再一次轮到讲自己的paper!耶,宣传一下自己的工作,顺便完成中文博客的解读 方便大家讨论。
Title Picture

Reference and pictures
paper: https://arxiv.org/abs/2401.16122
这个启发主要是和上一篇 动态障碍物去除 的有一定的联系,去除完了当然会开始考虑是不是可以有实时识别之类的, 比起只是单纯标记1/0 的动和非动分割以外会是什么?然后就发现了 任务:scene flow,其实在2D可能更为人所熟知一些:光流检测,optical flow,也就是输入两帧连续的图片,输出其中一张的每个pixel的运动趋势,NxNx2,其中N为图片大小,2为x,y两个方向上的速度

对应的 3D情况下 则是切换为 输入是两帧连续的点云帧,输出一个点云帧内每个点的运动,Nx3,N为点云帧内点的个数,3为x, y, z三个轴上的速度

首先关于在自动驾驶的光流任务,我们希望的是能满足以下两个点:
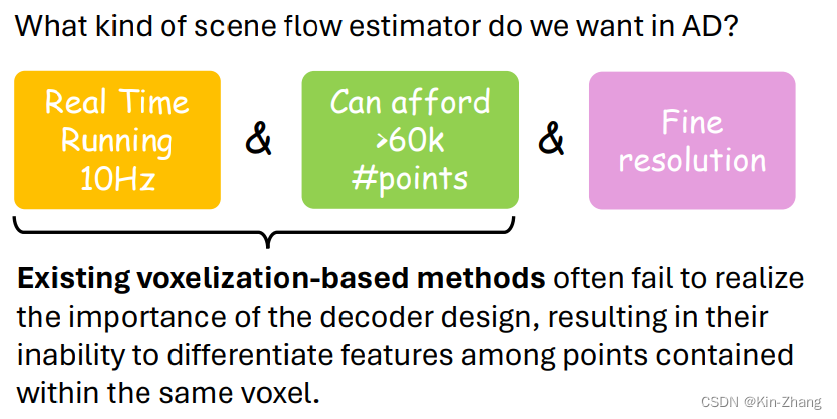
那么Voxelization-based method就是其中大头 or 唯一选择了;
接着故事就来到了 启发DeFlow的点:在查看最近工作(于2023年8月附近查看),阅读相关资料时发现,很多自监督的paper都声称自己超过了 某篇监督的模型效果,也就是Waymo在RA-L发的一篇dataset顺带提出了FastFlow3D(官方闭源,民间有复现);但是实际上 FastFlow3D本身就是参考3D detection那边网络框架进行设计的,仅将最后的decoder 连一个 MLPs 用以输出point flow
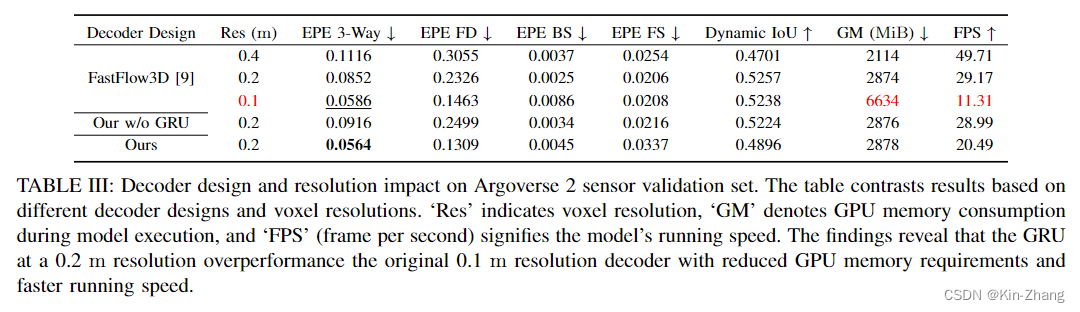
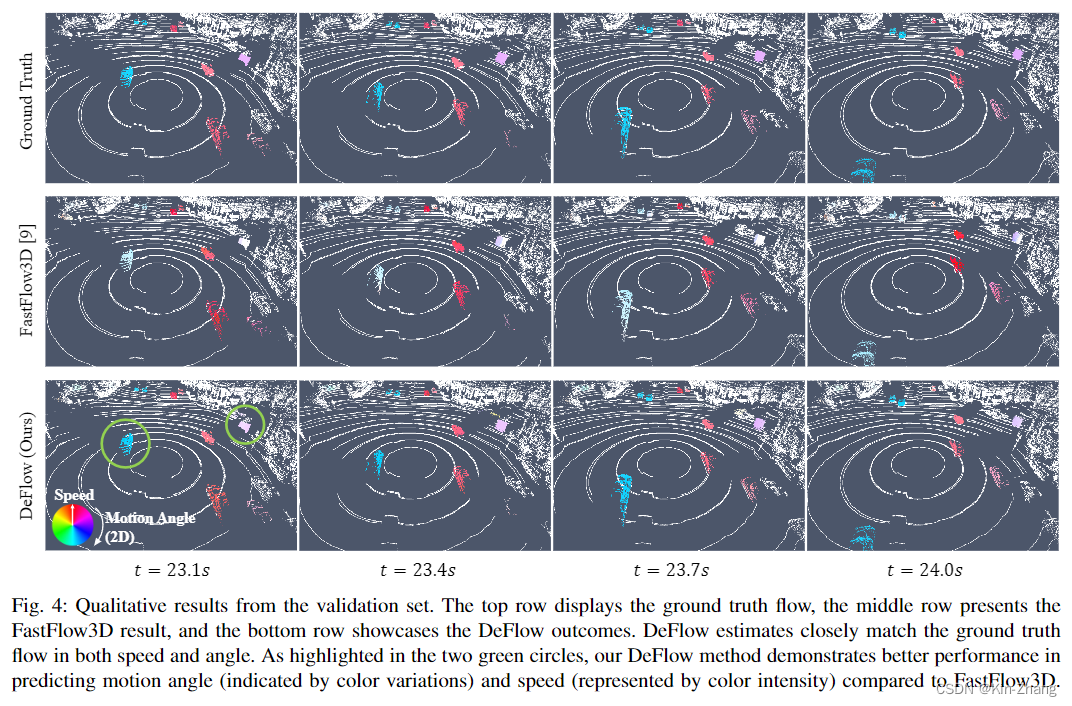
在我们的实验中发现,特别是在resolution用的20cm的时候,效果确实不好,主要原因集中在于下图2,统计发现如果一个点在动(速度≥0.5m/s),那么绝大多数都是在0.2以下的距离内运动;那么动一动脑筋,我们就想到了 调参,直接把resolution调到10cm不就行了?没错!DeFlow 实验表格 Table III 第三行证明确实直接double kill
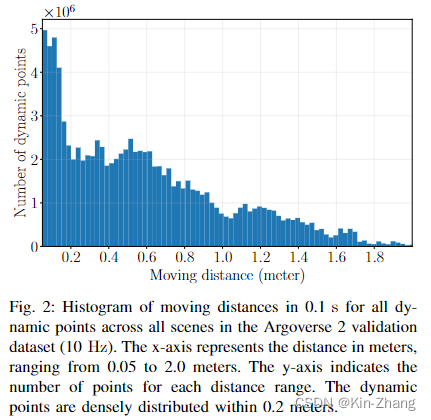
那么我们就知道了20cm 的栅格化分辨率下,点都在一个栅格里运动,所以前期pillar encoder 根本无法学出同一个voxel内不同点的feature,而FastFlow3D本身的decoder又是非常简单的MLP提取,无法实现voxel-to-point feature extraction
所以我们的贡献就以以上为基础来讲述的啦,总结就是:1、提出了一个基于GRU voxel-to-point refinement的decoder;2、同时分析了以下loss function的影响并快速提了一个新的;3、最后实验到 AV2 官方在线榜单的SOTA
note:所有代码,各种对比消融实验 和 刷榜所用的model weight全部都开源供大家下载查阅,欢迎star和follow up:https://github.com/KTH-RPL/DeFlow

非常简单易懂的方法部分,特别配合代码使用
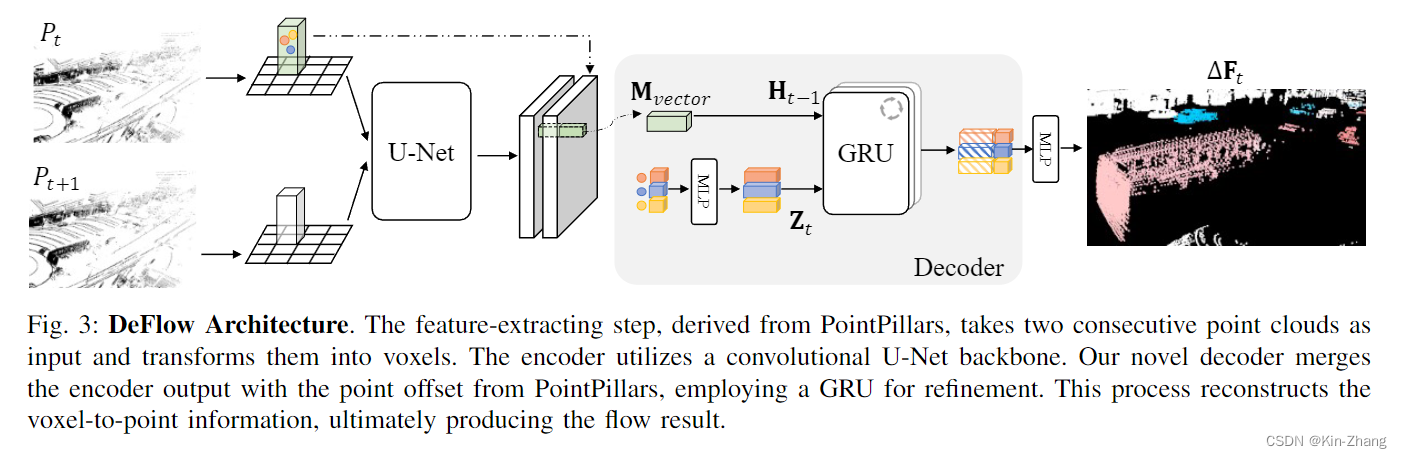
输入是两帧点云,具体一点 和FastFlow3D还有一系列的3D detection 一样;我们会先做地面去除,所以实际输入已经去掉了地面的 \(P_t, P_{t+1}\)
然后我们要估计的是 P_t 的 flow F,其中根据ego pose信息,我们也专注于预测除pose flow外的,也就是环境内的属于动态物体带速度的点
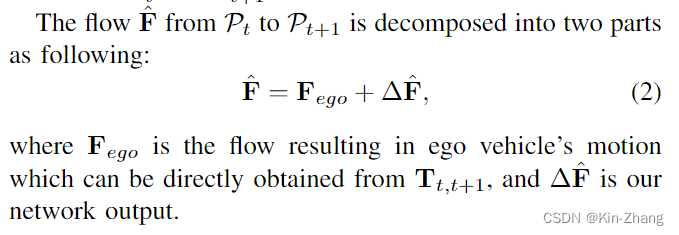
看代码可能更快一点,论文和图主要是给了一个insight :
此处为对照代码,方便大家直接对照查看,具体在以下两个文件:
def forward_single(self, before_pseudoimage: torch.Tensor,
after_pseudoimage: torch.Tensor,
point_offsets: torch.Tensor,
voxel_coords: torch.Tensor) -> torch.Tensor:
voxel_coords = voxel_coords.long()
after_voxel_vectors = after_pseudoimage[:, voxel_coords[:, 1],
voxel_coords[:, 2]].T
before_voxel_vectors = before_pseudoimage[:, voxel_coords[:, 1],
voxel_coords[:, 2]].T
# [N, 64] [N, 64] -> [N, 128]
concatenated_vectors = torch.cat([before_voxel_vectors, after_voxel_vectors], dim=1)
# [N, 3] -> [N, 64]
point_offsets_feature = self.offset_encoder(point_offsets)
# [N, 128] -> [N, 128, 1]
concatenated_vectors = concatenated_vectors.unsqueeze(2)
for itr in range(self.num_iters):
concatenated_vectors = self.gru(concatenated_vectors, point_offsets_feature.unsqueeze(2))
flow = self.decoder(torch.cat([concatenated_vectors.squeeze(2), point_offsets_feature], dim=1))
return flow
复制然后self.gru则是由这个常规ConvGRU module生成,forward和如下公式 直接对应
# from https://github.com/weiyithu/PV-RAFT/blob/main/model/update.py
class ConvGRU(nn.Module):
def __init__(self, input_dim=64, hidden_dim=128):
super(ConvGRU, self).__init__()
self.convz = nn.Conv1d(input_dim+hidden_dim, hidden_dim, 1)
self.convr = nn.Conv1d(input_dim+hidden_dim, hidden_dim, 1)
self.convq = nn.Conv1d(input_dim+hidden_dim, hidden_dim, 1)
def forward(self, h, x):
hx = torch.cat([h, x], dim=1)
z = torch.sigmoid(self.convz(hx))
r = torch.sigmoid(self.convr(hx))
rh_x = torch.cat([r*h, x], dim=1)
q = torch.tanh(self.convq(rh_x))
h = (1 - z) * h + z * q
return h
复制所以和其他对GRU的用法不同,主要是我们将其用于voxel和point 之间细化特征提取了,当然代码里也有我第一次的MM TransformerDecoder 和 直接的 LinearDecoder尝试 hahah;前者太慢了,主要是点太多 我分了batch;后者效果不行,带代码就当附带都留下来了
然后论文里讲了以下loss function的设计,过程简化以下就是:之前的工作一般,在和gt的norm基础上 都自己给设计不同的权重,比如这里的 \(\sigma\)
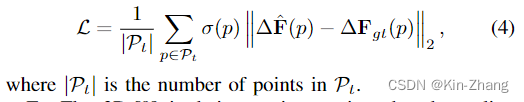
结论就是我们这样设计的,根据ZeroFlow的三种速度划分,我们不用权重而是直接unified average;实验部分会说明各个module的进步

OK 方法到这里就结束了,自认为非常直觉性的讲故事下来的 hahaha,然后很多实验在各种角度模块进行证明我们的statement
这个是直接抽的leaderboard的表格,具体每个方法的文件 见 https://github.com/KTH-RPL/DeFlow/discussions/2

前三者都是自监督 每篇都说超过了监督方法 FastFlow3D,但实际上只是baseline weak了,或者说他们比不过 FastFlow3D 10cm (0.1m)的分辨率,ZeroFlow XL就是把分辨率降到了0.1 然后加大了网络;OK leaderboard (test set 只能上传到在线平台评估) 的分析就这样了,知道SOTA就行
接下来的所有评估都是本地的,因为在线平台有提交次数限制 hahaha;首先贴出 Table III:注意这之中仅改变了decoder,其他loss func, learning rate, 训练条件均保持一致
这张表格也就是我们说的 我们的decoder提出 不需要细化10cm分辨率;因为这样GPU的Memory 大大上升了,总得留点给其他模块用嘛,见FastFlow3D 0.1 第三行
而我们保持了20cm的分辨率 速度和GPU内存使用均无太多上涨的情况下,我们的EPE 3-Way的分数甚至比FastFlow3D 细化10cm的还要好,误差比原来的 低了33%
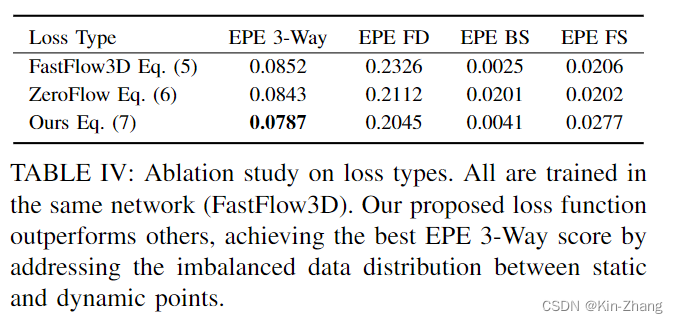
Loss Function:注意此处我们全部使用FastFlow3D的network,仅loss function不同而已
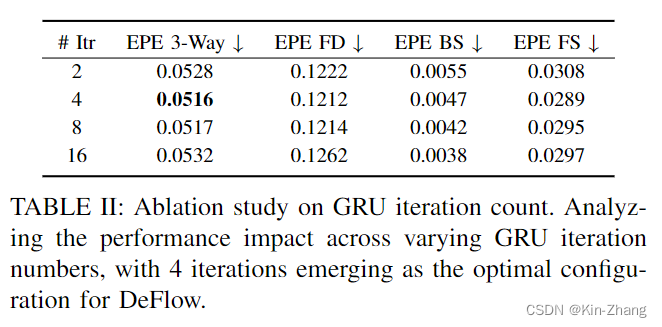
decoder iter number:其实我不太想做这个实验,但耐不住可能审稿人要问,所以我当时initial是选2/4跑的,毕竟多了降速 hahaha;此处全部使用deflow,仅iteration number不同,所以第二行可以认为是deflow: our decoder+our loss的效果(因为Table III为了对decoder的消融,所以其实我们使用的是fastflow3d提出的loss function;途中有韩国老哥没看论文,只要结果,所以他跑提供的weight的结果比我好,其实是他看错了表 lol)
主要就是快速看看就行,code那边还有10秒 demo视频可看
结论重复了一遍贡献

然后说了以下future work:自监督的模型训练,毕竟gt难标呀;欢迎查看最新ECCV2024的工作SeFlow,也就是我当时写下future work的时候已经在尝试路上的时候了;同开源(只要我主手的工作都开源 并在文章出版前 code上传完全能复现论文结果,我的信条 hahaha)
赠人点赞 手有余香 😆;正向回馈 才能更好开放记录 hhh