group-size 128 \
--work-dir /group_share/internlm2_chat_1_8b_qlora_18000-4bit
复制通过以下lmdeploy命令启动API服务器,推理模型:
lmdeploy serve api_server \
/group_share/internlm2_chat_1_8b_qlora_18000-4bit \
--model-format hf \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
复制即可以得到FastAPI的接口
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
参考链接
BGE Github
BAAI/bge-small-en-v1.5: embedding 模型,用于构建 vector DB
BAAI/bge-reranker-large: rerank 模型,用于对检索回来的文章段落重排
InternLM2
LangChain
FAISS