环境变量是指操作系统中记录一些配置信息的变量,这些变量在不同的程序之间共享,可以被操作系统或者 shell 脚本读取和修改。
环境变量也可以类比为各个语言中的全局变量,其作用域是全局的,所有的代码段或者说作用域都可以直接访问到这个变量。
查看你环境变量的命令是 printenv 或 env 。
env # 查看全部环境变量,只有这一种方式
printenv # 查看全部环境变量
printenv [变量名] # 查看指定环境变量的值
复制比如
SHELL=/bin/bash
ROS_VERSION=2
SESSION_MANAGER=local/ruby:@/tmp/.ICE-unix/1804,unix/ruby:/tmp/.ICE-unix/1804
QT_ACCESSIBILITY=1
COLORTERM=truecolor
XDG_CONFIG_DIRS=/etc/xdg/xdg-ubuntu:/etc/xdg
XDG_MENU_PREFIX=gnome-
GNOME_DESKTOP_SESSION_ID=this-is-deprecated
GTK_IM_MODULE=fcitx
PKG_CONFIG_PATH=:/usr/local/lib/pkgconfig
ROS_PYTHON_VERSION=3
LANGUAGE=zh_CN:zh:en_US:en
QT4_IM_MODULE=fcitx
MANDATORY_PATH=/usr/share/gconf/ubuntu.mandatory.path
LC_ADDRESS=zh_CN.UTF-8
GNOME_SHELL_SESSION_MODE=ubuntu
LC_NAME=zh_CN.UTF-8
SSH_AUTH_SOCK=/run/user/1000/keyring/ssh
XMODIFIERS=@im=fcitx
DESKTOP_SESSION=ubuntu
PATH=/opt/ros/foxy/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/usr/local/cuda-11.8/bin
复制上面就是使用 printenv 命令查看到的环境变量。可以看出其中指定了很多系统重要的变量,如SHELL表明了bash所在的路径,因此我们可以直接访问到bash而不用指定路径。而DESKTOP_SESSION则表明当前的发行版是Ubuntu。
设置环境变量的命令是 export 。
在设置环境变量前,先明确shell中的变量如何书写。
ENV=value # 等号左边为变量名,右边为变量值
复制这样就在shell中声明了一个变量。注意在一个shell中声明的变量,只对当前shell有效,不会影响其他shell。此时该变量只是普通的临时变量,不会被保存到环境变量中。
查看shell中的变量可以使用 echo 命令,echo可以将变量或者常量的值输出到终端。
echo "test echo"
test echo
复制因此也可以用来查看变量的值。
echo $ENV # 查看变量值
# 注意变量前要加$来取出其值
复制使用export来将变量导出为环境变量
export ENV # 将变量导出为环境变量
# 或者直接在export命令中指定变量名和值
export ENV=value
复制这样就可以在其他程序中使用该变量了。已经导出的环境变量可以直接全局赋值更改
ENV=new_value # 全局变量赋值
复制但是需要注意的是,对于使用命令行export导出的环境变量仅对该次会话生效,当关闭终端或者重新登录后,环境变量就会失效。如果想永久生效,需要修改系统配置文件。
在linux系统启动时,会自动按序读取一些配置文件并从中执行相应的shell命令。因此,我们只需要在这些配置文件中添加
export命令,即可设置永久的环境变量。
在ubuntu(不同发行版有所不同)下,比较常用的有如下几个配置文件:
- /etc/profile.d目录下的.sh文件和~/.bashrc 文件 对用户的shell进行初始化和环境变量设置
- ./.bash_profile.d目录下的文件和./bash_login 文件用于个别用户的shell环境初始化 用户登录时会读取内容
因此我们可以在这些文件中添加export命令来设置环境变量。
这里在选择在/etc/profile.d/目录下新建一个文件,叫做source_env.sh,并添加如下内容:
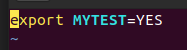
然后保存退出,执行
source /etc/profile.d/source_env.sh
# 这样可以直接生效,不需要重启系统
复制接着使用env或者printenv命令查看环境变量,就可以看到我们刚才设置的环境变量。
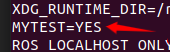

可以看到环境变量MYTEST已经被设置成功,并且可以被其他程序使用。
推荐使用新建文件的方式来添加自己的环境变量,这样可以避免对系统的其他部分造成影响,更加美观以及方便管理。
对于比较常用的环境变量,这里给出一个,
PATH环境变量
我们使用printenv查看PATH环境变量的值
printenv PATH
/usr/local/bin:/usr/local/sbin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/usr/local/cuda-11.8/bin
复制可以看到其中是一串以冒号分隔的目录路径,这些目录包含了一些系统命令的可执行文件路径,如ls、cd等常用命令,正是由于这些路径被记录在PATH环境变量中,我们才可以直接在命令行中使用这些命令。
可以使用witch + 空格 + 命令名 来查看某个命令的具体路径
which ls
/bin/ls
复制可以看到ls命令的具体路径是/bin/ls,而这个路径正是PATH环境变量中第一个目录/usr/bin中的一个。
因此在使用一些命令时报出command not found错误,可能是因为该命令的路径没有被添加到PATH环境变量中。可以使用locate命令来搜索带有某个关键字的文件路径,然后手动添加到PATH环境变量中。
locate ls # locate会搜索系统中所有文件名包含ls字符串的文件路径
/bin/ls
复制然后将该路径添加到PATH环境变量中即可。
在shell中可以使用alias(翻译过来就是别名)来查看当前目录下所有命令的别名,也可以设置新的别名。
查看当前shell下所有命令的别名
alias
复制设置新的别名
alias 别名='原命令'
复制比如
alias ll='ls -l' # 设置ll命令的别名为ls -l
alias lll = 'ls -alh' # 设置lll命令的别名为ls -alh
复制这样就可以使用新的别名来代替原命令,如ll命令等价于ls -l,lll命令等价于ls -alh。
但是注意,设置的别名只对当前shell有效,不会影响其他shell。依旧可以将其加入到配置文件中,让其永久生效。
若要移除别名,可以使用unalias命令。
unalias 别名
复制比如
unalias ll
复制这样ll命令的别名就被移除了。
若想移除该shell下所有别名,可以使用unalias -a命令。
unalias -a
复制当然,unalias命令仅在该shell下有效,不会影响其他shell。
linux最核心的思想就是一切皆文件,因此输入输出的控制也是由对应的文件来实现的。
在linux中,我们使用终端(terminal)来与计算机进行交互。终端的输入输出可以分为两种:
打开一个终端,执行如下命令:
ls -l /dev/{stdin,stdout,stderr}
lrwxrwxrwx 1 root root 15 6月 19 2024 /dev/stderr -> /proc/self/fd/2
lrwxrwxrwx 1 root root 15 6月 19 2024 /dev/stdin -> /proc/self/fd/0
lrwxrwxrwx 1 root root 15 6月 19 2024 /dev/stdout -> /proc/self/fd/1
复制可以看到在该终端下的stdin,stdout,stderr软链接到了/proc/self/fd/0,1,2三个文件上。而继续执行如下命令:
ls -l /proc/self/fd
lrwxrwxrwx 1 root root 0 6月 19 2024 /proc/self -> 10810
复制可以看到/proc/self目录下有一个软链接,指向当前进程的进程号。因此这样就可以知道当前进程的标准输入输出文件号。
linux中的管道(pipe)是实现进程间通信的一种方式,它允许将一个进程的输出作为另一个进程的输入。
其语法如下:
命令1 | 命令2复制
其中,命令1的输出会作为命令2的输入。
以上一节的例子为例,我们可以编写一个简单的shell来尝试管道的功能
# in pipe.sh
echo "该进程的进程号为$$" # echo $$ 输出当前终端的进程号
复制# in get.sh
read line # read + 变量名 可以从标准输入读取内容并赋值给变量
echo "读取到的行是:$line"
复制编写完这两个shell文件后赋予执行权限
chmod +x pipe.sh get.sh
复制然后运行
./pipe.sh |./get.sh复制
可以看到终端输出
该进程的进程号为10810复制
在使用管道符时,linux会隐式的创建一个临时的管道文件用来存储命令的输出,此时标准输出会软链到管道文件上,而标准输入则会软链到管道文件中读取内容。
当然,我们也可以显式的创建管道文件,称为具名管道
mkfifo 管道名 # 创建一个管道文件
复制这个管道文件是进程间通用的,可以被多个进程共享来读取。
可以使用cat命令或者echo >> 来读取和写入管道文件。
我们再理清2.1节中的一些概念。
- 对于每个终端,会有属于自己的进程号,并将其的输入输出以及错误输出文件号记录在/proc/self目录下。
- 而对于每个进程,其输入输出以及错误输出文件号被分配为0, 1, 2三个文件。
- 在不加更改的情况下,0, 1, 2都会软链到/dev/stdin, /dev/stdout, /dev/stderr三个文件上,来实现终端上的。
而linux中文件的重定向可以理解为可以不将0, 1, 2描述符链接到标准的输入输出{stdin,stdout,stderr}三兄弟,而是将其连接到其他位置上。
linux中的重定向简单的分为种
- 输出重定向,包含输出和错误输出
- 输入重定向
输出重定向分为两种:
- 覆盖输出(覆盖掉原来的内容)
- 追加输出(在原来的内容后面追加)
命令 > 文件名 # 覆盖输出
命令 >> 文件名 # 追加输出
复制比如123.txt文件内容为123
cat 123.txt > 456.txt
cat 456.txt
123
cat 123.txt > 456.txt
cat 456.txt
123
cat 123.txt >> 456.txt
cat 456.txt
123
123
复制cat命令可以读取文件内容,并将其标准输出到终端,此时文件符1软链至stdout
1->stdout复制
但是此时我们使用重定向符号,改变了文件符1的定向,在运行时相当于
1->456.txt复制
运行后文件符1重新软链到stdout。这就是输出重定向。
有时我们并不期望命令或可执行文件的标准输出,而是希望检测其运行状态,获取其退出时的错误输出,因此需要将错误输出重定向到文件。
错误输出重定向的语法如下:
命令 2> 文件名
命令 2>> 文件名 # 追加错误输出
# 也就是在标准输出符后面加上2,表示将错误输出重定向到文件
复制同时shell支持将错误输出与标准输出一同重定向到同一个文件,语法如下:
命令 &> 文件名复制
输入重定向也有两种
- 覆盖输入(覆盖掉原来的内容)
- 从标准输入读取内容,直到遇到结束符
命令 < 文件名 # 覆盖输入
命令 << 结束符 # 从标准输入读取内容,直到遇到结束符
复制给出一个shell文件 read.sh
read line
echo "读取到的行是:$line"
复制前面说过,read命令旨在从终端的标准输入中读取内容,并将其赋值给变量。
赋予read.sh权限后,运行如下命令
chmod +x read.sh
read.sh < 123.txt
读取到的行是:123
复制可以看到,read命令读取了123.txt文件的内容,并将其赋值给变量line。
与输出重定向类似,输入重定向会改变文件符0的定向。
在重定向前,文件符0软链至stdin
0->stdin复制
在重定向后,文件符0重新软链至123.txt
0->123.txt复制
因此,read命令不再从stdin中读取内容,而是从123.txt文件中读取内容。
还有一种用法就是从标准输入读取内容直到遇到结束符,并将其作为命令的输入。
cat << 结束符 # 从标准输入读取内容直到遇到结束符
复制比如
cat << EOF
hello
1
2
EOF
# 读取结束
# 输出到终端
hello
1
2
复制借助此种方法可以有这样的作用
cat << EOF > 123.txt
复制首先我们将输入重定向到直到遇到EOF才结束输入,然后将输出重定向到123.txt文件,这样就实现了检测关键字结束输入并将输入保存到指定文件。
错误输出重定向的语法用到的时候再去搜吧。
补充一个管道与输入重定向的错误区分。
# 假设存在a.txt且为空
echo "hello" >> a.txt
# 将echo的输出重定向到a.txt文件,并追加到文件末尾
echo "hello" | a.txt
# 管道运算符允许一个命令的输出作为另一个命令的输入,但是a.txt并没有接受输入的属性或语句,因此会报错
# 可以这样写
echo "hello" | cat >> a.txt
复制最后提一嘴,输入输出的重定向指的是将命令的标准输入输出重定向到文件,是命令与文件间的操作,因此不存在命令间的重定向,想要实现两个命令间的通信请使用管道。
命令展开是指将命令的输出作为参数传递给其他命令的一种方式。
其中常用的展开有下面几种
- 通配符展开
ls * # 实际上是将*展开为当前目录的所有文件名作为参数传递给ls命令
ls ~ # 实际上是将~展开为家目录的绝对路径作为参数传递给ls命令
# echo命令使用*会打印当前目录的所有文件,使用~会打印家目录的绝对路径
复制
- 算数表达式展开,
$((表达式))
echo $((3+5)) # 输出8
复制
- 变量展开,
$变量名
name="Ruby"
echo $name # 输出Ruby
# 变量的访问实际上也是一种展开
复制
- 花括号展开,
{字符1,字符2,字符3,...}
echo {a,b,c} # 输出a b c
# 使用花括号+字符串
echo alpha_{a,b,c}.txt # 输出alpha_a.txt alpha_b.txt alpha_c.txt
# 可以这样使用
touch alpha_{a,b,c}.txt # 创建三个文件,alpha_a.txt alpha_b.txt alpha_c.txt
# 同时花括号支持范围展开
echo {1..10} # 输出1 2 3 4 5 6 7 8 9 10
echo {A..Z} # 输出A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
# 实际上是在{字符1..字符2}的范围内使用Ascill码进行范围展开
# 结合这个用法可以批量创建连续文件
touch 2024-{1..12}.txt
# 创建了2024-1到2024-12的12个文件
复制
- 命令展开
echo `ls *`
echo `cat 123.txt`
# or
echo $(ls *)
echo $(cat 123.txt)
# 这种方法会将命令的输出展开为字符串,因此可以赋值操作
result=$(ls *) #or result=`ls *`
echo $result
复制
- 引号内展开
在shell中,单引号括起来的字符串相当于python中的原始字符串,只会原样输出引号内的字符,不会进行任何格式化操作。而使用双引号括起来的字符串则会进行变量展开、命令展开、算数表达式展开等操作。
name="Ruby"
echo 'Hello, $name!' # 输出Hello, $name!
echo "Hello, $name!" # 输出Hello, Ruby!
echo "`ls /root/a.txt`"
# or echo $(ls /root/a.txt)
# 输出/root/a.txt
# 在双引号中可以使用\对特殊字符进行转义
echo "Hello, \$name!" # 输出Hello, $name!
复制注意,无论单双引号,都不支持通配符以及花括号展开。因此类似于echo "ls *"会输出ls *而不是打印当前目录的所有文件。
如前面所见,shell脚本的扩展名一般设为.sh,即便不加此扩展名也可以执行,但是约定使用.sh来标识该本件为一个shell脚本文件。
几乎所有在命令行中能执行的shell命令都可以在shell脚本中使用。
给出一个简单的shell脚本,test.sh
脚本的第一行一般使用固定格式#!bin/bash即#!加脚本解释器的绝对路径来指定使用哪个解释器来执行脚本。
#!/bin/bash
echo "Hello,World!"
复制然后赋予执行权限并执行
chmod +x test.sh
# 这里有两种执行shell脚本的方法
# 1. 直接执行
./test.sh
# 2. 指定解释器执行
bash test.sh
# 输出
Hello,World!
复制第一种方法中,会根据脚本第一行指定的解释器来对脚本进行解释执行,而第二种方法则是无论指定解释器为何,都将使用bash解释器来执行脚本。
shell中的变量和python感觉差不多。
变量的定义为
# 变量名=变量值, 如
name="RubyRose"
# 变量名的规范与大多语言相同
# 注意变量名与变量值间的等于号不能有空格
复制通常使用全大写的变量来表示一个常量,如
PI=3.141592653589793复制
想要使用echo输出变量值到终端,只需在变量名前加$符号
echo $name
# 若不加$,echo会默认将所有输入作为字符串输出
echo name
# 输出name
复制同时可以直接对变量名重新赋值来更改其值
name="Ruby"
复制对于变量有几个关键字
# readonly用来指定一个变量是只读不可改的,仅在声明时赋一次值
readonly name
name="else" # 这里会报错,因为name已经被声明为只读不可改
# unset用来删除一个变量,或者说来重置一个变量,变量的值会变为空
unset name
echo $name # 输出为空
复制值得注意的是,在赋值时,不加引号也会默认值为字符串值
alpha=rose
# 等价于
alpha="rose"
复制也就是说,shell中默认的变量类型为字符串。
在shell的打印输出(echo)中,会遇到一些格式化字符串的需求
name=Ruby
# 1. 字符串拼接,使用双引号
echo "Hello, $name!"
# 输出Hello, Ruby!
# 有时会有这样的需求
echo "Hello, $nameBBB"
# 此时变量名与字符串重合,而我们并没有定义nameBBB变量,输出空。
# 因此可以使用{}包裹变量名来解决这个问题
echo "Hello, ${name}BBB"
# 2. 原始字符串,使用单引号
echo 'Hello, $name!'
# 输出Hello, $name!,相当于python中的r"name"
# 3. 获取字符串长度
echo ${#name}
# 输出4
复制shell中变量类型有三种
3.2节中已经讲过,shell中的变量默认为字符串类型,也就是说在不使用关键字指定的前提下,无法进行数值运算。
num1=10
num2=20
sum=$num1+$num2
echo $sum
# 输出字符串10+20
复制因此在声明一些变量时,可以使用delcare关键字来指定变量的类型。
使用时的语法如下
declare [+/-] [变换属性] 变量名
# - 表示为变量增加属性
# + 表示为变量删除属性
# 变换属性有如下几种
# -i 整型
# -l 小写字母
# -u 大写字母
# -a 数组类型
# -A 关联数组类型(HashMap)
# -x 环境变量
# -r 只读变量
# -g 全局变量,shell中不加指定也默认为全局变量
# -p 显示变量类型
复制一些演示例子如下
- 声明整型变量
declare -i num=10
declare -i num_=20
declare -i sum=$num+$num_
echo $sum # 输出30
复制值得一提的是,shell会将赋值尽量的转换到赋值对象所需要的类型,因此对于一个已经声明的整型变量,允许如下操作。
declare -i num
str1=10
str2=20 # 记得吗,str1和str2默认为字符串
num=$str1+$str2
echo $num # 输出30
复制同理也有
declare -i num=10
declare -i num_=10
str=$num+$num_ # str默认字符串,因此整型转换到字符串进行字符串拼接
echo $str # 输出10+10
复制
- 声明大小写字母变量
declare -l Lowname=RUBY
declare -u Upname=ruby
echo $Lowname # 输出ruby
echo $Upname # 输出RUBY
复制shell会将赋值的字符串根据变量声明时的属性来仅保留大写或者小写
- 声明数组以及关联数组
数组也是shell中的一种基本类型,其可以使用declare -a来声明,亦可以直接声明,访问其元素与正常数组类似。
# 元素用小括号包裹,用空格分隔
declare -a arr=(1 2 3 4 5)
# or
arr=(1 2 3 4 5)
# or 直接声明
arr[0]=1 # 这里直接声明了一个数组,只有一个元素1
# 访问元素
echo $arr # 数组名指向第一个元素,输出1
echo ${arr[2]} # 输出1
echo ${arr[@]} or echo ${arr[*]} # 输出1 2 3 4 5
# 数组长度
echo ${#arr[@]} # 输出5,语法与输出字符串长度类似
# 添加元素
arr[5]=6 # 直接从最后一个元素的后面的索引赋值即可添加
echo ${arr[*]} # 输出1 2 3 4 5 6
# or
arr+=(6 7 8) # 也可以使用+=来添加元素或者一段数组
echo ${arr[*]} # 输出1 2 3 4 5 6 6 7 8
# 数组拼接
arr1=(1 2 3)
arr2=(4 5 6)
arr3=(${arr1[*]} ${arr2[*]}) # 注意有空格
echo ${arr3[*]} # 输出1 2 3 4 5 6
复制关于关联数组,shell中没有直接的声明方式,需要使用declare -A来声明,其用法与python中的Dict类似,赋值时以[键]=值的方式进行。
# 元素用小括号包裹,用空格分隔
declare -A arr=([id1]=11 [id2]=12 [id3]=13)
# or
declare -A arr
arr[id1]=11
arr[id2]=12
arr[id3]=13
# 即关联数组支持声明后直接使用键值对来添加元素,对于已经存在的键,会覆盖原值,对于不存在的键,会新增键值对。
# 访问元素
echo ${arr[id1]} # 输出11
echo ${arr[@]} or echo ${arr[*]} # 输出11 12 13,即只会输出值
# 想要遍历输出关联数组的键,可以加`!`
echo ${!arr[*]} # 输出id1 id2 id3
# 关联数组长度
echo ${#arr[@]} # 输出3
复制
- 声明环境变量
declare -x MYENV=123
echo $MYENV # 输出123
printenv MYENV # 输出123,说明确实导出到了环境变量
复制
- 声明只读变量
declare -r name=ruby
# 等价于 readonly name=ruby
name=else # 报错,不可修改
复制
- 显示变量类型
declare -p [...变量名] # 输出变量类型,可跟多个变量名
复制可以通过组合使用这些关键字来声明各种变量类型。
declare -ai arr=(1 2 3)
# or
declare -a -i arr=(1 2 3)
# 声明一个整型数组arr
arr[0]+=1
echo ${arr[0]} # 输出2
复制上述的声明后的变量可以使用+[属性]来取消其属性。
declare -l Lowname
Lowname=RUBY
echo $Lowname # 输出ruby
declare +l Lowname # 取消小写字母属性
Lowname=BIG
echo $Lowname # 输出BIG,属性失效
复制但是注意,+r选项并不能取消变量的只读属性,对一个只读变量使用+r选项会报错。
也可以使用typeset命令来声明变量类型,其语法与declare基本一致。
因为shell中变量类型默认为字符串,因此无法直接进行数值运算。
a=10
b=20
sum=$a+$b
echo $sum # 输出字符串10+20,而非30
复制shell中提供了一些命令来进行数值运算。
在此之前,简单了解一下内建命令与外部命令的区别。
- 内建命令是在编译时与shell一起编译生成可执行文件的命令,自身已集成在shell内部,不需要访问外部的可执行文件来执行。
- 外部命令则是指需要调用外部可执行文件来执行的命令,如ls、cp、mv等。
可以通过type命令来查看某个命令是否为内建命令,而且使用which命令来查看内建命令时,一般找不到其路径,因为已经集成在shell内部。
type mv
mv 是 /usr/bin/mv # 说明mv是外部命令
which mv
/usr/bin/mv
type cd
cd 是 shell 内建
which cd
# 输出空,内建命令找不到路径
复制下面开始介绍常用的算数运算命令。
# 使用$((...))来包裹算数表达式
result=$((10+20))
echo $result # 输出30
#or
num1=10
num2=20
result=$(($num1*$num2))
echo $result # 输出200
#支持整数加(+),减(-),乘(*),除(/),乘方(**),取模(%)运算
#也支持位运算如左移(<<)、右移(>>)、按位与(&)、按位或(|)、按位异或(^)、逻辑非(~)
复制仅可以实现整数运算,非整除会截断为整数。
# expr命令可以进行算数运算,其语法如下
expr [数] [运算符] [数]
# 其中数字和运算符各作为参数传入,需要用空格分隔。
# such as
expr 10 + 20 # 输出30
expr 10 / 20 # 输出0,因为除法运算结果为浮点数
expr 5 * 2 # 报错,因为*号是shell中的特殊字符,可以使用转义字符\来表示
expr 5 \* 2 # 输出10,因为\*表示*号本身
# 也可以赋值给变量
sum = $(expr 10 + 20)
# or
sun = `expr 10 + 20`
echo $sum # 输出30
# 注意,expr实现的运算仅有+-*/%
复制bcbc复制
会出现以下

可以看出bc是linux中的一个可执行程序,用来进行算术运算。
其中支持加(+)减(-)乘(*)除(/)乘方(^)以及取非(!)运算。
但是仅可以执行表达式,不能直接赋值给变量。
1+2
3
5^2
25
!0
1
!5
0
quit # 输入quit退出bc
复制上面的方法仅支持整数运算。想要进行浮点数运算,可以使用-l选项来实现。
bc -l复制
然后就可以使用浮点数运算了。
6 / 4
1.50000000000000000000
quit
# 小数位有点多,可以直接在bc中使用scale命令来指定小数位数,直接截断,非四舍五入
bc -l
2/3
.666666666666666666666
scale=2 # 指定小数位数为2
2/3
.66
quit
复制在浮点数运算模式下bc提供了一些函数计算
s(x) 计算 sin(x),以下x皆为弧度表示
c(x) 计算 cos(x)
a(x) 计算arctangent(x)
l(x) 计算ln(x)
e(x) 计算e的x次方,其中e为自然底数
x^y 计算x的y次方
sqrt(x) 计算根号下x
# 直接传入即可
复制可以看见bc执行后默认由标准输入读取表达式然后将结果到标准输出,因此可以使用管道向其输入表达式。
echo '1+2' | bc # 输出3
echo '6/4' | bc -l # 输出1.5000000000
# 多条命令使用分号;隔开
echo '1+2;2/3' | bc -l
3.0000000000
.66666666666
# 使用这个方法可以指定小数位数
echo 'scale=2;2/3' | bc -l
.66
# 在使用一些重定向就可以实现使用bc赋值
echo '1+2' | bc >> a.txt
# 将bc的输出重定向到a.txt文件末尾
# 也可以将bc的输出赋值给变量
result=$(echo '1+2' | bc)
# or
result=`echo '1+2' | bc`
复制 可以看到使用$([命令/命令表达式])or` [表达式] `的方法来将命令的输出赋值给变量。
# 使用let来进行数值运算
num1=10
num2=20
let sum=$num1+$num2
echo $sum # 输出30
# let 支持省略$来进行数值运算,则上述等同
let sum=num1+num2
echo $sum # 输出30
复制let支持加(+)减(-)乘(*)除(/)乘方(**)取模(%)运算
不支持位运算。
支持+=,-=等类似运算,支持自增自减运算。
num=0
let num++ # 自增
echo $num # 输出1
let num-- # 自减
echo $num # 输出0
let num+=10 # 加法赋值
echo $num # 输出10
复制# 对于并非使用let声明的变量,也可以使用let来进行数值运算
num=10
let num+=10
echo $num # 输出20
# 对于非数字的变量,let默认其值为0
alpha="b"
let alpha++ # 自增
echo $alpha # 输出1
alpha="b"
let alpha+=10
echo $alpha # 输出10
复制在shell中,每条命令执行完毕后,都会返回一个退出状态(exit status)码,用来表示命令执行成功与否。其取值范围为0-255,0表示成功,非0表示失败,因此在使用退出状态码时大部分时间仅需要关注0与非0即可。
当执行完命令后,可以通过echo $?来打印出上一条命令的退出状态码。
ls a.txt # a.txt存在
echo $? # 输出0
ls b.txt # b.txt不存在
echo $? # 输出1
复制注意的是,与大多数语言不同,shell中表示成功的退出状态码为0(true),表示失败的退出状态码为非0(false)。
在编写shell脚本时,执行脚本后的退出状态码默认为脚本最后一个语句的退出状态码。
#!/bin/bash
ls a.txt
ls b.txt
复制此脚本执行后,如果b.txt不存在,则退出状态码为1,否则为0。
当然,我们也可以通过exit命令来指定退出状态码。
#!/bin/bash
ls a.txt
exit 0 # 表示成功
复制这样不论a.txt是否存在,脚本都会返回0作为退出状态码。0可以换成其他数字。
需要注意的是,exit后的语句不会执行,脚本执行到exit即结束。
test命令是一个用于条件判断的命令,其语法如下
test [表达式] -[选项] [表达式]
# or
test -[选项] [表达式]
复制其中选项有如下(真的很多)
# 数值比较,左边相对于右边
-eq #等于则为真(equal)
-ne #不等于则为真(not equal)
-gt #大于则为真(greater than)
-ge #大于等于则为真(greater than or equal)
-lt #小于则为真(less than)
-le #小于等于则为真(less than or equal)
# such as
test 10 -eq 10 # 该语句的状态码为0
复制# 字符串比较,左边在右边中出现则为真
= #等于则为真
!= #不相等则为真
-z 字符串 #字符串的长度为零则为真
-n 字符串 #字符串的长度不为零则为真
# such as
test "abc" = "abc" # 该语句的状态码为0
name=Ruby
test -z "$name" # 该语句的状态码为0,因为name的长度为3
test -n "$name" # 该语句的状态码为0,因为name的长度不为0
# 这里建议将字符串用双引号括起来,防止空变量名的情况发生。
如
test -n $non # 由于non变量为空,相当于test -z ,而该语句的状态码为0,因此本该输出0,实际输出1。
复制# 文件测试,文件测试命令用于测试文件是否存在、是否可读、是否可写、是否可执行等。
-e 文件名 #如果文件存在则为真
-r 文件名 #如果文件存在且可读则为真
-w 文件名 #如果文件存在且可写则为真
-x 文件名 #如果文件存在且可执行则为真
-s 文件名 #如果文件存在且至少有一个字符则为真
-d 文件名 #如果文件存在且为目录则为真
-f 文件名 #如果文件存在且为普通文件则为真
-c 文件名 #如果文件存在且为字符型特殊文件则为真
-b 文件名 #如果文件存在且为块特殊文件则为真
# such as
# 假设a.txt存在且可读
test -e a.txt # 该语句的状态码为0,因为a.txt存在
test -r a.txt # 该语句的状态码为0,因为a.txt存在且可读
复制上述这些选项前可以将
!作为参数传入来对其逻辑取反,即本来
test ! -e a.txt # 此时若a.txt存在,则该语句的状态码为1,否则为0
#等价与[ ! -e a.txt ]
test "abc" != "abc" # 状态码为1,因为"abc"等于"abc",只有不相等时才为真,状态吗为0。
复制这些选项之后用到再来查阅即可,太多了不可能一下记住。
当然shell提供了一种关于test更简单的写法
[ [表达式] -[选项] [表达式] ]
# or
[ -[选项] [表达式] ]
# 注意中括号与语句间均有一个空格
# such as
[ "abs" = "abs" ]
[ -z "$name" ]
复制与C++以及Python等语言类似,shell提供了一些逻辑运算符来进行条件判断,包括逻辑与(&&)、逻辑或(||)以及逻辑非(!)。
在了解shell中的逻辑运算符前,先了解两个shell中的内建命令true和false。
true # 该命令的退出状态码恒为0
false # 该命令的退出状态码恒为非0
复制[表达式] && [表达式]
# or
[ [表达式] -a [表达式] ] # -a = and
复制该运算符用于判断两个表达式是否都为真,如果两个表达式的退出状态码都为0,则返回退出状态码为0,否则返回退出状态码为1,相应的,也会有逻辑短路的现象。
[ "abc" = "def" -a touch yes.txt ]
# 等价与 [ "abc" = "def" ] && touch yes.txt
# 显然字符串abc不等于def,因此无论后面是什么,都会返回1,同时后面的表达式也不会被执行,因此不会创建yes.txt文件。
复制[表达式] || [表达式]
# or
[ [表达式] -o [表达式] ] # -o = or
复制该运算符用于判断两个表达式是否至少有一个为真,如果两个表达式的退出状态码有一个为0,则返回退出状态码为0,否则返回退出状态码为1,相应的,也会有逻辑短路的现象。
[ "abc" = "abc" -o touch yes.txt ]
# 等价与 [ "abc" = "abc" ] || touch yes.txt
# 显然字符串abc等于abc,无论后面是什么,都会返回0,因此后面的表达式touch yes.txt不会被执行,不会创建yes.txt文件。
复制! [表达式]
# or
[ ! [表达式] ]
[ [表达式] ! -[选项] [表达式]]
复制该运算符用于对表达式取反,如果表达式的退出状态码为0,则返回退出状态码为1,否则返回退出状态码为0。
[! -e a.txt ]
# 等价与 -e a.txt 为假,即a.txt不存在,则返回0,否则返回1。
!ls a.txr
# 若a.txt存在,则返回1,否则返回0。
[ "abc" != "abc" ]
# 显然abc等于abc,!=不成立,因此返回1。
复制通过上述的逻辑运算符,我们可以写出一些复杂的条件判断语句,应用其短路特性达到if-else的效果。
[ -e a.txt ] && rm a.txt
# 若a.txt存在,则删除a.txt,否则什么都不做。
[ ! -e a.txt ] && touch a.txt
# 若a.txt不存在,则创建a.txt,否则什么都不做。
复制在考虑这几个运算符间的优先级时,直接用小括号最省脑子。
shell中提供if-else来实现条件语句,当条件为真(退出状态码为0)时执行if块中的命令,否则执行else块中的命令。
其语法如下
最简单的if-else语句如下
if [条件]
then
# 条件为真时执行的代码
fi # 结束if语句
# shell中可以使用;来在一行分割命令,那么上面可以这样写
if [条件]; then echo "条件为真"; fi
复制带有else的if-else语句如下
if [条件]
then
# 条件判断1为真时执行的代码
else
# 条件判断1为假时执行的代码
fi # 结束if语句
复制或者带有elif的if-else语句如下
if [条件1]
then
# 条件判断1为真时执行的代码
elif [条件2]
then
# 条件判断2为真时执行的代码
else
# 条件判断1和2都为假时执行的代码
fi # 结束if语句
复制多层嵌套的if-else使用缩进区分
if [条件1]
then
if [条件2]
then
# 条件判断2为真时执行的代码
fi
else
if [条件3]
then
# 条件判断3为真时执行的代码
fi
fi # 结束if语句
复制注意这里的条件为条件块,即使用如下
if [ 5 -gt 3 ]
echo "5大于3"
else
echo "5不大于3"
fi
# 可以组合逻辑运算符
num=10
if [ $num -gt 3 -a $num -lt 15 ]
echo "num大于3且小于15"
else
echo "num不大于3或大于15"
fi
上面等价与
if [ $num -gt 3 ] && [ $num -lt 15 ]
echo "num大于3且小于15"
else
echo "num不大于3或大于15"
fi
复制对于一些复杂的条件判断,可以使用逻辑运算符的短路特性来简化代码,这里就不举例子了。
case语句类似与C++中的switch语句,用于多分支条件判断。
case 变量 in
值1)
# 变量等于值1时执行的代码
;;
值2)
# 变量等于值2时执行的代码
;;
*)
# 变量不等于值1或2时执行的代码
esac
复制即对于每种模式,我们使用值)来充当类型case,然后使用;;来表示该模式结束。由于shell中没有default关键字,因此使用通配符*来匹配所有其他情况,最后使用esac来结束case语句。
很有意思的是,if-else和case语句的结束符都是其反写,即fi和esac。
这里提一嘴,shell中的匹配与正则表达式几乎一致。
case语句也支持使用|来用一种模式匹配多个情况。
read -p "请输入数字:" num # read的-p选项用于提示用户输入
case $num in
1|2|3)
echo "你输入的数字是1、2、3中的一个"
;;
4|5|6)
echo "你输入的数字是4、5、6中的一个"
;;
*)
echo "你输入的数字不是1、2、3、4、5、6中的任何一个"
esac
复制同时可以使用正则表达式来匹配
read -p "请输入::" str
case $str in
[0-9]*)
echo "你输入的是数字"
;;
[a-zA-Z]*)
echo "你输入的是字母"
;;
*)
echo "你输入的不是数字也不是字母"
esac
复制shell中提供了两种for的写法,一种是类似python的迭代for,一种是类似C语言条件for。
迭代for的语法如下
for 变量 in 值1 值2 值3...
do
# 循环体
done
# 值1,2,3...也可为可迭代对象或者其他使用空格或者tab分隔的值,亦可以使用一些展开的语法来实现。
# such as
for i in 1 2 5
do
echo $i
done
# 输出1 2 5
for i in *
do
echo "$i"
done
# 打印当前目录下所有文件名
for i in {1..10}
do
echo $i
done
# 打印1到10
复制条件for的语法如下
for (( 初始值; 条件; 步进值 ))
do
# 循环体
done
# 初始值,条件,步进值均为数字,亦可使用一些变量来代替,注意使用双层小括号。
# such as
for ((i=1; i<=10; i++))
do
echo $i
done
# 输出1 2 3 4 5 6 7 8 9 10
复制也可以用来访问数组或者关联数组
arr=(1 2 3 4 5)
for val in ${arr[*]}
do
echo $val
done
# 输出1 2 3 4 5
declare -A assoc_arr
assoc_arr[key1]=value1
assoc_arr[key2]=value2
for key in ${!assoc_arr[@]}
do
echo $key : ${assoc_arr[$key]}
done
# 输出key1 : value1 key2 : value2
复制shell中提供了while和until循环,用于循环执行一段代码,直到条件为真或假。
其中while循环和until循环可以认为是两个相反的例子,while循环仅有表达式的退出状态码为0时(即为真或者说执行成功)去执行循环体,而until循环则是表达式的退出状态码为0时(即为真或者说执行成功)退出执行。
while [ 条件 ]
do
# 循环体
done
until [ 条件 ]
do
# 循环体
done
# such as
let cnt=0
while [ $cnt -le 5 ] # 循环条件为cnt小于等于5
do
echo $cnt
let cnt++
done
# 输出0 1 2 3 4 5
let cnt=0
until [ $cnt -ge 5 ] # 退出循环条件为cnt大于等于5
do
echo $cnt
let cnt++
done
# 输出0 1 2 3 4 5
复制shell提供了向c/c++中类似的break和continue语句,用于控制循环的执行。
break用于跳出当前循环,continue用于跳过当前循环的剩余语句,并开始下一次循环。
let cnt=0
while [ $cnt -le 5]
do
echo $cnt
let cnt++
if [ $cnt -eq 3 ] # 若cnt等于3
then
break # 跳出当前循环
fi
done
# 输出0 1 2
# 上面的if-else语句可以使用逻辑短路来简化
[ $cnt -eq 3 ] && break
# contine用于跳过当前循环的剩余语句,并开始下一次循环
let cnt=0
while [ $cnt -le 5 ]
do
let cnt++
[ $cnt -eq 3 ] && continue # 若cnt等于3,则跳过当前循环的剩余语句,并开始下一次循环
echo $cnt
done
# 输出0 1 2 4 5
复制类似于ls a.txt,ls实际上也是一个可执行程序,我们向其中传入了a.txt作为参数。
在自己编写的shell中,我们可以使用$n来表示传递给脚本或函数的参数,其中n为参数的位置,从0开始。
# t.sh
#!/bin/bash
echo "第一个参数为:$1"
echo "第二个参数为:$2"
echo "第三个参数为:$3"
chmod +x t.sh # 使脚本可执行
./t.sh a b c # 执行脚本,并传入参数a,b,c
# 输出
# 第一个参数为:a
# 第二个参数为:b
# 第三个参数为:c
复制其中还有一些特殊符号
$0 运行脚本时提供的路径
$# 传递给脚本或函数的参数个数
$@ 传递给脚本或函数的所有参数
复制# t.sh
#!/bin/bash
for i in $@
do
echo $i
done
# 输出所有参数
./t.sh "hello world" 123
# 输出
# hello
# world
# 123
# 这是由于hello world虽然是一个参数,但是未加双引号的情况下参数会依据空白字符重新分割。因此需要使用双引号将$@括起来。
for i in "$@"
do
echo $i
done
# 输出所有参数
./t.sh "hello world" 123
# 输出
# hello world
# 123
# "$@"会将每个参数使用双引号括起来,因此不会出现空格被遍历出来。
复制shell中提供了函数的概念,可以将一系列命令封装成一个函数,然后在其他地方调用。
函数的写法有三种
# 第一种,使用function关键字来定义函数,同时函数名后面加上()
function 函数名() {
# 函数体
}
# 第二种,省略function关键字,直接使用函数名加()
函数名() {
# 函数体
}
# 第三种,使用关键字function来定义函数,省略函数名后的()
function 函数名{
# 函数体
}
# 这三种写法的花括号都可以另起一行
func()
{
echo "Hello, World!"
}
# 调用函数直接使用函数名即可
func
# 输出
# Hello, World!
复制shell中的函数也可以传参和使用返回值来传递数据。
其中传参的写法与向脚本传参的形式类似,而非像其他语言中在小括号中先声明参数。
func()
{
echo "第一个参数为:$1" # 使用$n的形式获取第n个参数
echo "第二个参数为:$2"
echo "第三个参数为:$3"
echo "所有参数为:$#" # 使用$#获取参数个数
for i in "$@" # 使用@或*的形式获取所有参数
do
echo $i
done
}
复制而函数的返回值可以通过return关键字来实现,执行完函数后使用$?来获取函数的退出状态码,即其返回值。
func()
{
let sum=0
for num in "$@"
do
let sum=sum+num
done
return $sum # 返回函数的返回值
}
func {1..5}
echo "函数的返回值为:$?" # 输出函数的返回值
# 输出
# 函数的返回值为:15
复制但是使用return仅能返回一个int值,因为本质上执行函数就是执行一个封装好的命令,返回实际上是返回了一个退出状态码,范围在0-255之间。因此大于255的返回值会溢出。
由于函数类似于命令,因此可以使用命令的展开来实现任意无限制的返回值。
func()
{
let sum=0
for num in "$@"
do
let sum=sum+num
done
echo "$sum"
}
res=`func {1..100}`
#or
res=$(func {1..100})
echo "函数的返回值为:$res"
# 输出
# 函数的返回值为:5050
复制使用这种方法的返回可以不限制返回值的类型。
函数中的变量作用域默认是全局的,可以通过local关键字来声明局部变量。
而使用命令展开获取返回值时,即使不使用local声明,也无法修改和访问函数内部的变量。
grep命令是linux中非常常用的命令,用于在指定文本中查找能够匹配上模式的行。模式可以是字符串,亦可以是正则表达式。匹配时区分大小写。
grep [选项] [模式] [文件]
其中常用的选项有
-i:忽略大小写进行匹配。
-v:反向查找,只打印不匹配的行。
-n:显示匹配行的行号。
-r:递归查找子目录中的文件。
-l:只打印匹配的文件名。
-c:只打印匹配的行数。
-w:匹配整个单词。
-q:静默模式,不打印任何信息。可以通过退出状态来判断是否匹配到。
-B 数字 :打印匹配行之前的n行
-A 数字 :打印匹配行之后的n行
-C 数字 :打印匹配行前后各n行
# 当grep匹配到行时,退出状态码为0,否则为1。
# 匹配到多个行时,会将所有匹配的行打印出来。
复制a.txt
cat1
cat2
cat3
cat4
grep "cat" a.txt
# 输出
# cat1
# cat2
# cat3
# cat4
echo "$?" # 输出0
grep "dog" a.txt
echo "$?" # 输出1
grep -w "cat" a.txt # 匹配整个单词
echo "$?" # 输出1
复制使用管道可以结合其他命令的输出来使用grep
cat a.txt | grep "cat"
# 作用与 grep "cat" a.txt 相同,这里使用管道将cat的输出作为grep的输入
ls * | grep *.txt
# 找到当前目录下所有以.txt结尾的文件名
复制