本应用基于开源UI框架PyDracula进行开发,除去最基本的UI框架外,所有功能的前后端实现都由我个人开发完成,但也有部分UI(如开关控件和进度条)是参考其他大佬的分享。
这个应用是我的本科毕业设计,但因为个人能力不足,姑且只能使用Python+PySide6开发。
开发这个应用的启发是,曾经我作为深度学习的萌新,在初出训练模型时费了不少力气去学习,一个人摸索了很长时间,直到现在我可以熟练掌握模型的训练。回过头来看我曾经踩过的坑,我把自己在模型训练过程中经常使用的图像处理脚本工具集成在了这个应用中,并实现了一站式的模型选择可视化训练。
但我也知道,真正训练一个好模型远比这复杂的多,因此本应用可以当作新手朋友们的入门体验。
希望本应用能对大家有所帮助。
本应用主要分为三大功能:
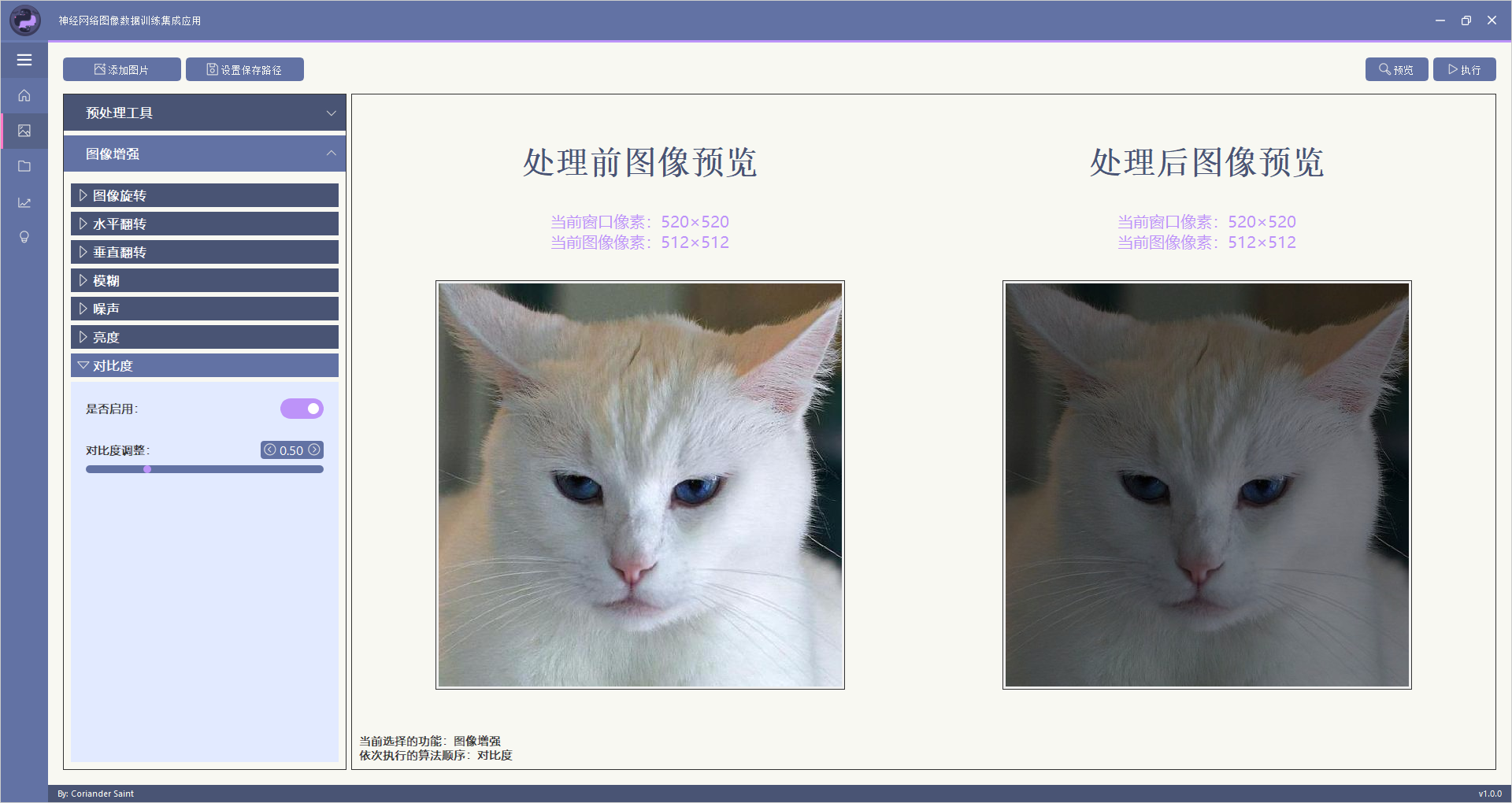
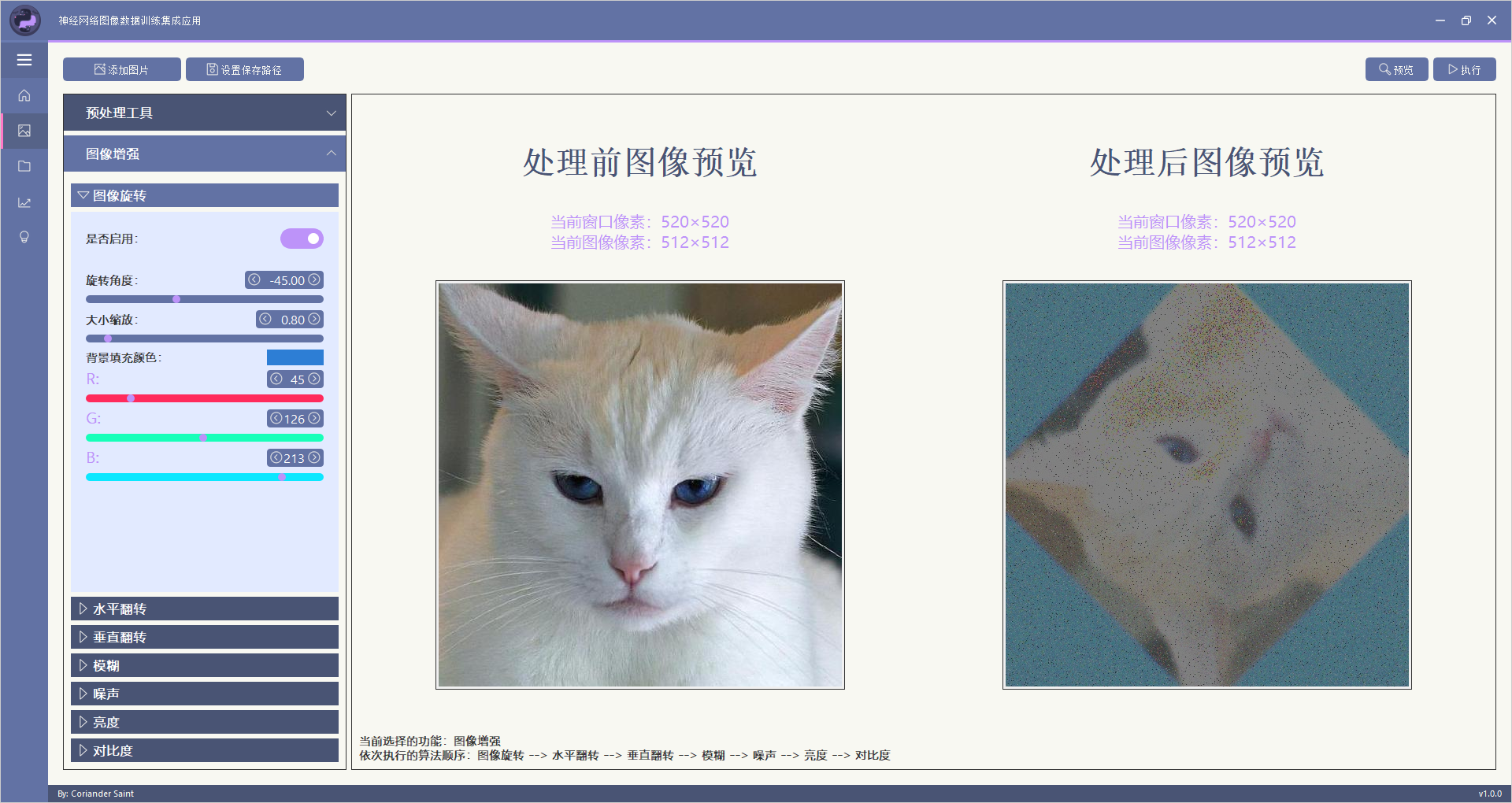
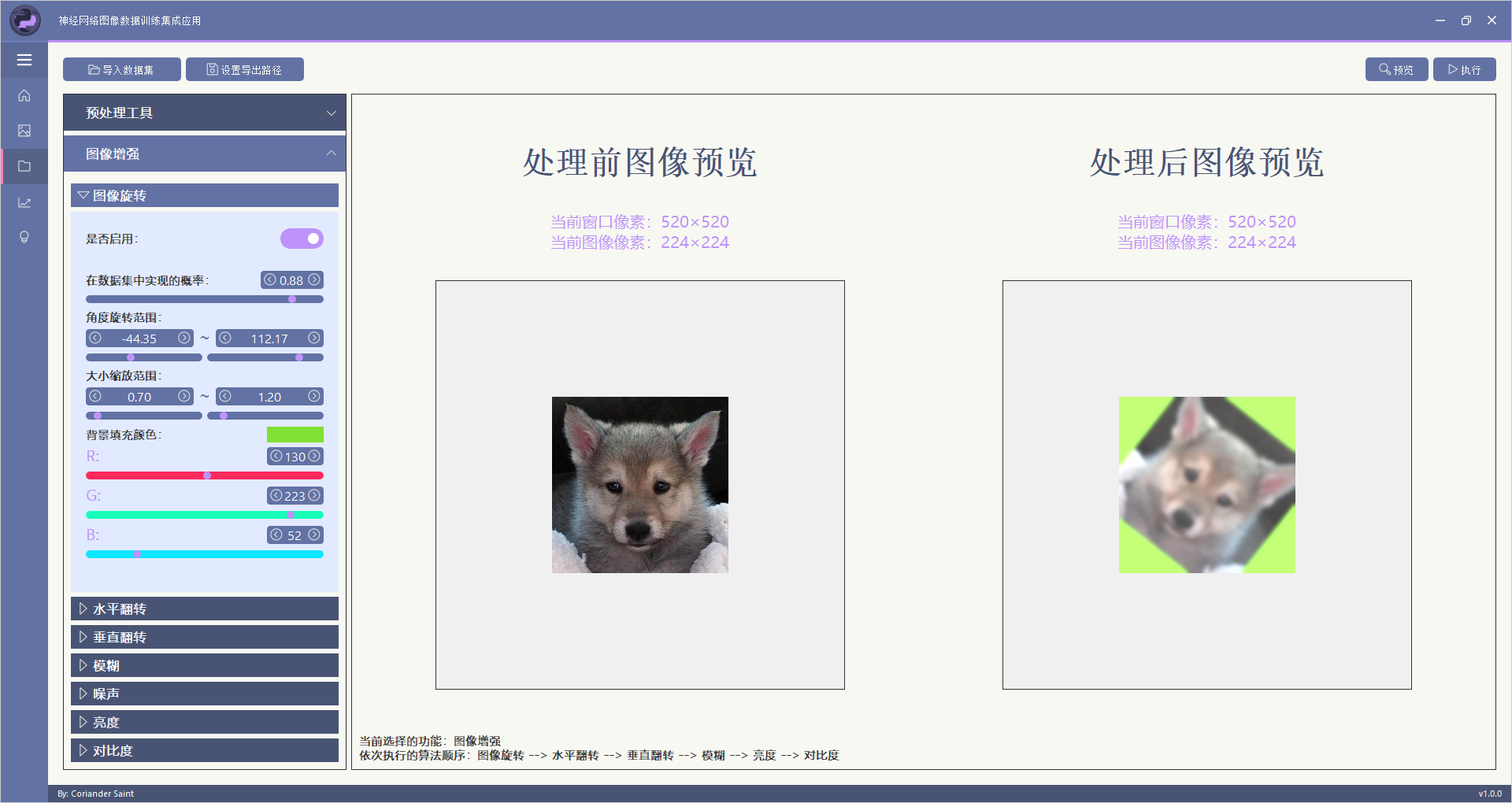
本部分功能主要实现仅对一张图片的处理,该功能分为预处理工具和图像增强两部分。
在这部分功能中实现了对图片后缀的修改,可以支持jpg、jpeg、png和bmp四种常见数据集图像格式图片的后缀更改,用户通过点击相应的按钮,执行对应的功能。
修改为.jpg后缀功能:
将图片统一转为 *.jpg 后缀。支持转换 *.JPG、*.png、*.PNG、*.jpeg、*.JPEG、*.bmp、*.BMP。
修改为.jpeg后缀功能:
将图片转为 *.jpeg 后缀。支持转换 *.jpg、*.JPG、*.png、*.PNG、*.JPEG、*.bmp、*.BMP后缀格式。
修改为.png后缀功能:
将图片转为 *.png 后缀。支持转换 *.jpg、*.JPG、*.PNG、*.jpeg、*.JPEG、*.bmp、*.BMP后缀格式。
修改为.bmp后缀功能:
将图片转为 *.bmp 后缀。支持转换 *.jpg、*.JPG、*.png、*.PNG、*.jpeg、*.JPEG、*.BMP后缀格式。

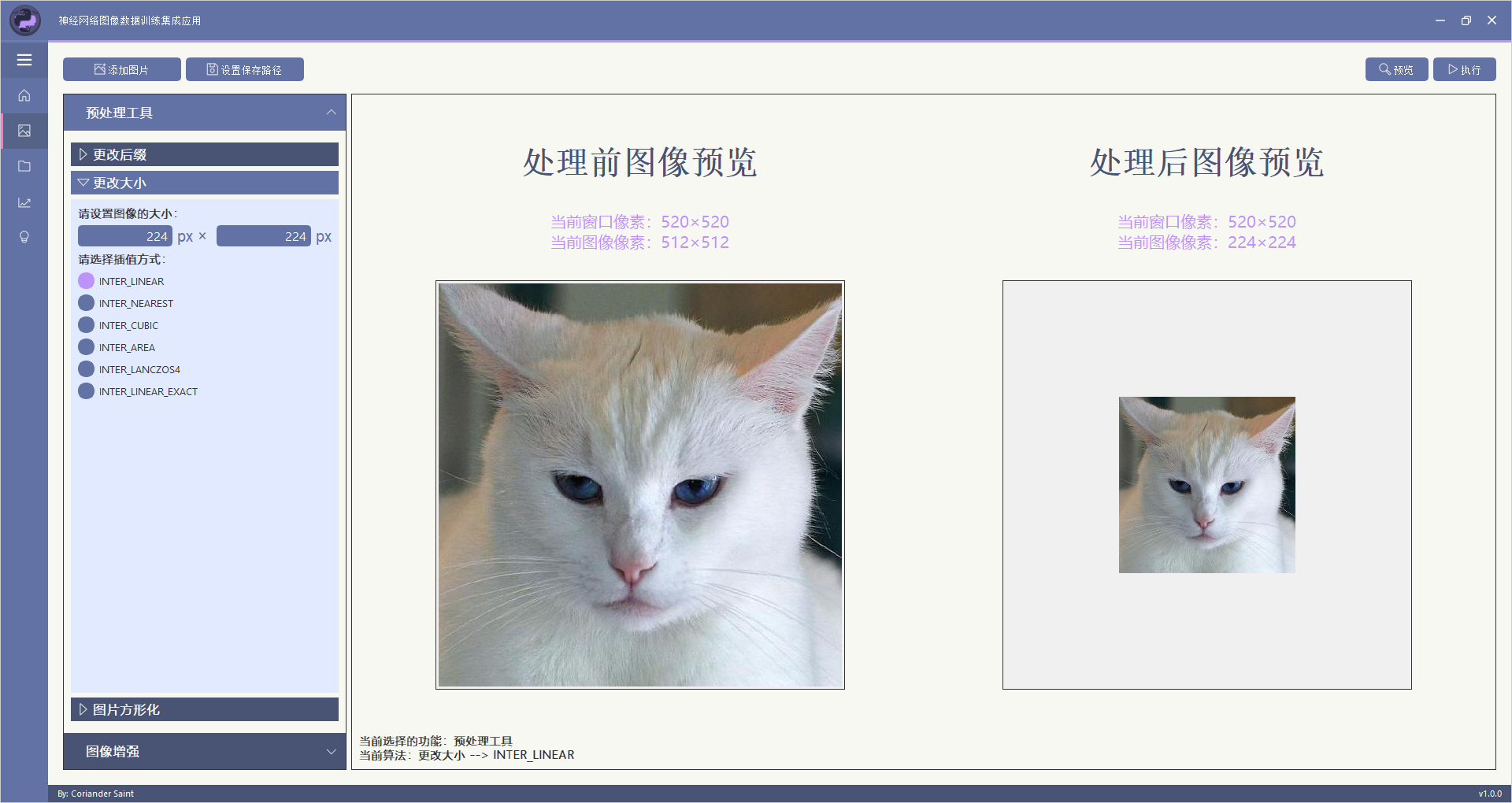
该部分功能实现了直接将图片像素大小进行修改。插值方式说明如下:
| 插值方式 | 说明 |
|---|---|
| INTER_LINEAR | 双线性插值。 |
| INTER_NEAREAST | 最邻近插值。 |
| INTER_CUBIC | 三次样条插值。 |
| INTER_AREA | 区域插值。(使用像素面积关系进行重采样) |
| INTER_LANCZOS4 | 一种Lanczos插值方法(超过8×放大时效果最好)。 |
| INTER_LINEAR_EXACT | 位精确双线性插值。 |
该部分功能实现了将不规则矩形图片统一为方形图片。
该功能模块所支持的边框拓充方式有:
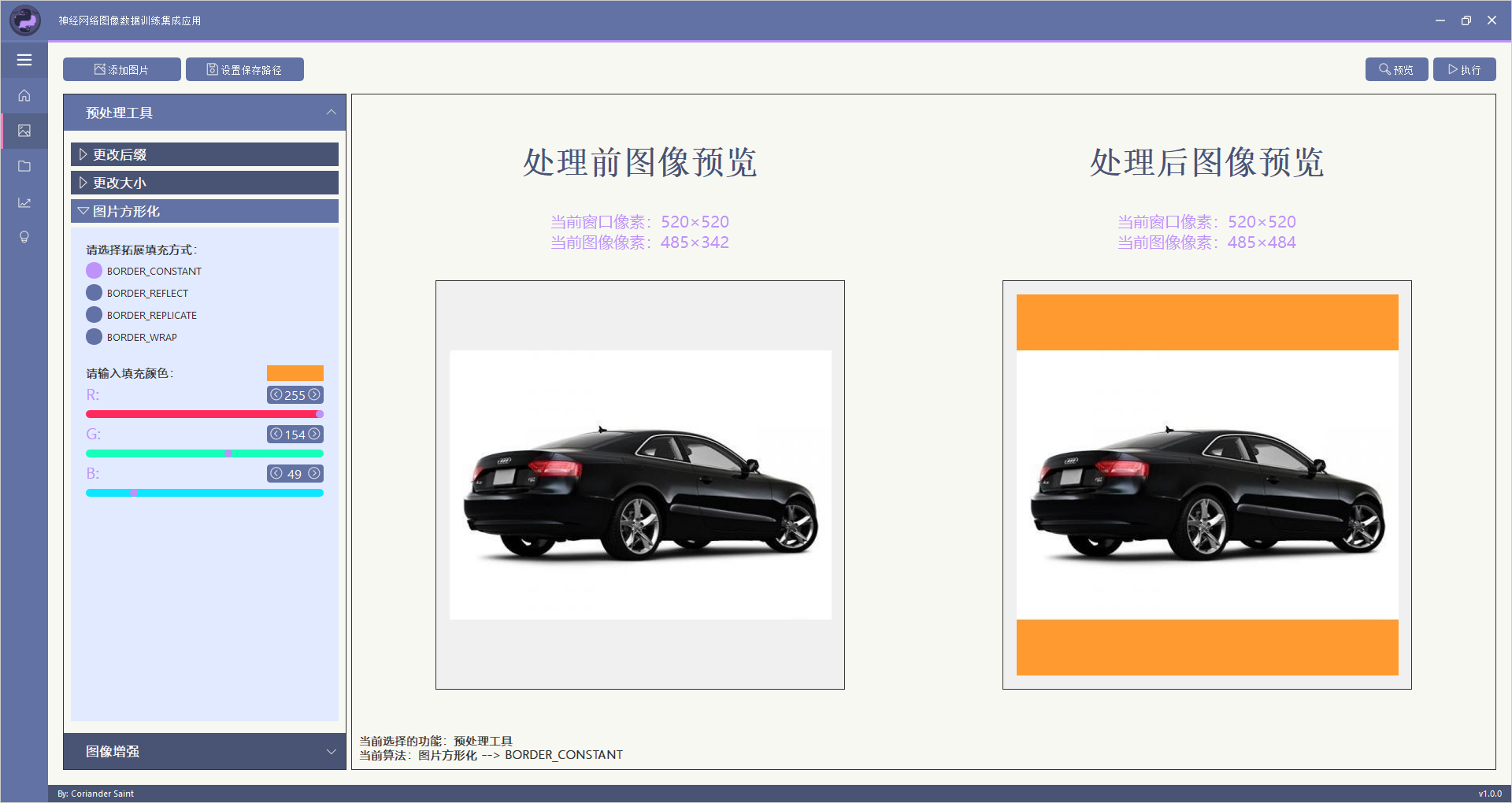
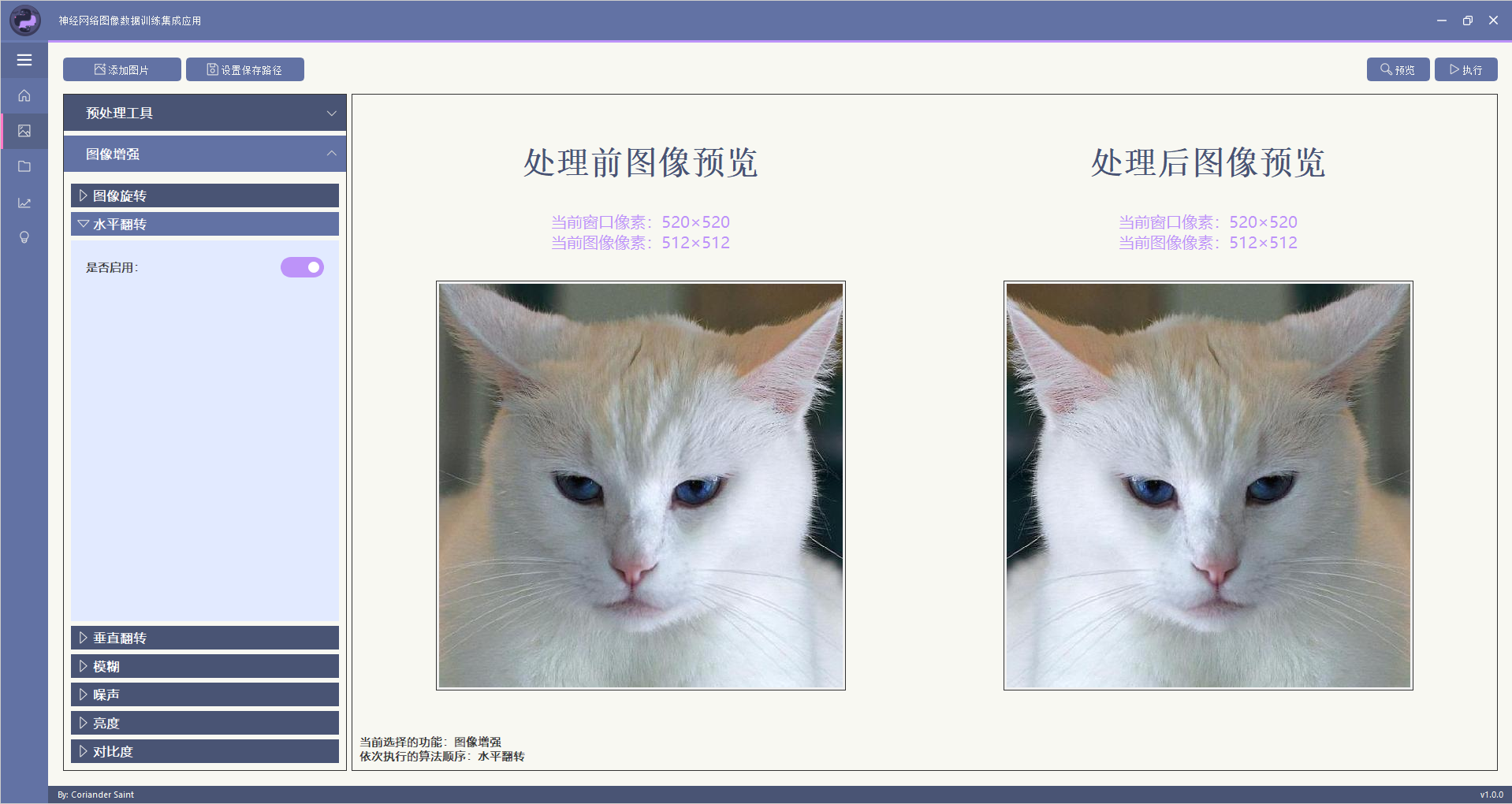
注意:本部分所有功能可以按顺序同时叠加使用。
该功能可使图像进行任意角度旋转,并同时缩放处理。


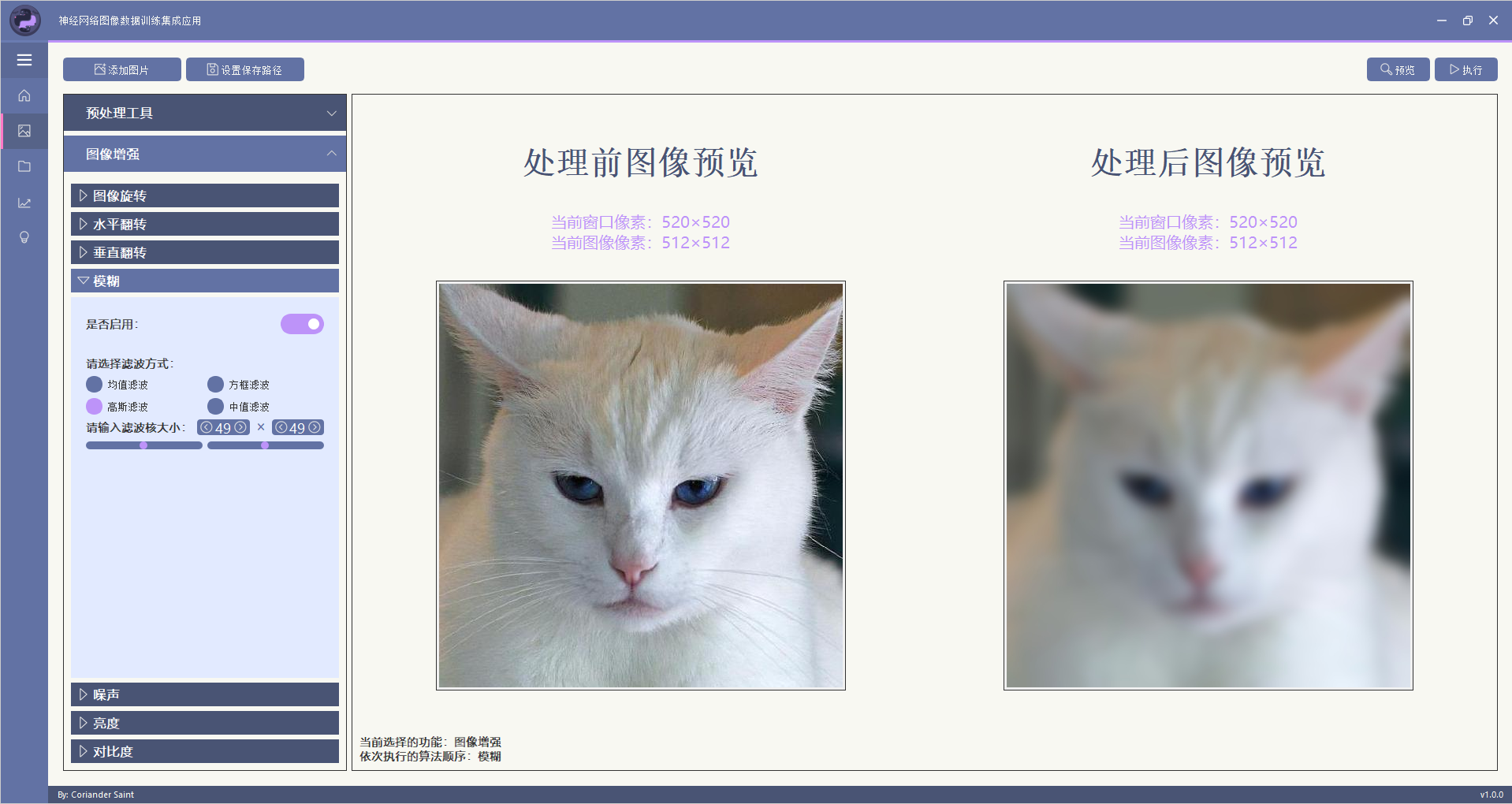
该功能可对图像进行模糊处理,支持四种滤波方式:
该功能可对图像增加噪声,支持两种噪声方式:
这两种方式可以单独使用,也可以同时使用。


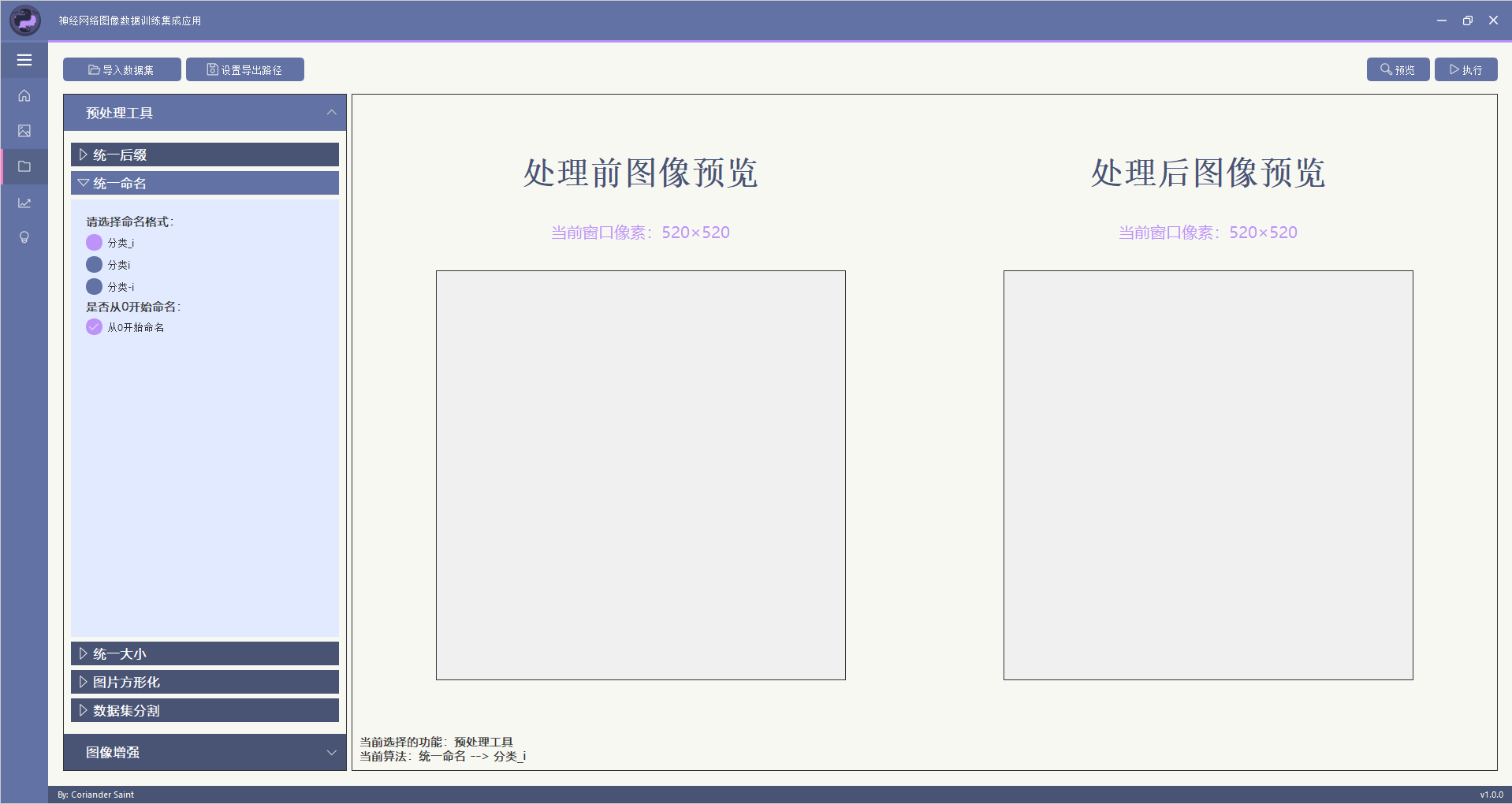
本部分功能主要实现对整个数据集图片的处理,该功能分为预处理工具和图像增强两部分。
该功能和单张图片预处理的更改后缀功能类似,故不再过多赘述。
在该模块下,用户可以对数据集进行统一命名,支持的统一命名格式为:
该功能和单张图片预处理的更改大小功能类似,故不再过多赘述。
该功能和单张图片预处理的图片方形化功能类似,故不再过多赘述。
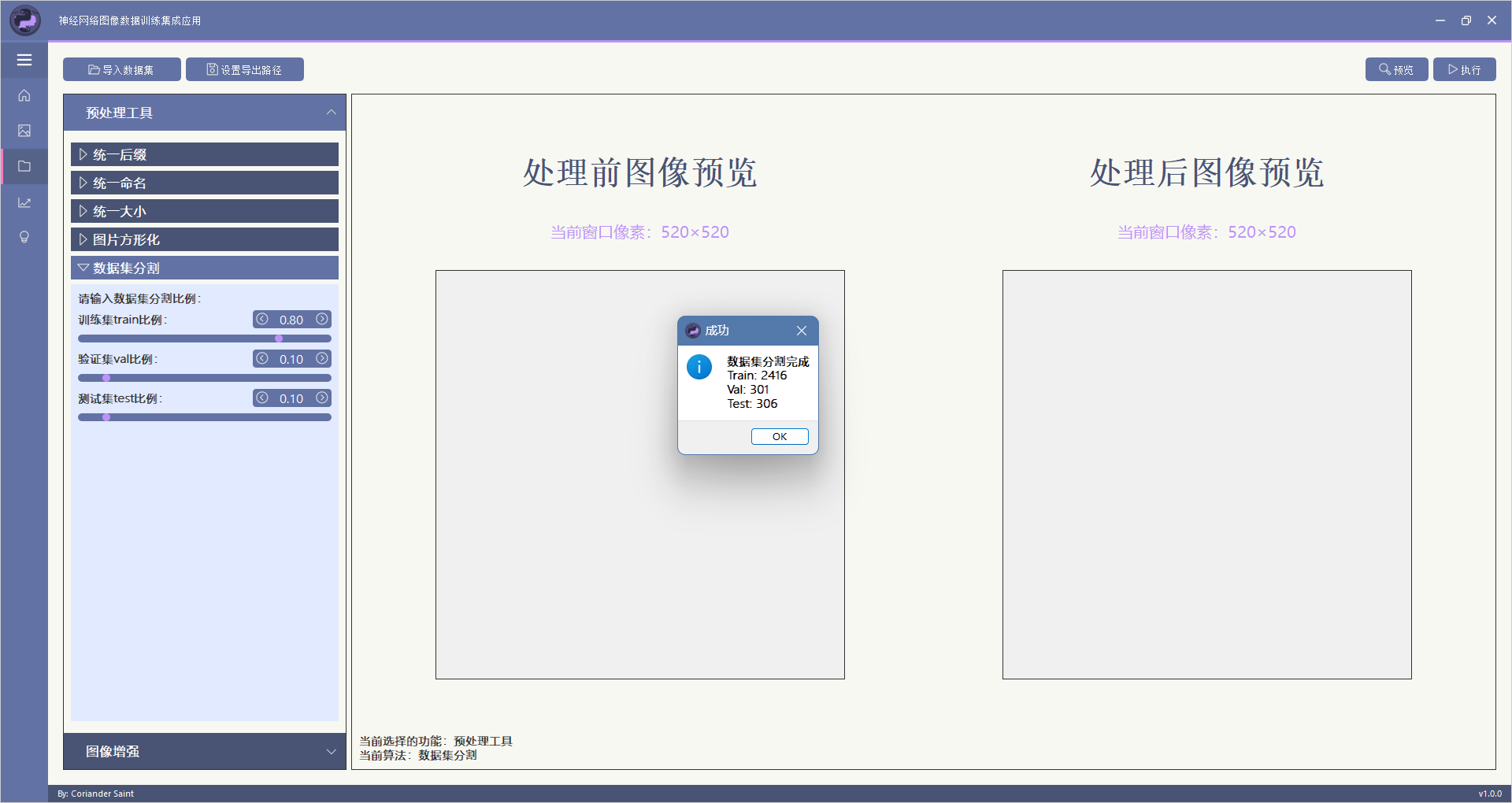
该功能用于将整个数据集按照比例分割成训练集(Train)、验证集(Val)、测试集(Test)。
该模块的图像增强功能实现了图像旋转、水平翻转、垂直翻转、模糊、噪声、亮度和对比度的功能,功能的实现同单张图像预处理模块的图像增强功能相似,故不再重复说明。
不同之处在于,由于该模块下的图像增强功能是对整个数据集进行处理,因此该功能引入了概率随机处理,以及参数在一个区间内随机取值。
同样:本部分所有功能可以按顺序同时叠加使用。
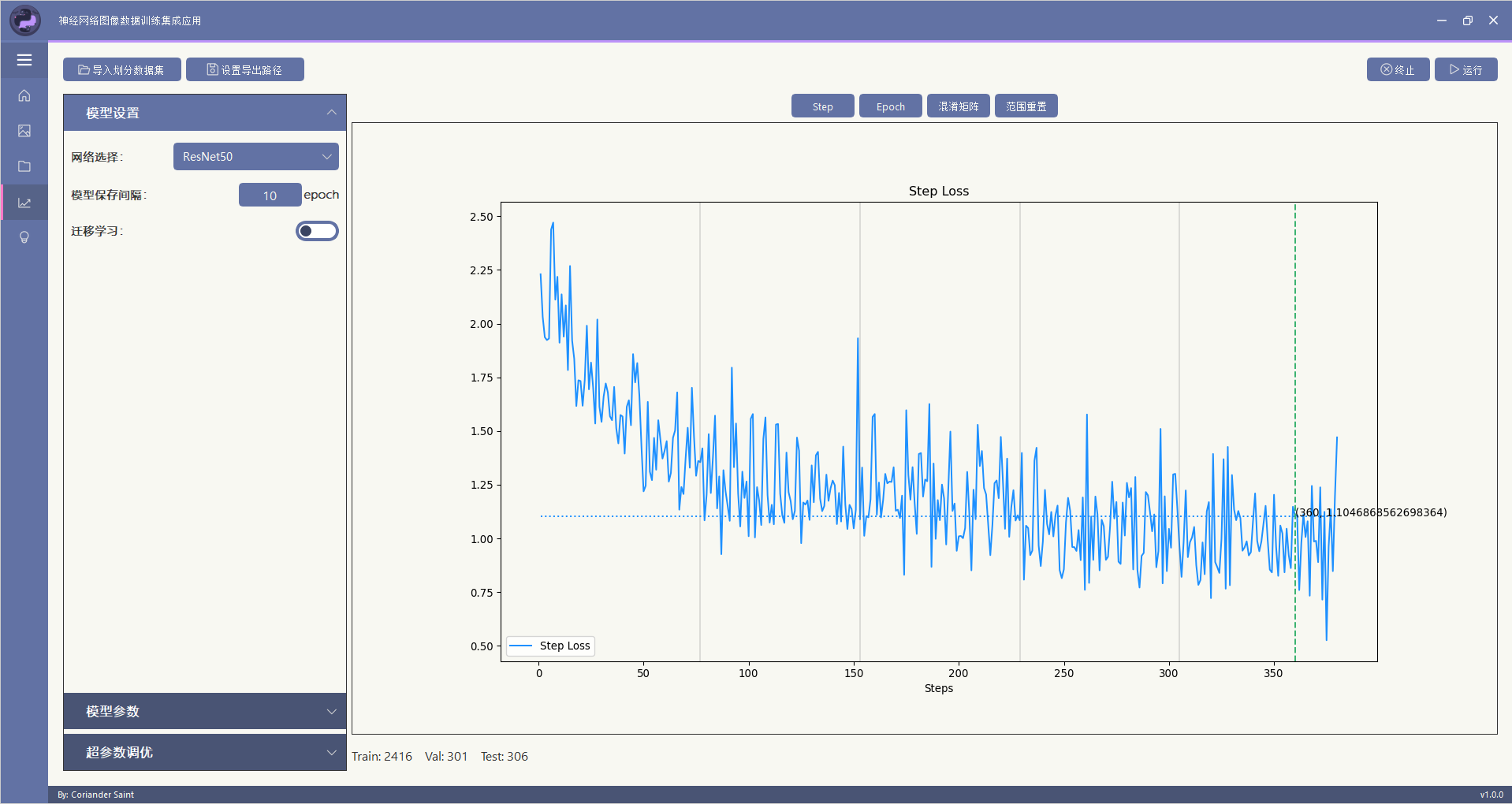
在该模块中,可以使用预集成在应用内的36神经网络模型进行训练,包含如下模型:
可以直接使用以上模型进行训练,如果不开启迁移学习则是重新从头开始训练自己的数据集,如果需要使用迁移学习,则需要自行下载官方的.pth权重文件,具体操作事项在后续的说明中陈述。
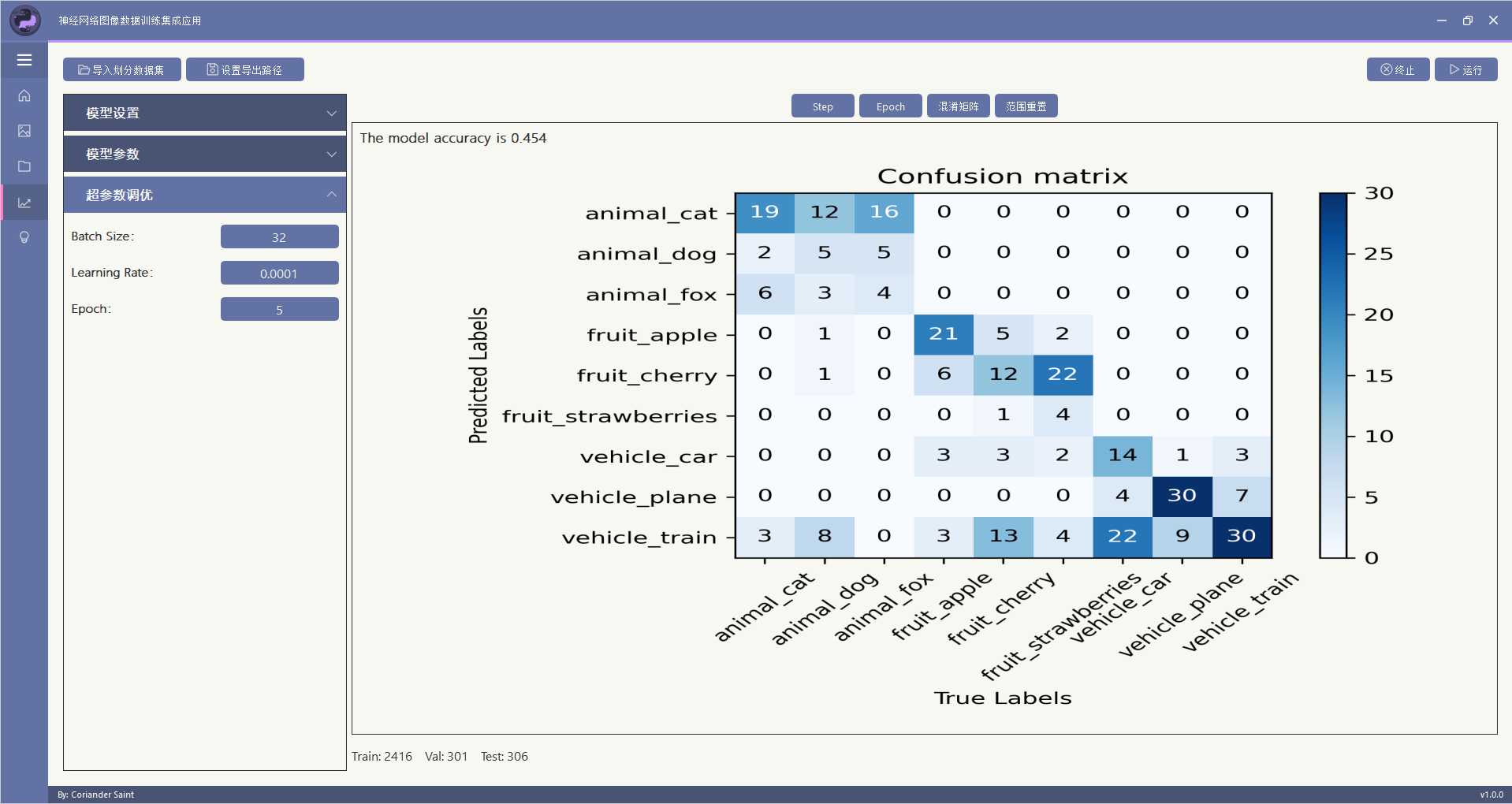
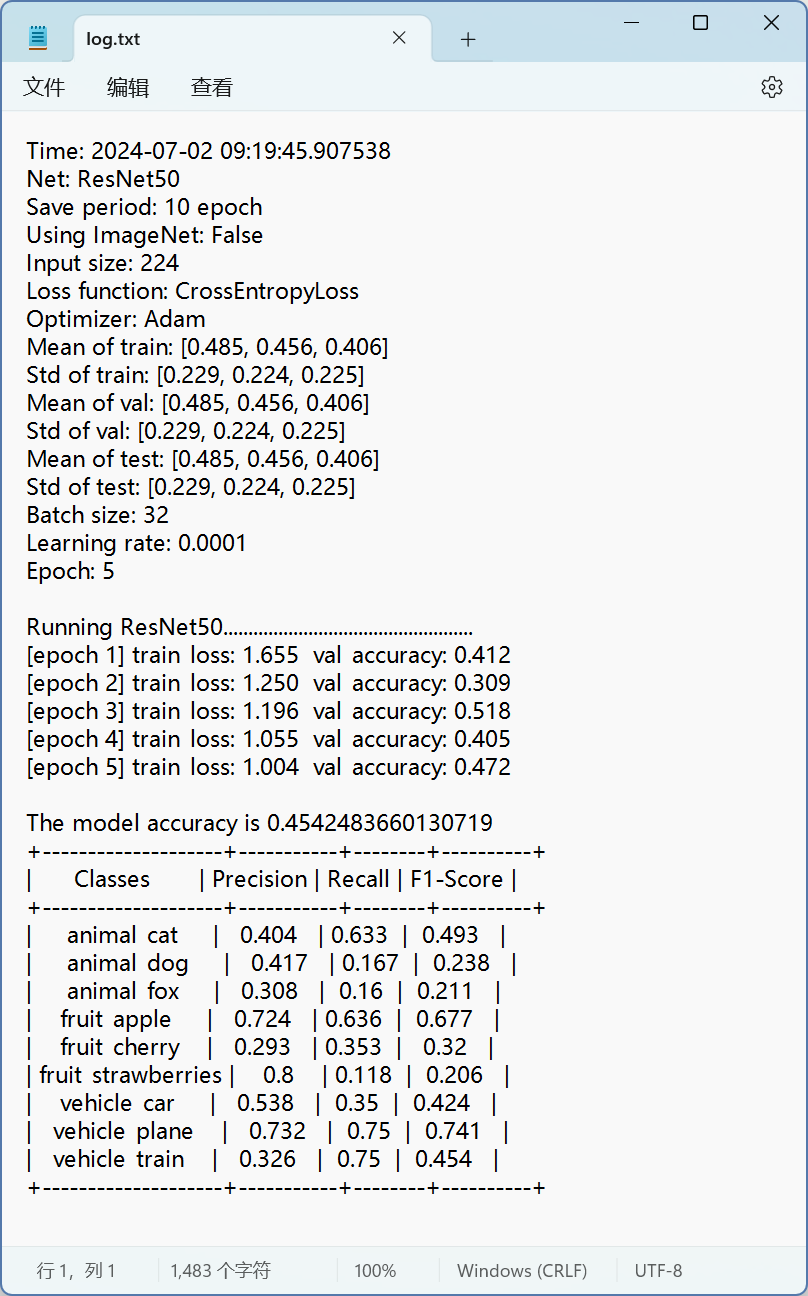
本功能除了实现训练过程可视化,还可以在训练完成后查看混淆矩阵,以及log输出。
注意:本功能暂未实现继续训练的功能,因此建议使用者在无法确定何时停止训练的情况下,将Epoch数值设置到一个较大的值,在通过可视化确认差不多收敛时点击终止按钮停止训练。

本程序在使用时需要安装以下Python环境:
本应用的图像处理功能由OpenCV实现,相关参数请参考OpenCV的参数说明。
数据集预处理功能中,传入的数据集文件夹格式必须严格按照如下方式:root文件夹/分类1..n文件夹/图片1..n
可视化训练器部分中,模型的训练是基于PyTorch深度学习框架实现的,因此最终训练后保存的权重文件是以.pth后缀结尾的形式,如果需要其它形式,可以自行进行权重文件格式的转换。
如果需要使用迁移学习,请自行下载官方权重文件放在 algorithms/trainer/imagenet 目录下,并将下载后的权重文件重命名为“xxx.pth”,且命名必须为如下命名之一:
alexnet.pth、efficientnet_b0.pth、efficientnet_b1.pth、efficientnet_b2.pth、efficientnet_b3.pth、efficientnet_b4.pth、efficientnet_b5.pth、efficientnet_b6.pth、efficientnet_b7.pth、efficientnet_v2_l.pth、efficientnet_v2_m.pth、efficientnet_v2_s.pth、googlenet.pth、mobilenet_v2.pth、mobilenet_v3_large.pth、mobilenet_v3_small.pth、resnet101.pth、resnet152.pth、resnet18.pth、resnet34.pth、resnet50.pth、resnext101_32x8d.pth、resnext50_32x4d.pth、shufflenetv2_x0_5.pth、shufflenetv2_x1_0.pth、shufflenetv2_x1_5.pth、shufflenetv2_x2_0.pth、swin_b.pth、swin_s.pth、swin_t.pth、vgg11.pth、vgg13.pth、vgg16.pth、vgg19.pth、vit_b_16.pth、vit_b_32.pth
完整应用程序已免费开源在我的GitHub中:https://github.com/CorianderSaint/TrainerGUI。
请需要者点一颗免费的Star⭐,十分感谢!